【Treeman】Java相關
- Java
- 【反射】動態執行某類別方法
- 【反射】java 如何取得目前程式碼所在的 function name
- 方法寫入外部物件
- 安裝OpenJDK
- 泛型相關
- 時間相關
- Collection 相關
- final 相關
- Java 版本相關
- Maven相關
- Optional 相關
- Stream API
- Tomcat伺服器詳解
- Bean 與 Pojo
- 【Java】自Java 1.6版本以来的主要新增功能
- 【SDKMAN】安裝管理JAVA
- SpringBoot
- 【IDE】STS(Stping Tool Suite) 相關
- 【SpringBoot】 annotation
- 【SpringBoot】@Scheduled 定時執行
- 【SpringBoot】 監控工具 Actuator
- 【SpringBoot】 開啟tomcat log
- 【SpringBoot】相關資源
- 【SpringBoot】Redis
- 【SpringBoot】cors
- 【SpringBoot】java 啟動參數
- property use list
- 【SpingBoot】取得git branch
- Kotlin
- 【Kotlin】data class
- 【Kotlin】getter, setter
- 【Kotlin】enum class
- 【Kotlin】【Test】建立臨時單一執行class
- 【Kotlin】sealed class
- 【Kotlin】seale class 與 enum 的比較
- 【Kotlin】Scope functions ( run , let, apply, also, let, takeIf and takeUnless)
- 【kotlin】Inline functions (官方文件翻譯)
- 【kotlin】因為需要 < reified T> 取得泛型型別,所以從 inline functions 開始
- 【Kotlin】Pair
- 【Kotlin】Collections (官方文件)
- 【Kotlin】Collection
- 【Kotlin】集合 Iterable/Collection/List/Set/Map
- 【Kotlin】Sequence
- 【Kotlin】Gson 使用指南
- 【Kotlin】Serialization Chapter 5. JSON Features
- 【kotlin】Serialization
- 【kotlin】Serialization CH1-CH4
- 【Kotlin】Serialization CH5. JSON Features
- 【Kotlin】Gson 使用指南
- 【Kotlin】kotlinx.serialization Vs Gson
- 【Kotlin】【Test】建立臨時單一執行class
- 【IDE】【IntelliJ】
- 監控與效能調校
- Util
- JVM
Java
【反射】動態執行某類別方法
@PostMapping(value = "/test/getApi/{className}",consumes = MediaType.ALL_VALUE)
public ResponseEntity<?> getApi(
@PathVariable String className,
@RequestBody HashMap<String ,Object> param
) throws Exception{
HttpStatus status = HttpStatus.OK;
Object res = null;
HashMap classMap = new HashMap<String,String>();
// 對應完整class
classMap.put("TencentStreamingAPI","com.test.api.TencentStreamingAPI");
String fullClassName = (String)classMap.get(className);
String func = "";
try {
if(fullClassName == null) throw new Exception("no className mapping fullClassName");
if((String)param.get("func") != null){
func = (String)param.get("func");
}else{
throw new Exception("no func name");
}
Class c = Class.forName(fullClassName);
Object ts = c.newInstance();
switch (className){
case "TencentStreamingAPI":
ts = tencentStreamingAPI;
c = ts.getClass();
break;
case "TencentIMAPI":
ts = tencentIMAPI;
c = ts.getClass();
break;
}
Method[] methods = c.getMethods();
for (Method method : methods) {
if (method.getName().equals(func)) {
if (method.getParameters().length == 0) {
Method m = c.getMethod(func, null);
res = m.invoke(ts, null);
} else {
ArrayList<Class<?>> parameterTypesList = new ArrayList<Class<?>>();
ArrayList<Object> argsList = new ArrayList<Object>();
for(Parameter parameter : method.getParameters() ){
String prarameterName = parameter.getName();
Class clazz = parameter.getType();
Object arg = param.get(prarameterName);
if(arg == null) throw new Exception("no such prarameter: "+ prarameterName);
parameterTypesList.add(clazz);
argsList.add(arg);
}
// Method m = c.getMethod(func, String.class);
Method m = c.getMethod(func, parameterTypesList.toArray(new Class[parameterTypesList.size()]));
res = m.invoke(ts, argsList.toArray(new Object[argsList.size()]));
}
break;
}
}
} catch (ClassNotFoundException e) {
logger.error(e.getMessage());
throw new Exception("no such class: " + className);
} catch (NoSuchMethodException e) {
logger.error(e.getMessage());
throw new Exception("no such metod:" + func);
} catch (IllegalArgumentException e) {
logger.error(e.getMessage());
throw new Exception("illegal argument :" + func);
} catch (Exception e) {
//取得目前執行方法名稱
String methodName = "[noGetMethodName]";
Method method = this.getClass().getEnclosingMethod();
if(method != null){
methodName = method.getName();
}else{
StackTraceElement[] stackTrace = Thread.currentThread().getStackTrace();
for (StackTraceElement stackTraceElement : stackTrace) {
methodName = stackTraceElement.getMethodName();
if (!methodName.equals("getStackTrace") &&
!methodName.equals("getMethodName") &&
!methodName.equals("main")) {
break;
}
}
}
logger.error(this.getClass().toString()+" -> "+
methodName + ": " + e.getMessage());
status = HttpStatus.FORBIDDEN;
}
HttpHeaders headers = new HttpHeaders();
headers.setContentType(MediaType.APPLICATION_JSON);
String resultStr = "{}";
if(res instanceof JSONObject){
resultStr = ((JSONObject) res).toString();
}else if(res instanceof JSONArray){
resultStr = ((JSONArray) res).toString();
}else if(res instanceof String){
resultStr = (String) res;
}
// logger.debug("func name is {}",func);
// logger.debug("func res type is {}",res.getClass().getName());
return new ResponseEntity<>(resultStr, headers, status);
}public class TencentStreamingAPI {
public JSONObject describeStreamPlayInfoList(String streamId,String starttime, String endtime){
.....
}
}// 呼叫
http://localhost:8080/api/test/getApi/TencentStreamingAPI
/** json 參數
func: 執行方法名稱
其他帶入同名參數
*/
{
"func": "describeStreamPlayInfoList",
"streamId": "AABBCCDD",
"starttime": "2023-03-29 13:18:00",
"endtime": "2023-03-29 13:18:00"
}
【反射】java 如何取得目前程式碼所在的 function name
public class MyClass {
public static void main(String[] args) {
String methodName = new Object() {}
.getClass()
.getEnclosingMethod()
.getName();
System.out.println("目前所在的方法名稱為:" + methodName);
}
}
這段程式碼使用了匿名內部類別的方式來取得目前所在的方法名稱。在這個匿名內部類別中,呼叫 getClass() 方法可以取得目前物件的類別,接著呼叫 getEnclosingMethod() 方法可以取得該物件所在的方法,最後呼叫 getName() 方法可以取得該方法的名稱。
需要注意的是,由於這個方法使用了匿名內部類別,所以每次呼叫都會產生一個新的物件,可能會對效能造成一些影響。
如果 getEnclosingMethod() 方法回傳 null,表示目前的程式碼不是定義在一個方法裡面,而是定義在類別的初始化區塊(initializer block)或建構子(constructor)中,或者是在類別的靜態初始化區塊(static initializer block)或靜態建構子(static constructor)中。
在這種情況下,可以使用 Thread.currentThread().getStackTrace() 方法來取得當前執行緒的呼叫堆疊(call stack),然後從呼叫堆疊中找到第一個方法的名稱,這個方法的名稱就是目前所在的方法名稱。
以下是一個示範程式碼,可以在這種情況下取得目前所在的方法名稱:
public class MyClass {
public MyClass() {
String methodName = getMethodName();
System.out.println("目前所在的方法名稱為:" + methodName);
}
static {
String methodName = getMethodName();
System.out.println("目前所在的方法名稱為:" + methodName);
}
{
String methodName = getMethodName();
System.out.println("目前所在的方法名稱為:" + methodName);
}
public static void main(String[] args) {
String methodName = getMethodName();
System.out.println("目前所在的方法名稱為:" + methodName);
}
private static String getMethodName() {
StackTraceElement[] stackTrace = Thread.currentThread().getStackTrace();
for (StackTraceElement stackTraceElement : stackTrace) {
String methodName = stackTraceElement.getMethodName();
if (!methodName.equals("getStackTrace") &&
!methodName.equals("getMethodName") &&
!methodName.equals("main")) {
return methodName;
}
}
return null;
}
}
這個程式碼定義了幾個方法和初始化區塊,在每個區塊中都呼叫了 getMethodName() 方法來取得目前所在的方法名稱。在 getMethodName() 方法中,首先取得目前執行緒的呼叫堆疊,然後從呼叫堆疊中找到第一個不是 getStackTrace()、getMethodName() 或 main() 的方法名稱,這個方法的名稱就是目前所在的方法名稱。
方法寫入外部物件
在 Java 中,方法参数的传递方式是按值传递,也就是说,方法内部对参数的修改不会影响到原始变量的值。因此,在 Java 中无法直接通过方法回写外部变量。
不过,可以通过一些技巧来实现类似于按引用传递的效果。其中一种方法是将要回写的变量封装成一个对象,并将该对象作为方法的参数传递进去。这样,方法内部对该对象的修改会影响到原始变量的值。
例如,假设有一个要回写的变量 int x,可以将其封装成一个对象 IntHolder,该对象包含一个整数属性 value,并提供一个方法 getValue() 和 setValue(int) 分别用于获取和设置该属性的值。然后,在调用方法时,将一个 IntHolder 对象作为参数传递进去。方法内部就可以通过 IntHolder 对象来修改原始变量的值。
下面是一个示例代码:
public class IntHolder {
private int value;
public IntHolder(int value) {
this.value = value;
}
public int getValue() {
return value;
}
public void setValue(int value) {
this.value = value;
}
}
public class Main {
public static void main(String[] args) {
IntHolder xHolder = new IntHolder(10);
System.out.println("Before method call: " + xHolder.getValue());
// 调用方法,将 xHolder 作为参数传递进去
modifyIntHolder(xHolder);
System.out.println("After method call: " + xHolder.getValue());
}
public static void modifyIntHolder(IntHolder holder) {
// 修改 holder 的值,会影响到 xHolder
holder.setValue(20);
}
}
在上面的示例代码中,IntHolder 对象 xHolder 的值被初始化为 10,然后被传递给 modifyIntHolder 方法。在方法内部,holder 对象的值被修改为 20。由于 xHolder 和 holder 引用的是同一个对象,因此 xHolder 的值也被修改为 20。最终输出结果为:
Before method call: 10
After method call: 20
安裝OpenJDK
Chapter 2. Installing OpenJDK 8 on Red Hat Enterprise Linux OpenJDK 8 | Red Hat Customer Portal
$ sudo yum install java-1.8.0-openjdk-devel
泛型相關
Java 泛型是一种支持参数化类型的机制,它可以让代码更加通用和安全。通过使用泛型,我们可以在编写代码时使用占位符类型(如 T、E 等),然后在实际使用时再指定具体类型。这样就可以使代码更加灵活,可以避免类型转换错误和运行时异常。
Java 泛型的基本用法是使用尖括号 "<>" 括起来的一个或多个类型参数,这些类型参数可以用于类、接口、方法的声明中。例如:
public class MyClass<T> {
private T data;
public MyClass(T data) {
this.data = data;
}
public T getData() {
return data;
}
}
在上面的代码中,我们使用了一个类型参数 T,这个参数可以用于 MyClass 类中的任何地方,包括类的字段、方法参数、方法返回值等等。
而<?>和<T>的区别在于,<?>是一种无限制通配符类型,表示可以匹配任何类型,而<T>则是一个类型参数,表示在使用时需要指定具体的类型。例如:
List<?> list = new ArrayList<>();
List<String> strList = new ArrayList<>();
list = strList; // 合法,因为 list 可以匹配任何类型
public <T> T getValue(T[] array, int index) {
return array[index];
}
String[] strArray = {"hello", "world"};
String str = getValue(strArray, 0); // 合法,因为在使用 getValue 时指定了类型参数为 String
下面是一个使用无限制通配符类型(<?>)的例子,我们定义了一个方法,可以接受任何类型的 List,并打印出其中的元素:
public static void printList(List<?> list) {
for (Object element : list) {
System.out.println(element);
}
}
这个方法的参数列表中使用了无限制通配符类型(<?>),表示可以匹配任何类型的 List。在方法内部,我们使用了一个 for-each 循环遍历 list,并打印出其中的元素。
使用这个方法时,我们可以传入任何类型的 List,例如:
List<Integer> intList = Arrays.asList(1, 2, 3);
List<String> strList = Arrays.asList("hello", "world");
List<Object> objList = Arrays.asList(1, "hello", true);
printList(intList); // 输出 1, 2, 3
printList(strList); // 输出 hello, world
printList(objList); // 输出 1, hello, true
如果我们将上面的例子中的方法参数从无限制通配符类型(<?>)改为类型参数(<T>),那么代码将变成下面这样:
public static <T> void printList(List<T> list) {
for (T element : list) {
System.out.println(element);
}
}
这个方法的参数列表中使用了类型参数(<T>),表示在使用时需要指定 List 中元素的具体类型。在方法内部,我们使用了一个 for-each 循环遍历 list,并打印出其中的元素。
使用这个方法时,我们需要指定 List 中元素的具体类型,例如:
List<Integer> intList = Arrays.asList(1, 2, 3);
List<String> strList = Arrays.asList("hello", "world");
List<Object> objList = Arrays.asList(1, "hello", true);
printList(intList); // 输出 1, 2, 3
printList(strList); // 输出 hello, world
printList(objList); // 编译错误,因为 objList 中的元素类型不是 Object
在使用时,我们需要指定 List 中元素的具体类型,例如使用 printList(Integer) 或 printList(String),这样才能保证参数类型的匹配,否则将会编译错误。
在 Java 泛型中,类型参数的名称是可以任意指定的,通常使用以下的约定:
- T:表示任何类型。
- E:表示集合中的元素类型。
- K:表示映射中的键类型。
- V:表示映射中的值类型。
- N:表示数字类型。
- S、U、V 等:表示其他任意类型。
因此,使用 <T> 或 <E> 在语义上是等价的,只是名称不同而已。
除了以上提到的常用类型参数名称外,开发者也可以根据实际情况自行定义类型参数的名称,只需要遵循命名规范即可。不过,为了代码可读性和可维护性,建议使用常见的类型参数名称。
需要注意的是,不同的类型参数名称并没有实质上的差异,只是在语义上有所不同,因此选择类型参数名称时应根据实际情况和需求进行选择,选择一个能更好地表达自己的代码意图的名称。
一個回傳任意型別的範例
public static <T> T anyTypeMethod(T arg) {
if (arg == null) {
// 返回空对象
return (T) new Object();
}
// 方法逻辑
return arg;
}在这个方法中,我们首先检查参数是否为 null。如果参数为 null,则返回一个空对象,否则执行方法的逻辑,将参数原封不动地返回。
需要注意的是,在这个方法中,我们创建了一个新的 Object 对象并将其转换为泛型类型,这是为了避免空对象时返回类型不匹配的问题。因为 Java 中的泛型是在编译时进行类型擦除的,如果我们直接返回一个 null,编译器将无法确定返回值的类型,可能会导致编译错误或运行时异常。
使用这个方法时,我们可以传入任何类型的参数,并获取返回值,如果传入参数为 null,则返回一个空对象,例如:
Integer intValue = anyTypeMethod(123);
String strValue = anyTypeMethod("hello");
Object objValue = anyTypeMethod(new Object());
Object nullValue = anyTypeMethod(null);
System.out.println(intValue); // 输出 123
System.out.println(strValue); // 输出 "hello"
System.out.println(objValue); // 输出 Object 对象的 toString() 值
System.out.println(nullValue); // 输出 "java.lang.Object@hashcode"
在这个示例中,我们分别传入了一个整数、一个字符串、一个对象和一个 null,然后获取了相应的返回值。当传入参数为 null 时,返回一个空对象,其类型为 Object。
時間相關
Java提供了許多處理日期和時間的類和方法。以下是一些基本的日期操作:
java.util.Date
創建日期對象
Date currentDate = new Date();
java.text.SimpleDateFormat
格式化日期
可以使用java.text.SimpleDateFormat類將日期格式化為特定的字符串格式。例如:
SimpleDateFormat dateFormat = new SimpleDateFormat("yyyy-MM-dd");
String dateString = dateFormat.format(currentDate);
解析日期字符串
可以使用SimpleDateFormat類將字符串轉換為日期對象。例如:
String dateString = "2023-03-23";
SimpleDateFormat dateFormat = new SimpleDateFormat("yyyy-MM-dd");
Date date = dateFormat.parse(dateString);
java.util.Calendar
操作日期
可以使用java.util.Calendar類進行日期計算,例如添加或減去一定的時間。例如:
這將當前日期添加7天,得到一個未來的日期。
這僅是Java中處理日期的基本操作。還有許多其他的類和方法可以用來處理日期和時間。
Calendar calendar = Calendar.getInstance();
calendar.setTime(currentDate);
calendar.add(Calendar.DAY_OF_MONTH, 7);
Date futureDate = calendar.getTime();
找前五分鍾的日期
// 創建一個 Calendar 實例
Calendar calendar = Calendar.getInstance();
// 從當前日期和時間中減去 5 分鐘
calendar.add(Calendar.MINUTE, -5);
// 得到剛才減去的日期時間
Date fiveMinutesAgo = calendar.getTime();
// 格式化日期時間,如果需要的話
SimpleDateFormat dateFormat = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
String fiveMinutesAgoString = dateFormat.format(fiveMinutesAgo);
// 輸出結果
System.out.println("前五分鐘的日期時間為:" + fiveMinutesAgoString);
寫一個各種常用時間日期字串轉換成日期的方法
需要注意的是,轉換時需要確保時間文字的格式與使用的SimpleDateFormat格式一致,否則會導致轉換失敗。如果轉換失敗,則會拋出ParseException異常。
public static Date parseDateTimeString(String dateTimeString) {
// 定義各種常用的時間日期格式
Map<String, String> dateTimeFormats = new HashMap<>();
dateTimeFormats.put("yyyy-MM-dd", "^\\d{4}-\\d{2}-\\d{2}$");
dateTimeFormats.put("yyyy-MM-dd'T'HH:mm:ss", "^\\d{4}-\\d{2}-\\d{2}T\\d{2}:\\d{2}:\\d{2}$");
dateTimeFormats.put("yyyy-MM-dd'T'HH:mm:ss.SSS", "^\\d{4}-\\d{2}-\\d{2}T\\d{2}:\\d{2}:\\d{2}.\\d{3}$");
dateTimeFormats.put("yyyy-MM-dd'T'HH:mm:ss'Z'", "^\\d{4}-\\d{2}-\\d{2}T\\d{2}:\\d{2}:\\d{2}Z$");
dateTimeFormats.put("yyyy-MM-dd'T'HH:mm:ss.SSS'Z'", "^\\d{4}-\\d{2}-\\d{2}T\\d{2}:\\d{2}:\\d{2}.\\d{3}Z$");
dateTimeFormats.put("EEE MMM dd HH:mm:ss zzz yyyy", "^\\w{3} \\w{3} \\d{2} \\d{2}:\\d{2}:\\d{2} \\w{3} \\d{4}$");
// 使用各種格式進行轉換,直到轉換成功為止
for (Map.Entry<String, String> entry : dateTimeFormats.entrySet()) {
String format = entry.getKey();
String regex = entry.getValue();
if (dateTimeString.matches(regex)) {
try {
SimpleDateFormat dateFormat = new SimpleDateFormat(format, Locale.ENGLISH);
Date date = dateFormat.parse(dateTimeString);
return date;
} catch (ParseException e) {
// 轉換失敗,繼續使用下一個格式進行轉換
}
}
}
// 如果所有格式都無法轉換,則返回null
return null;
}
好用時間Lib
在Java中,有許多好用的時間相關的函式庫,以下是一些常見且經常使用的時間函式庫推薦:
-
Joda-Time:Joda-Time是一個廣泛使用的Java日期和時間庫,它提供了比Java內置日期時間類庫更多的功能。Joda-Time包含各種類型的日期,時間和時間間隔,並提供了許多便捷的方法來進行日期計算和格式化。
-
java.time:Java 8引入了新的時間API,稱為java.time。它提供了新的日期時間類型,例如LocalDate,LocalTime和ZonedDateTime等,並提供了許多便於使用的方法來進行日期計算和格式化。
-
Date4j:Date4j是一個輕量級的日期和時間庫,它具有方便的方法和較小的庫大小。Date4j支持基本日期和時間計算,例如計算兩個日期之間的天數,以及格式化日期時間。
-
PrettyTime:PrettyTime是一個Java函式庫,用於將日期和時間轉換為易於閱讀的相對時間(例如“3天前”)。它支持多種語言和格式,可以輕鬆地集成到Java應用程序中。
Collection 相關
建立Map
// Java 9 以上
Map<String, Integer> map = Map.of("apple", 1, "banana", 2, "orange", 3);
System.out.println(map); // {banana=2, orange=3, apple=1}
// java 通用
Map<String, Integer> map = new HashMap<>();
map.put("apple", 1);
map.put("banana", 2);
map.put("orange", 3);
System.out.println(map); // {banana=2, orange=3, apple=1}
final 相關
final 是 Java 中的一个关键字,用于修饰变量、方法和类,表示其值或状态不可改变。使用 final 可以提高程序的安全性、可读性和性能,通常在以下情况下使用:
- 声明不可变常量
可以使用 final 关键字来声明不可变常量,一旦声明后,该常量的值就不能再被修改。这样可以避免程序中的常量被误修改,提高程序的健壮性。
public static final int MAX_NUM = 100;
- 防止继承和重写
可以使用 final 关键字来修饰一个类,表示该类不可被继承。同时,也可以修饰一个方法,表示该方法不可被子类重写。这样可以避免在继承和多态的过程中产生不可预知的行为,提高程序的稳定性和可维护性。
public final class MyClass {
// 类定义
}
public class MySubClass extends MyClass {
// 编译错误,无法继承 final 类
}
public class MyClass {
public final void myMethod() {
// 方法定义
}
}
public class MySubClass extends MyClass {
public void myMethod() {
// 编译错误,无法重写 final 方法
}
}
- 确保线程安全
可以使用 final 关键字来修饰一个变量,表示该变量只能被赋值一次,并且在多线程环境下是线程安全的。这样可以避免在多线程环境下出现竞争和数据不一致的问题,提高程序的并发性和稳定性。
public class MyClass {
private final int num;
public MyClass(int num) {
this.num = num;
}
public int getNum() {
return num;
}
}
- 优化代码性能
可以使用 final 关键字来修饰一个变量,表示该变量的值在赋值后不再改变,并且该变量在运行时会被优化为常量,从而提高程序的性能。
public void myMethod(final int num) {
// 方法定义
}
在上述示例中,我们使用 final 关键字来修饰了常量、类、方法和变量,分别达到了不同的目的。使用 final 可以提高程序的健壮性、稳定性、可读性和性能,是 Java 编程中的重要特性之一。
Java 版本相關
- JDK 1.0 (1996年1月23日)
- JDK 1.1 (1997年2月19日)
- J2SE 1.2 (1998年12月8日)
- J2SE 1.3 (2000年5月8日)
- J2SE 1.4 (2002年2月13日)
- J2SE 5.0 (2004年9月30日)
- Java SE 6 (2006年12月11日)
- Java SE 7 (2011年7月28日)
- Java SE 8 (2014年3月18日)
- Java SE 9 (2017年9月21日)
- Java SE 10 (2018年3月20日)
- Java SE 11 (2018年9月25日)
- Java SE 12 (2019年3月19日)
- Java SE 13 (2019年9月17日)
- Java SE 14 (2020年3月17日)
- Java SE 15 (2020年9月15日)
- Java SE 16 (2021年3月16日)
- Java SE 17 (2021年9月14日)
以下是自Java 1.6版本以来的主要新增功能:
-
Java SE 6(2006年12月):
- 支持JDBC 4.0规范
- 新增JAX-WS 2.0 API
- 新增JAXB 2.0 API
- 新增Java Compiler API
-
Java SE 7(2011年7月):
- 新增Diamond操作符(类型推断)
- 支持多个异常捕获
- 新增字符串在switch语句中的使用
- 新增可变参数的try语句
- 新增NIO 2.0 API
-
Java SE 8(2014年3月):
- 新增Lambda表达式
- 新增Date/Time API
- 新增Nashorn JavaScript引擎
- 新增Stream API
- 新增Type Annotations
-
Java SE 9(2017年9月):
- 新增模块系统(Java Platform Module System)
- 新增私有接口方法
- 新增改进的Javadoc
- 新增响应式流 API
- 新增JShell REPL(Read-Eval-Print Loop)
-
Java SE 10(2018年3月):
- 新增局部变量类型推断
- 新增应用类数据共享
- 新增JEP 286:本地变量类型推断
- 新增JEP 322:Time-Based Release Versioning
-
Java SE 11(2018年9月):
- 新增var在Lambda表达式中的使用
- 新增嵌套访问控制
- 移除Java EE和CORBA模块
- 新增ZGC垃圾回收器
-
Java SE 12(2019年3月):
- 新增JEP 189:Shenandoah垃圾回收器
- 新增JEP 325:Switch表达式(标准化)
-
Java SE 13(2019年9月):
- 新增文本块
- 新增Switch表达式的增强功能
- 新增JFR事件流
-
Java SE 14(2020年3月):
- 新增记录(Records)
- 新增Switch表达式的增强功能
- 新增Pattern匹配实例of
-
Java SE 15(2020年9月):
- 新增Sealed类和接口
- 新增Hidden类和接口
- 新增Pattern匹配实例of的增强功能
- Java SE 16(2021年3月):
- 新增Records的增强功能
- 新增强制类型转换模式匹配
- 新增JEP 394:模式匹配 instanceof的增强功能
- Java SE 17(2021年9月):
- 新增Sealed类和接口的增强功能
- 新增Switch表达式的增强功能
- 新增Pattern匹配实例of的增强功能
- 新增JEP 403:Strong
Maven相關
FROM openjdk:8-jdk
ARG MAVEN_VERSION=3.3.9
ARG USER_HOME_DIR="/root"
RUN apt-get update
RUN apt-get install build-essential -y
RUN ln -sf /usr/bin/make /usr/bin/gmake
RUN mkdir -p /usr/share/maven /usr/share/maven/ref \
&& curl -fsSL http://apache.osuosl.org/maven/maven-3/$MAVEN_VERSION/binaries/apache-maven-$MAVEN_VERSION-bin.tar.gz \
| tar -xzC /usr/share/maven --strip-components=1 \
&& ln -s /usr/share/maven/bin/mvn /usr/bin/mvn
ENV MAVEN_HOME /usr/share/maven
ENV MAVEN_CONFIG "$USER_HOME_DIR/.m2"
VOLUME ["/usr/src/mymaven", "/root/.m2"]Optional 相關
Optional是Java SE 8中的一个新特性,它提供了一种优雅的方式来处理可能为空的值,避免了空指针异常的问题。
Optional类提供了以下常用方法:
- of():创建一个包含指定非空值的Optional对象。如果传入null,则会抛出NullPointerException异常。例如:
Optional<String> optional = Optional.of("hello");
- empty():创建一个空的Optional对象。例如:
Optional<String> optional = Optional.empty();
- isPresent():判断Optional对象是否包含非空值。例如:
Optional<String> optional = Optional.of("hello");
if (optional.isPresent()) {
System.out.println("value is present: " + optional.get());
}
- get():获取Optional对象中的值,如果对象为空则抛出NoSuchElementException异常。例如:
Optional<String> optional = Optional.of("hello");
String value = optional.get();
System.out.println("value: " + value);
- orElse():获取Optional对象中的值,如果对象为空则返回指定的默认值。例如:
Optional<String> optional = Optional.empty();
String value = optional.orElse("default");
System.out.println("value: " + value);
- map():对Optional对象中的值进行映射操作,返回一个新的Optional对象。例如:
Optional<String> optional = Optional.of("hello");
Optional<Integer> result = optional.map(s -> s.length());
System.out.println("result: " + result.get());
- filter():对Optional对象中的值进行过滤操作,返回一个新的Optional对象。例如:
Optional<String> optional = Optional.of("hello");
Optional<String> result = optional.filter(s -> s.startsWith("h"));
System.out.println("result: " + result.get());
需要注意的是,对Optional对象的操作通常采用链式调用的方式,如下所示:
Optional<String> optional = Optional.of("hello");
String result = optional.map(s -> s.toUpperCase())
.orElse("default");
System.out.println("result: " + result);
optional.isPresent()方法用于检查Optional对象是否包含非空值,如果对象中包含了一个非空的值,则返回true,否则返回false。
如果使用Optional.of()方法创建一个Optional对象时,传入了一个空引用,则会抛出NullPointerException异常,而不是返回一个包含空值的Optional对象。因此,如果使用Optional.of()方法创建的Optional对象中包含了一个空引用,则调用optional.isPresent()方法会返回false,而不是检查空字符串。
如果需要检查一个空字符串,可以使用Optional.ofNullable()方法创建一个Optional对象,例如:
String str = "";
Optional<String> optional = Optional.ofNullable(str);
if (optional.isPresent()) {
System.out.println("str is not empty");
} else {
System.out.println("str is empty");
}
在上面的示例中,我们首先使用一个空字符串创建一个Optional对象,然后使用optional.isPresent()方法检查字符串是否为空。由于字符串为空,因此调用optional.isPresent()方法会返回false,所以最终输出结果为"str is empty"。
Stream API
Stream API是Java 8中引入的一种新的API,它提供了一种用流的方式对集合(Collection)和数组(Array)进行处理的方法,它的目标是使得代码更加简洁、易读和易于维护。
Stream API的主要优点包括:
-
方便:使用Stream API可以方便地处理集合或数组中的元素,无需手动编写循环语句。
-
简洁:使用Stream API可以用更少的代码完成相同的任务,因为Stream API提供了一系列的函数式操作,例如过滤、映射、排序等,这些操作可以链式调用,从而使代码更加简洁易懂。
-
高效:使用Stream API可以提高代码的执行效率,因为Stream API使用了惰性求值的方式,只有在需要时才会执行操作,这避免了不必要的计算和内存开销。
Stream API的核心概念包括:
-
流(Stream):Stream是一种序列化的对象集合,它支持顺序和并行两种操作模式,并且可以在不修改原始集合的情况下进行各种操作。
-
操作(Operations):Stream提供了一系列的函数式操作,例如过滤、映射、排序等,这些操作可以链式调用,形成操作链。
-
终止操作(Terminal Operations):最后必须使用终止操作,例如forEach、count、reduce等,才能得到操作的结果。
Stream API的出现使得Java在集合处理方面更加强大和灵活,也使得Java代码变得更加简洁、易读和易于维护。
当使用Stream API时,可以通过一系列的中间操作来对集合或数组进行处理,最后再通过终止操作获取结果。下面是一些使用Stream API的示例:
- 集合过滤:
假设有一个List<String>类型的集合,现在需要过滤出其中长度大于3的元素,可以使用如下代码:
List<String> list = Arrays.asList("apple", "banana", "cat", "dog", "elephant");
List<String> filteredList = list.stream()
.filter(str -> str.length() > 3)
.collect(Collectors.toList());
System.out.println(filteredList); // [apple, banana, elephant]
- 集合映射:
假设有一个List<Integer>类型的集合,现在需要将其中每个元素乘以2,可以使用如下代码:
List<Integer> list = Arrays.asList(1, 2, 3, 4, 5);
List<Integer> mappedList = list.stream()
.map(num -> num * 2)
.collect(Collectors.toList());
System.out.println(mappedList); // [2, 4, 6, 8, 10]
在上面的代码中,我们首先调用stream()方法将集合转换成Stream对象,然后使用map操作对每个元素进行乘以2的操作,最后使用collect操作将结果转换为List类型。
- 数组排序:
假设有一个int[]类型的数组,现在需要将其中的元素按照从小到大的顺序进行排序,可以使用如下代码:
List<Integer> list = Arrays.asList(1, 2, 3, 4, 5);
List<Integer> mappedList = list.stream()
.map(num -> num * 2)
.collect(Collectors.toList());
System.out.println(mappedList); // [2, 4, 6, 8, 10]
在上面的代码中,我们首先调用Arrays.stream()方法将数组转换成IntStream对象,然后使用sorted操作对元素进行排序,最后使用toArray操作将结果转换为int[]类型。
Tomcat伺服器詳解
Tomcat伺服器理詳解 | 程式前沿 (codertw.com)
Bean 與 Pojo
Bean、POJO 是 Java 領域中常用的術語,兩者均是軟體開發中常用的類別設計方式。
Bean 是一個可重複使用、可移植的軟體元件,具有以下特徵:
- 實體化後需要經過初始化,可以透過 setter 或 constructor 注入屬性值
- 必須具有一個無參數的預設建構子
- 可以實作 Serializable 介面以支援序列化
- 常見的 Bean 類型包括 Spring Framework 中的 Bean、JavaBean 等
POJO(Plain Old Java Object)是一個純粹的 Java 物件,沒有任何限制或框架要求,具有以下特徵:
- 無需繼承特定的類別或實作特定的介面
- 可以包含任意數量和任意型別的屬性和方法
- 可以實作 Serializable 介面以支援序列化
簡單來說,Bean 是 Spring 框架中的一種概念,它是一個有生命週期、可管理的物件,必須符合特定的設計要求。而 POJO 則是一個更通用的概念,它沒有特定的框架或設計要求,可以隨意設計,但這也代表它可能缺乏特定框架的功能和支援。
在 Spring 框架中,Bean 通常被用作被 Spring 管理的物件,例如 Service、Controller 等,而 POJO 則通常用來表示簡單的 Java 物件。
【Java】自Java 1.6版本以来的主要新增功能
以下是自Java 1.6版本以来的主要新增功能:
-
Java SE 6(2006年12月):
- 支持JDBC 4.0规范
- 新增JAX-WS 2.0 API
- 新增JAXB 2.0 API
- 新增Java Compiler API
-
Java SE 7(2011年7月):
- 新增Diamond操作符(类型推断)
- 支持多个异常捕获
- 新增字符串在switch语句中的使用
- 新增可变参数的try语句
- 新增NIO 2.0 API
-
Java SE 8(2014年3月):
- 新增Lambda表达式
- 新增Date/Time API
- 新增Nashorn JavaScript引擎
- 新增Stream API
- 新增Type Annotations
-
Java SE 9(2017年9月):
- 新增模块系统(Java Platform Module System)
- 新增私有接口方法
- 新增改进的Javadoc
- 新增响应式流 API
- 新增JShell REPL(Read-Eval-Print Loop)
-
Java SE 10(2018年3月):
- 新增局部变量类型推断
- 新增应用类数据共享
- 新增JEP 286:本地变量类型推断
- 新增JEP 322:Time-Based Release Versioning
-
Java SE 11(2018年9月):
- 新增var在Lambda表达式中的使用
- 新增嵌套访问控制
- 移除Java EE和CORBA模块
- 新增ZGC垃圾回收器
-
Java SE 12(2019年3月):
- 新增JEP 189:Shenandoah垃圾回收器
- 新增JEP 325:Switch表达式(标准化)
-
Java SE 13(2019年9月):
- 新增文本块
- 新增Switch表达式的增强功能
- 新增JFR事件流
-
Java SE 14(2020年3月):
- 新增记录(Records)
- 新增Switch表达式的增强功能
- 新增Pattern匹配实例of
-
Java SE 15(2020年9月):
- 新增Sealed类和接口
- 新增Hidden类和接口
- 新增Pattern匹配实例of的增强功能
- Java SE 16(2021年3月):
- 新增Records的增强功能
- 新增强制类型转换模式匹配
- 新增JEP 394:模式匹配 instanceof的增强功能
- Java SE 17(2021年9月):
- 新增Sealed类和接口的增强功能
- 新增Switch表达式的增强功能
- 新增Pattern匹配实例of的增强功能
- 新增JEP 403:Strong
【SDKMAN】安裝管理JAVA
來源: https://blog.miniasp.com/post/2022/09/17/Useful-tool-SDKMAN
透過 SDKMAN 安裝JAVA
#安裝 SDKMAN
curl -s "https://get.sdkman.io" | bash
#首次手動載入 SDKMAN 工具 (預設安裝過程已經設定好 ~/.bashrc 啟動定義檔)
source ~/.bashrc
#檢查 SDKMAN 版本
sdk version
安裝 OpenJDK 17
#先列出所有 SDKMAN 中支援的 Java 版本
sdk ls java
================================================================================
Available Java Versions for macOS 64bit
================================================================================
Vendor | Use | Version | Dist | Status | Identifier
--------------------------------------------------------------------------------
Corretto | | 20.0.2 | amzn | | 20.0.2-amzn
| | 20.0.1 | amzn | | 20.0.1-amzn
| | 17.0.8 | amzn | | 17.0.8-amzn
| | 17.0.7 | amzn | | 17.0.7-amzn
| | 11.0.20 | amzn | | 11.0.20-amzn
| | 11.0.19 | amzn | | 11.0.19-amzn
| | 8.0.382 | amzn | | 8.0.382-amzn
| | 8.0.372 | amzn | | 8.0.372-amzn
Gluon | | 22.1.0.1.r17 | gln | | 22.1.0.1.r17-gln
| | 22.1.0.1.r11 | gln | | 22.1.0.1.r11-gln
| | 22.0.0.3.r17 | gln | | 22.0.0.3.r17-gln
| | 22.0.0.3.r11 | gln | | 22.0.0.3.r11-gln
GraalVM CE | | 20.0.2 | graalce | | 20.0.2-graalce
| | 20.0.1 | graalce | | 20.0.1-graalce
| | 17.0.8 | graalce | | 17.0.8-graalce
| | 17.0.7 | graalce | | 17.0.7-graalce
GraalVM Oracle| | 20.0.2 | graal | | 20.0.2-graal
| | 20.0.1 | graal | | 20.0.1-graal
| | 17.0.8 | graal | | 17.0.8-graal
| | 17.0.7 | graal | | 17.0.7-graal
Java.net | | 22.ea.9 | open | | 22.ea.9-open
| | 22.ea.8 | open | | 22.ea.8-open
| | 22.ea.7 | open | | 22.ea.7-open
| | 22.ea.6 | open | | 22.ea.6-open
| | 22.ea.5 | open | | 22.ea.5-open
| | 22.ea.4 | open | | 22.ea.4-open
| | 22.ea.3 | open | | 22.ea.3-open
| | 21.ea.34 | open | | 21.ea.34-open
| | 21.ea.33 | open | | 21.ea.33-open
| | 21.ea.32 | open | | 21.ea.32-open
| | 21.ea.31 | open | | 21.ea.31-open
| | 21.ea.30 | open | | 21.ea.30-open
| | 21.ea.29 | open | | 21.ea.29-open
| | 21.ea.28 | open | | 21.ea.28-open
| | 20.0.2 | open | | 20.0.2-open
| | 19.ea.1.pma | open | | 19.ea.1.pma-open
JetBrains | | 17.0.7 | jbr | | 17.0.7-jbr
| | 11.0.14.1 | jbr | | 11.0.14.1-jbr
================================================================================
Omit Identifier to install default version 17.0.8-tem:
$ sdk install java
Use TAB completion to discover available versions
$ sdk install java [TAB]
Or install a specific version by Identifier:
$ sdk install java 17.0.8-tem
Hit Q to exit this list view
================================================================================
安裝 JetBranins 17.0.7
sdk install java 17.0.7-jbr 透過 SDKMAN 管理多個 JDK 版本
#先安裝 11.0.14.1-jbr 版本
sdk install java 11.0.14.1-jbr
########################################################
Downloading: java 11.0.14.1-jbr
In progress...
################################################################################################################################################################################################################################################# 100.0%################################################################################################################################################################################################################################################# 100.0%
Repackaging Java 11.0.14.1-jbr...
Done repackaging...
Cleaning up residual files...
Installing: java 11.0.14.1-jbr
Done installing!
#選 n 不要變成預設版本
Do you want java 11.0.14.1-jbr to be set as default? (Y/n): n
#在目前shell 切換版本
sdk use java 11.0.14.1-jbr
#如果要設為預設版本
sdk default java 11.0.14.1-jbr
#確認版本可以透過 sdk current java 或 java -version 確認版本透過 SDKMAN 管理更新、升級、移除
#查看是否有更新版本
sdk update
#升級版本
sdk upgrade
# 移除特定版本
# 記得將預設版本切換到現有版本
sdk default java 17.0.4.1-ms
sdk uninstall java 8.0.345-zulu更新 SDKMAN 到最新版
sdk selfupdate快速安裝springboot
curl -s "https://get.sdkman.io" | bash
source ~/.bashrc
sdk install java 17.0.4.1-ms
sdk install maven
sdk install springboot
SpringBoot
【IDE】STS(Stping Tool Suite) 相關
效能調教
STS卡頓(一次STS IDE 優化調優記錄) - 台部落 (twblogs.net)
JVM参数简介:
-Xmx1200m 最大堆内存,一般设置为物理内存的1/4。
-Xms256m 初始堆内存。
-Xmn128m 年轻代堆内存。
-XX:PermSize=64m 持久代堆的初始大小
-XX:MaxPermSize=256m 持久代堆的最大大小
年轻代堆内存 对象刚创建出来时存放在这里
年老代堆内存 对象在被真正会回收之前会存放在这里
持久代堆内存 元数据等存放在这里
堆内存 年轻代堆内存 + 年老代堆内存 + 持久代堆内存
原文链接:https://blog.csdn.net/Hello_World_QWP/article/details/83302530
Maven Proxy 設定
setting.xml
<proxies>
<!-- proxy
| Specification for one proxy, to be used in connecting to the network.
|
<proxy>
<id>optional</id>
<active>true</active>
<protocol>http</protocol>
<username>proxyuser</username>
<password>proxypass</password>
<host>proxy.host.net</host>
<port>80</port>
<nonProxyHosts>local.net|some.host.com</nonProxyHosts>
</proxy>
-->
<proxy>
<id>optional</id>
<active>true</active>
<protocol>http</protocol>
<host>192.168.1.1</host>
<port>3128</port>
</proxy>
<proxy>
<id>optional2</id>
<active>true</active>
<protocol>https</protocol>
<host>192.168.1.1</host>
<port>3128</port>
</proxy>
</proxies>【SpringBoot】 annotation
以下是常用的 Spring Boot Annotation 的說明
-
@SpringBootApplication:用於標記Spring Boot應用程序的主要類,它結合了@Configuration、@EnableAutoConfiguration、@ComponentScan三個註解的功能。 -
@Controller:用來標記一個類,表示這是一個Controller,可以處理HTTP請求。
-
@RestController:用於標記一個控制器類,並表示該類中所有的方法都會以JSON格式返回結果。 -
@RequestMapping:使用標記Controller中的方法,並指定該方法的URL路徑。-
@GetMapping:類似於@RequestMapping,但只是處理HTTP GET請求。
-
@PostMapping:類似於@RequestMapping,但只是處理HTTP POST請求。
-
@PutMapping:類似於@RequestMapping,但只是處理HTTP PUT請求。
-
@DeleteMapping:類似@RequestMapping,但只是處理HTTP DELETE請求。
-
-
@PathVariable:用來獲取URL路徑上的變量值。
-
@RequestParam:用來獲取HTTP請求中的參數值。
-
@RequestBody:用於獲取HTTP請求中的請求體,一般用於處理POST請求。
-
@ResponseBody:使用指定方法返回值的格式,可以是JSON、XML或者其他格式
-
@Autowired:用於將依賴註冊到Spring容器中,可以在成員變量、構造函數數、Setter方法中使用。 -
@Value:用於獲取配置文件中的值,例如數據庫連接信息、服務端接口等。 -
@Configuration:用於標記一個配置類,配置類中通常包含@Bean註解的方法,用於提供Bean的定義。 -
@Bean:用於將方法返回的對象註冊為Bean,Spring容器管理該Bean的生命週期。 -
@EnableAutoConfiguration:用於啟動Spring Boot的自動配置功能,Spring Boot會根據當前的classpath和配置文件,自動配置所需的Bean。 -
@ComponentScan:用於指定需要掃描的包,Spring Boot會掃描該包及其子包下面所有的@Component註解,並將其註冊為Bean。 -
@Transactional:用於標記一個方法或類需要事務管理,Spring Boot會根據@Transactional註解的配置,自動創建事務,並管理其生命週期。 -
@Profile:使用指定Bean的配置文件的Profile,不同的Profile可以在不同的環境下使用不同的配置。 -
@Async:用於標記一個方法為異常方法,Spring Boot會自動將方法放入線程池中執行
@SpringBootApplication
掛有@SpringBootApplication
main程式為執行時的進入點。同時也是主要的配置類別。
會掃描所在類別的package及其子package中掛有
@Component
@Controller
@Service
@Repository
等component類別並註冊為spring bean。
包含三種 annotation
@EnableAutoConfiguration
@ComponentScan
@Configuration
【SpringBoot】@Scheduled 定時執行
在Spring Boot中,我们可以使用注释@Scheduled来定时执行方法。该注释可用于将方法标记为需要定期执行的方法,并提供执行计划。
@Scheduled注释支持以下属性:
1. fixedRate:以毫秒为单位的执行速率。
2. fixedDelay:以毫秒为单位的执行延迟,即上一次执行结束后的延迟时间。
3. initialDelay:第一次执行的延迟时间,以毫秒为单位。
4. cron:CRON表达式,用于更高级的定时计划。
下面是一个简单的示例,该示例演示如何使用@Scheduled注释在Spring Boot中定期执行方法:
import org.springframework.scheduling.annotation.Scheduled;
import org.springframework.stereotype.Component;
@Component
public class MyTask {
@Scheduled(fixedRate = 5000)
public void printMessage() {
System.out.println("Hello, world!");
}
}在上述示例中,我们定义了一个名为MyTask的组件,其中包含一个使用@Scheduled注释标记的printMessage方法。此方法将在每隔5秒钟输出一条消息"Hello, world!"。
我们还可以使用fixedDelay属性来延迟执行。例如,如果我们将fixedDelay设置为10000,那么该方法将在上一次执行结束后等待10秒才能开始下一次执行。
@Scheduled注释还支持CRON表达式,这使得我们可以更高级地安排任务。例如,如果我们想要在每天早上6点执行任务,我们可以使用以下CRON表达式:
0 0 6 * * *在此示例中,我们使用六个星号来指定秒,分,时,日,月和星期几。因此,此表达式将在每天早上6点执行任务。
註解停用
如果你想暂时停用@Scheduled注释标记的方法,你可以简单地注释掉它,或者将其标记为禁用,以便稍后重新启用。
要注释掉方法,请将其注释掉:
// @Scheduled(fixedRate = 5000)
public void printMessage() {
System.out.println("Hello, world!");
}
要禁用方法,您可以使用@Scheduled注释的enabled属性:
// @Scheduled(fixedRate = 5000)
public void printMessage() {
System.out.println("Hello, world!");
}
在这个例子中,我们使用@Scheduled注释的enabled属性将printMessage方法标记为已禁用。要重新启用该方法,只需将enabled属性设置为true即可。
使用命令停用
是的,您可以使用Spring Boot Actuator的端点来动态启用/禁用定时任务。Spring Boot Actuator是Spring Boot的一个附加模块,提供了很多有用的端点,可以在应用程序运行时监视和管理应用程序。
您需要在项目中添加Actuator依赖项:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>
然后,您可以使用`/actuator/scheduledtasks`端点来检查和管理定时任务。要暂时停用定时任务,您可以使用该端点来取消计划的任务。例如:
@Scheduled(fixedRate = 5000, name = "myTask")
public void printMessage() {
System.out.println("Hello, world!");
}
$ curl -X POST http://localhost:8080/actuator/scheduledtasks/taskName这将取消计划名为taskName的任务。要重新启用该任务,您可以使用该端点来重新启用任务:
$ curl -X DELETE http://localhost:8080/actuator/scheduledtasks/taskName
假设您的Spring Boot应用程序正在运行,并且您已经添加了Actuator依赖项,那么您可以使用以下curl命令向`/actuator/scheduledtasks`端点发出HTTP GET请求来获取当前应用程序中所有定时任务的列表:
curl http://localhost:8080/actuator/scheduledtasks这将返回一个JSON格式的响应,其中包含有关每个定时任务的信息,例如任务名称、任务是否启用、任务的CRON表达式等。您可以使用该响应来查看应用程序中所有的定时任务信息。
{
"cron": {
"myScheduledTask": {
"scheduled": true,
"expression": "0/30 * * * * ?"
}
},
"fixedDelay": {},
"fixedRate": {}
}
【SpringBoot】 監控工具 Actuator
參考: https://kucw.github.io/blog/2020/7/spring-actuator/
官方文件: https://docs.spring.io/spring-boot/docs/current/actuator-api/htmlsingle/
Actuator 提供的所有 endpoint
此處使用的是 SpringBoot 2.2.8 版本,Spring 官方文件
| HTTP方法 | Endpoint | 描述 |
|---|---|---|
| GET | /actuator | 查看有哪些 Actuator endpoint 是開放的 |
| GET | /actuator/auditevent | 查看 audit 的事件,例如認證進入、訂單失敗,需要搭配 Spring security 使用,sample code |
| GET | /actuator/beans | 查看運行當下裡面全部的 bean,以及他們的關係 |
| GET | /actuator/conditions | 查看自動配置的結果,記錄哪些自動配置條件通過了,哪些沒通過 |
| GET | /actuator/configprops | 查看注入帶有 @ConfigurationProperties 類的 properties 值為何(包含默認值) |
| GET | /actuator/env (常用) | 查看全部環境屬性,可以看到 SpringBoot 載入了哪些 properties,以及這些 properties 的值(但是會自動*掉帶有 key、password、secret 等關鍵字的 properties 的值,保護安全資訊,超聰明!) |
| GET | /actuator/flyway | 查看 flyway DB 的 migration 資訊 |
| GET | /actuator/health (常用) | 查看當前 SpringBoot 運行的健康指標,值由 HealthIndicator 的實現類提供(所以可以自定義一些健康指標資訊,加到這裡面) |
| GET | /actuator/heapdump | 取得 JVM 當下的 heap dump,會下載一個檔案 |
| GET | /actuator/info | 查看 properties 中 info 開頭的屬性的值,沒啥用 |
| GET | /actuator/mappings | 查看全部的 endpoint(包含 Actuator 的),以及他們和 Controller 的關係 |
| GET | /actuator/metrics | 查看有哪些指標可以看(ex: jvm.memory.max、system.cpu.usage),要再使用/actuator/metrics/{metric.name}分別查看各指標的詳細資訊 |
| GET | /actuator/scheduledtasks | 查看定時任務的資訊 |
| POST | /actuator/shutdown | 唯一一個需要 POST 請求的 endpoint,關閉這個 SpringBoot 程式 |
開啟受保護的 endpoint 的方法
因為安全的因素,所以 Actuator 默認只會開放/actuator/health和/actuator/info這兩個 endpoint,如果要開放其他 endpoint 的話,需要額外在 application.properties 中做設置
# 可以這樣寫,就會開啟所有endpoints(不包含shutdown)
management.endpoints.web.exposure.include=*
# 也可以這樣寫,就只會開啟指定的endpoint,因此此處只會再額外開啟/actuator/beans和/actuator/mappings
management.endpoints.web.exposure.include=beans,mappings
# exclude可以用來關閉某些endpoints
# exclude通常會跟include一起用,就是先include了全部,然後再exclude /actuator/beans這個endpoint
management.endpoints.web.exposure.exclude=beans
management.endpoints.web.exposure.include=*
# 如果要開啟/actuator/shutdown,要額外再加這一行
management.endpoint.shutdown.enabled=true除此之外,也可以改變/actuator的路徑,可以自定義成自己想要的路徑
#這樣寫的話,原本內建的/actuator/xxx路徑,都會變成/manage/xxx,可以用來防止被其他人猜到
management.endpoints.web.base-path=/manage
常用命令
curl -X GET 'http://192.168.77.185:8080/actuator/mappings'
【SpringBoot】 開啟tomcat log
application.properties
server.tomcat.accesslog.buffered=true
server.tomcat.accesslog.enabled=true
server.tomcat.accesslog.file-date-format=.yyyy-MM-dd
server.tomcat.accesslog.pattern=%{yyyy-MM-dd HH:mm:ss}t %a %A %p %m %U %q %s %T %H %{referer}i %v %I %b %S %u
server.tomcat.accesslog.prefix=access_log
server.tomcat.accesslog.rename-on-rotate=false
server.tomcat.accesslog.request-attributes-enabled=false
server.tomcat.accesslog.rotate=true
server.tomcat.accesslog.suffix=.log
server.tomcat.accesslog.directory=logs
server.tomcat.basedir=${workspace.path}/docker/log/liveportaltomcat log pattern 文件 https://tomcat.apache.org/tomcat-8.0-doc/config/valve.html
- %a - Remote IP address
- %A - Local IP address
- %b - Bytes sent, excluding HTTP headers, or '-' if zero
- %B - Bytes sent, excluding HTTP headers
- %h - Remote host name (or IP address if
enableLookupsfor the connector is false) - %H - Request protocol
- %l - Remote logical username from identd (always returns '-')
- %m - Request method (GET, POST, etc.)
- %p - Local port on which this request was received. See also
%{xxx}pbelow. - %q - Query string (prepended with a '?' if it exists)
- %r - First line of the request (method and request URI)
- %s - HTTP status code of the response
- %S - User session ID
- %t - Date and time, in Common Log Format
- %u - Remote user that was authenticated (if any), else '-'
- %U - Requested URL path
- %v - Local server name
- %D - Time taken to process the request, in millis
- %T - Time taken to process the request, in seconds
- %F - Time taken to commit the response, in millis
- %I - Current request thread name (can compare later with stacktraces)
There is also support to write information incoming or outgoing headers, cookies, session or request attributes and special timestamp formats. It is modeled after the Apache HTTP Server log configuration syntax. Each of them can be used multiple times with different xxx keys:
%{xxx}iwrite value of incoming header with namexxx%{xxx}owrite value of outgoing header with namexxx%{xxx}cwrite value of cookie with namexxx%{xxx}rwrite value of ServletRequest attribute with namexxx%{xxx}swrite value of HttpSession attribute with namexxx%{xxx}pwrite local (server) port (xxx==local) or remote (client) port (xxx=remote)%{xxx}twrite timestamp at the end of the request formatted using the enhanced SimpleDateFormat patternxxx
All formats supported by SimpleDateFormat are allowed in %{xxx}t. In addition the following extensions have been added:
sec- number of seconds since the epochmsec- number of milliseconds since the epochmsec_frac- millisecond fraction
【SpringBoot】相關資源
- [尚圭谷]SpringBoot3全栈指南
https://www.youtube.com/playlist?list=PLmOn9nNkQxJEeIH75s5pdTUnCo9-xOc7c
https://www.yuque.com/leifengyang/springboot3
https://gitee.com/leifengyang/spring-boot-3 - openapi (swagger)
https://springdoc.org/
【SpringBoot】Redis
出處 https://www.cnblogs.com/rb2010/p/12905470.html
pom.xml
< dependency >
< groupId > org.springframework.boot </ groupId >
< artifactId > spring-boot-starter-data-redis </ artifactId >
</ dependency >二、設定YML檔(二選一)
1. sentinel模式
spring:
redis:
sentinel:
nodes:
- 192.168.0.106:26379
- 192.168.0.106:26380
- 192.168.0.106:26381 //哨兵的ip和端口
master: mymaster //這就是哨兵設定檔中sentinel monitor mymaster 192.168.0.103 6379 2設定的mymaster2.Cluster模式
spring:
redis:
cluster:
nodes: 192.168.0.106:7000,192.168.0.106:7001,192.168.0.106:7002,192.168.0.106:7003三、配置RedisTemplate模版
@Configuration
public class RedisConf {
@Bean
public RedisTemplate<Object, Object> redisTemplate(RedisConnectionFactory redisConnectionFactory) {
Jackson2JsonRedisSerializer serializer = new Jackson2JsonRedisSerializer(Object. class );
RedisTemplate <Object, Object> template = new RedisTemplate<> ();
template.setConnectionFactory(redisConnectionFactory);
template.setKeySerializer(serializer); //設定key序列化(不一定要)
template.setValueSerializer(serializer);//設定value序列化(不一定要)
return template; }
// 讀寫分離
@Bean
public LettuceClientConfigurationBuilderCustomizer clientConfigurationBuilderCustomizer() {
return clientConfigurationBuilder -> {
clientConfigurationBuilder.readFrom(ReadFrom.REPLICA_PREFERRED);
};
}
}
四、測試(簡單的model就省略了)
@RestController
public class RedisTestController {
@Autowired
RedisTemplate redisTemplate;
@GetMapping( "set" )
public void set(){
redisTemplate.opsForValue().set( "key1","123" );
User u = new User();
u.setId( 1 );
u.setName( "name姓名" );
redisTemplate.opsForValue().set( "user" ,u);
}
@GetMapping( "get" )
public Map get(){
Map map = new HashMap();
map.put( "v1",redisTemplate.opsForValue().get("key1" ));
map.put( "v2",redisTemplate.opsForValue().get("user" ));
return map;
}
}相關連結
- redis分佈鎖
- Springboot集成Redis实现分布式锁
- 阿里華為等大廠的Redis分散式鎖是如何設計的?
- spring-boot-redisson 与 spring-data-redis 共存问题
【SpringBoot】cors
Controll 新增 @CrossOrigin
@CrossOrigin(origins = "*", exposedHeaders = {"X-Total-Count"})@RestController
@RequestMapping("/api")
@CrossOrigin(origins = "*", exposedHeaders = {"X-Total-Count"})
public class ActionController {
private static final Logger logger = LoggerFactory.getLogger(ActionController.class);
@Autowired
private ShowRepository showRepository;
}
// http.cors().and().csrf().disable()
public class WebSecurityConfig extends WebSecurityConfigurerAdapter {
protected void configure(HttpSecurity http) throws Exception {
http.cors().and().csrf().disable()
.exceptionHandling().authenticationEntryPoint(unauthorizedHandler).and()
.sessionManagement().sessionCreationPolicy(SessionCreationPolicy.STATELESS).and()
.authorizeRequests()
.antMatchers("/build/**").permitAll() // build-info
.anyRequest().authenticated();
http.addFilterBefore(authenticationJwtTokenFilter(), UsernamePasswordAuthenticationFilter.class);
}
}【SpringBoot】java 啟動參數
nohup java -server
-Xms4096m -Xmx4096m -XX:+UseG1GC
-XX:G1HeapRegionSize=1m
-XX:+UseStringDeduplication
-XX:MaxDirectMemorySize=1024m
-XX:+UnlockDiagnosticVMOptions
javaagent:/usr/AP/pinpoint/pinpoint-bootstrap-2.3.3.jar
-Dpinpoint.agentId=$agentId -Dpinpoint.applicationName=member
-jar test.jar
# 啟動參數
-server:
啟用Java虛擬機的伺服器模式。伺服器模式通常用於長時間運行的應用程序,以提供更好的性能。
-Xms4096m:
設定Java堆的初始內存大小為4 GB。這是Java應用程序啟動時分配的堆內存。
-Xmx4096m:
設定Java堆的最大內存大小為4 GB。這是Java應用程序在運行時能夠使用的最大堆內存。
-XX:+UseG1GC:
啟用G1垃圾回收器。G1(Garbage First)是一種面向服務端應用的垃圾回收器,旨在提供更穩定的性能和可預測的停頓時間。
-XX:G1HeapRegionSize=1m:
設定G1垃圾回收器的堆區域大小為1 MB。G1將Java堆劃分為多個相同大小的區域,這個參數設定每個區域的大小。
-XX:+UseStringDeduplication:
啟用字符串去重。這個選項將嘗試減少堆上相同字符串對象的重複,以節省內存。
-XX:MaxDirectMemorySize=1024m:
設定最大直接內存大小為1 GB。直接內存是一種不受Java堆管理的內存,通常由NIO庫使用。
-XX:+UnlockDiagnosticVMOptions:
解鎖診斷性虛擬機選項。這個選項允許使用一些診斷性工具和功能,通常在調試和性能分析中使用。
-Dpinpoint.agentId=$agentId:
設定系統屬性 pinpoint.agentId 為 $agentId。這可能是應用程序使用的某種標識符,通常用於分佈式追蹤或性能監控。
-Dpinpoint.applicationName=member:
設定系統屬性 pinpoint.applicationName 為 member。這可能是應用程序的名稱,也用於分佈式追蹤或性能監控。
-jar:
指定後面的參數為可執行的JAR文件。在這個命令中,應用程序的主體代碼存儲在一個JAR文件中。
這些參數一般用於調整Java應用程序的性能和行為。具體的值可能需要根據應用程序的需求和硬體配置進行調整。property use list
application.yml
redis:
app:
enable: true
disableList: >
kafkaController.test,
RedisTestController.testUseRedistest.kt
@Value("\${redis.app.disableList:null}")
private var redisDisableList: List<String>? = null【SpingBoot】取得git branch
出處 : https://blog.elliot.tw/?p=658
Spring Boot可以提供的Application資訊,參考以下連結
https://docs.spring.io/spring-boot/reference/actuator/endpoints.html#actuator.endpoints.info
| ID | Name | Description | Prerequisites |
|---|---|---|---|
build |
BuildInfoContributor |
Exposes build information. | A META-INF/build-info.properties resource. |
env |
EnvironmentInfoContributor |
Exposes any property from the Environment whose name starts with info.. |
None. |
git |
GitInfoContributor |
Exposes git information. | A git.properties resource. |
java |
JavaInfoContributor |
Exposes Java runtime information. | None. |
os |
OsInfoContributor |
Exposes Operating System information. | None. |
裡面提到了git,主要就是讀取git.properties
所以只要能產生git.properties
在此有兩種方式,一個是由Maven Plugin產生,另一個則由Gradle Plugin產生
Maven – git-commit-id-maven-plugin
<plugin>
<groupId>io.github.git-commit-id</groupId>
<artifactId>git-commit-id-maven-plugin</artifactId>
<version>6.0.0</version>
<executions>
<execution>
<id>get-the-git-infos</id>
<goals>
<goal>revision</goal>
</goals>
<phase>initialize</phase>
</execution>
</executions>
<configuration>
<generateGitPropertiesFile>true</generateGitPropertiesFile> <generateGitPropertiesFilename>${project.build.outputDirectory}/git.properties</generateGitPropertiesFilename>
<commitIdGenerationMode>full</commitIdGenerationMode>
</configuration>
</plugin>Gradle – gradle-git-properties
id("com.gorylenko.gradle-git-properties") version "2.4.1"Spring Boot – Application Yaml
再來只要在managment裡加入info.git.enabled=true 即可
management:
endpoints:
web:
exposure:
include: '*'
info:
git:
enabled: true
java:
enabled: trueActuator Info
簡單透過actuator 提供的endpoint
http://localhost:8080/actuator/info
{
"git": {
"branch": "test/performance",
"commit": {
"id": "f95f360",
"time": "2024-10-25T02:09:37Z"
}
},
"build": {
"artifact": "live-show",
"name": "live-show",
"time": "2024-10-25T02:54:21.087Z",
"version": "2411.2.0",
"group": "com.momo.app"
},
"java": {
"version": "17.0.11",
"vendor": {
"name": "Amazon.com Inc.",
"version": "Corretto-17.0.11.9.1"
},
"runtime": {
"name": "OpenJDK Runtime Environment",
"version": "17.0.11+9-LTS"
},
"jvm": {
"name": "OpenJDK 64-Bit Server VM",
"vendor": "Amazon.com Inc.",
"version": "17.0.11+9-LTS"
}
}
}Kotlin
【Kotlin】data class
Data Class vs 一般 Class
-
自動生成的方法
- Data Class: Kotlin 編譯器會自動生成
equals()、hashCode()、toString()、copy()等方法。 - 一般 Class: 需要手動實現這些方法,或者使用 IDE 的插件來生成。
- Data Class: Kotlin 編譯器會自動生成
-
不可變性
- Data Class: 可以聲明為
val型,使其成員變量成為只讀。 - 一般 Class: 需要額外的設計來實現不可變性,如使用
private成員變量並提供getter方法。
- Data Class: 可以聲明為
-
Component 函数
- Data Class: Kotlin 可以通過
componentN()函數來分解對象。 - 一般 Class: 需要手動定義這些分解函數。
- Data Class: Kotlin 可以通過
自動生成的方法
在這個示例中,Person 是一個 data class,它自動獲得了 equals()、hashCode()、toString()、copy() 等方法,而一般 class,我們需要手動實現方法。
.toString()
// Data Class
data class Person(val name: String, val age: Int)
// 一般 Class
class Person2(val name: String, val age: Int)
class Person3(val name: String, val age: Int) {
override fun toString(): String {
return "Person3(name='$name', age=$age)"
}
}
fun main() {
val p1 = Person("Mary", 18)
val p2 = Person2("John", 24)
val p3 = Person3("Sam", 30)
println(p1) //Person(name=Mary, age=18)
println(p2) //Person2@27bc2616
println(p3) //Person3(name='Sam', age=30)
}.equals()
data class Person(val name: String){
var age:Int = 0
}
data class Person2(val name: String, val age:Int)
class Person3(val name: String, val age:Int){
}
class Person4(val name: String, val age:Int){
fun equals(p: Person4):Boolean{
return (this.name == p.name)
}
}
fun main() {
val jack = Person("Jack")
jack.age = 20
println(jack) // Person(name=Jack)
println(jack.age) // 20
val sam = Person("Sam")
println(sam) // Person(name=sam)
sam.age = 21
println(sam.age) // 21
println(sam.equals(jack)) // false
val oldSam = Person("Sam")
println(oldSam) // Person(name=sam)
oldSam.age = 18
println(oldSam.age) // 18
println(oldSam.equals(sam)) // true !!!
val mary = Person2("Mary",18)
val mary2 = Person2("Mary",18)
val mary3 = Person2("Mary",20)
println(mary.equals(mary2)) // true
println(mary.equals(mary3)) // false
val john = Person3("John",35)
val john2 = Person3("John",35)
println(john.equals(john2)) // false
val Jennifer = Person4("Jennifer",12)
val Jennifer2 = Person4("Jennifer",12)
println(Jennifer.equals(Jennifer2)) // true
}.copy()
data class Person(val name: String, val age: Int)
fun main() {
val jack = Person("Jack",4)
println(jack) // Person(name=Jack, age=4)
val olderJack = jack.copy(age = 9)
println(olderJack) // Person(name=Jack, age=9)
}
不可變性
- 可以聲明為
val型,使其成員變量成為只讀。
data class Person(val name: String, val age: Int)
fun main() {
val person = Person("Alice", 30)
person.name = "John" // 'val' cannot be reassigned.
}
- 一般class 需撰寫 private set
class Person {
var name: String = "Unknown"
private set // 私有的 setter
var age: Int = 0
private set // 私有的 setter
fun setName(newName: String) {
name = newName // 可以在類內部修改
}
fun setAge(newAge: Int) {
age = newAge // 可以在類內部修改
}
}
fun main() {
val person = Person()
person.setName("Mary")
person.setAge(18)
println(person.name) // Mary
println(person.age) // 18
person.name = "Mary" // Cannot access 'name': it is private in '/Person'.
}Component 函数
在 Kotlin 中,componentN() 函數是一種特殊的函數,用於解構(分解)對象。解構是一種語法糖,可以讓你將對象的屬性拆分成獨立的變量。這些函數在 data class 中是自動生成的,而在一般的 class 中則需要手動定義。
什麼是解構(Destructuring)?
解構(Destructuring)是一種語法特性,允許將對象的屬性分解成獨立的變量。這在需要從對象中提取多個值時非常有用。
Data Class 的 Component 函數
當你定義一個 data class 時,Kotlin 會自動為每個屬性生成 componentN() 函數。這些函數按照屬性在主構造函數中的聲明順序編號。例如,component1() 對應於第一個屬性,component2() 對應於第二個屬性,以此類推。
data class Person(val name: String, val age: Int)
fun main() {
val person = Person("Alice", 30)
// 使用解構聲明
val (name, age) = person
println("Name: $name, Age: $age")
// 手動調用 component 函數
val nameComponent = person.component1()
val ageComponent = person.component2()
println("Name: $nameComponent, Age: $ageComponent")
}
在這個示例中,Person 類是一個 data class,所以 Kotlin 會自動生成 component1() 和 component2() 函數。你可以使用解構聲明 val (name, age) = person 來將對象的屬性分解成獨立的變量。
一般 Class 的 Component 函數
對於一般的 class,你需要手動定義 componentN() 函數來實現解構。這意味著你需要自己編寫這些函數,以便在解構時可以使用。
class Car(val brand: String, val year: Int) {
operator fun component1() = brand
operator fun component2() = year
}
fun main() {
val car = Car("Toyota", 2022)
// 使用解構聲明
val (brand, year) = car
println("Brand: $brand, Year: $year") // 輸出:Brand: Toyota, Year: 2022
// 手動調用 component 函數
val brandComponent = car.component1()
val yearComponent = car.component2()
println("Brand: $brandComponent, Year: $yearComponent") // 輸出:Brand: Toyota, Year: 2022
}
賦值解構
val jane = User("Jane", 35)
val (name, age) = jane
println("$name, $age years of age")
// Jane, 35 years of age
javascript 也有類似功能
const user = {
name: "Jane",
age: 35,
};
// { name, age } 等同於 { name: name, age: age }
const { name, age } = user;
console.log(`${name}, ${age} years of age`)
// "Jane, 35 years of age"/**
operator 除了 componentN 函數外,operator 關鍵字還可以用於重載許多其他運算符
算術運算符
+ 對應於 plus
- 對應於 minus
* 對應於 times
/ 對應於 div
% 對應於 rem 或 mod
*/
class Show(val liveId: String, val duration: Int, val salesVolume: Int ) {
operator fun plus(show: Show): Show {
return Show(liveId, duration + show.duration, salesVolume + show.salesVolume)
}
}
fun main() {
val show1 = Show("2024071001001001P", 60, 200)
val show2 = Show("2024071001001001P", 90, 400)
val totalShow = show1 + show2 // 使用重載的加法運算符
println("(${show1.duration}, ${show1.salesVolume})") // (60, 200)
println("(${show2.duration}, ${show2.salesVolume})") // (90, 200)
println("(${totalShow.duration}, ${totalShow.salesVolume})") // (150, 200)
}建立data class注意事項
- 主構造函數必須至少有一個參數。
- 所有主要建構函數參數必須標記為
val或var。 - 資料類別不能是抽象的(abstract)、開放的(abstract)、密封的(sealed)或內部的(inner)。
- 不能直接繼承自其他
data class,但可以繼承自普通class或實作介面
- 如果data class 本身有
.equals()、.hashCode()、.toString()明確實作或父類別有的實作,則不會產生這些函數,而是使用現有的實作。 - 不允許為
.componentN()和.copy()函數提供實作。
data class toString 改用 json 輸出
導入 Gson 庫:首先需要將 Gson 添加到你的專案依賴中。
dependencies {
implementation 'com.google.code.gson:gson:2.8.8'
}覆寫toString()
import com.google.gson.Gson
data class Person(val name: String, val age:Int){
override fun toString():String{
val gson = Gson()
return gson.toJson(this)
}
}
fun main(args: Array<String>) {
val mary = Person("Mary",18)
println(mary)
}
// {"name":"Mary","age":18}
【Kotlin】getter, setter
在 Kotlin 中,getter 和 setter 是屬性的一部分,可以自動生成或由開發者自定義。與 Java 不同,Kotlin 提供了一種更簡潔和直觀的方式來定義和使用屬性。
Java 中的 Getter 和 Setter
在 Java 中,我們通常通過編寫方法來訪問和修改私有屬性:
public class Person {
private String name;
private int age;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
}
Kotlin 中的屬性訪問
在 Kotlin 中,屬性有內置的 getter 和 setter,並且這些方法是自動生成的。你可以像訪問變量一樣訪問屬性。
class Person {
var name: String = ""
var age: Int = 0
}
fun main() {
val person = Person()
person.name = "Alice" // 使用 setter 設置值
println(person.name) // 使用 getter 獲取值
person.age = 30
println(person.age)
}
自定義 Getter 和 Setter
如果需要自定義屬性的 getter 和 setter,可以使用以下語法:
class Person {
var name: String = ""
get() {
println("Getter called")
return field
}
set(value) {
println("Setter called")
field = value
}
var age: Int = 0
get() = field
set(value) {
field = if (value >= 0) value else throw IllegalArgumentException("Age cannot be negative")
}
}
fun main() {
val person = Person()
person.name = "Alice" // Setter called
println(person.name) // Getter called
person.age = 30
println(person.age)
}
在這個例子中:
field是一個後備字段,表示實際存儲屬性值的變量。- 自定義的
getter和setter可以在設置和獲取屬性值時執行額外的邏輯。
說明
-
自動生成的 Getter 和 Setter:
- 對於
var屬性,Kotlin 會自動生成默認的getter和setter。 - 對於
val屬性,Kotlin 只會生成getter,因為它是只讀的。
- 對於
-
自定義 Getter 和 Setter:
- 可以在屬性定義中使用
get()和set(value)來自定義getter和setter的行為。 - 可以添加額外的邏輯,例如日誌記錄、數據驗證等。
- 可以在屬性定義中使用
-
後備字段
field:- 在
getter和setter中使用field來引用屬性的實際存儲變量。 field只能在屬性的getter和setter中使用。
- 在
ps.後備字段(backing field)是指屬性的實際存儲值的內部字段。當你聲明一個屬性時,Kotlin 會自動幫你生成相應的 getter 和 setter 方法,同時也會生成一個用來存儲實際數據的字段,這個字段就是後備字段。
【Kotlin】enum class
宣告1: 最基礎的 neum 使用逗號分開
enum class DayOfWeek {
SUNDAY,
MONDAY,
TUESDAY,
WEDNESDAY,
THURSDAY,
FRIDAY,
SATURDAY
}
通常搭配when做狀態或是類型判斷
val day = DayOfWeek.WEDNESDAY
when(day) {
DayOfWeek.SUNDAY -> println("星期七,猴子刷油漆")
DayOfWeek.MONDAY -> println("星期一,猴子添新衣")
DayOfWeek.TUESDAY -> println("星期二,猴子肚子餓")
DayOfWeek.WEDNESDAY -> println("星期三,猴子去爬山")
DayOfWeek.THURSDAY -> println("星期四,猴子去考試")
DayOfWeek.FRIDAY -> println("星期五,猴子去跳舞")
DayOfWeek.SATURDAY -> println("星期六,猴子去斗六")
}
// 星期三,猴子去爬山宣告2: 可包含參數和屬性
例如,我們可以為每一天添加一個參數來表示它是否是工作日:
enum class DayOfWeek(val isWeekday: Boolean) {
SUNDAY(false),
MONDAY(true),
TUESDAY(true),
WEDNESDAY(true),
THURSDAY(true),
FRIDAY(true),
SATURDAY(false)
}在這個例子中,每個枚舉常量都覆寫了 activity 方法來表示該天的主要活動
enum class DayOfWeek(val isWeekday: Boolean) {
SUNDAY(false) {
override fun activity() = "Relaxing"
},
MONDAY(true) {
override fun activity() = "Working"
},
TUESDAY(true) {
override fun activity() = "Working"
},
WEDNESDAY(true) {
override fun activity() = "Working"
},
THURSDAY(true) {
override fun activity() = "Working"
},
FRIDAY(true) {
override fun activity() = "Working"
},
SATURDAY(false) {
override fun activity() = "Relaxing"
};
abstract fun activity(): String
}
println("Today is a weekday: ${today.isWeekday}")
println("Today's activity: ${today.activity()}")
for (day in DayOfWeek.values()) {
println("${day.name}: Weekday = ${day.isWeekday}, Activity = ${day.activity()}")
}判斷時可以使用enum本身,或是其屬性
enum class EDeviceType(val id: String, val label: String) {
ANDROID("0", "安卓"),
IOS("1", "iOS");
companion object {
fun sortedList(desc: Boolean): List<EDeviceType> {
return if (desc) {
entries.sortedByDescending { it.id }
} else {
entries.sortedBy { it.id }
}
}
fun ofId(id: String): EDeviceType? {
return entries.firstOrNull { it.id == id }
}
}
}
val device = EDeviceType.IOS
// 判斷
when(device.id){
"0" -> println("ANDROID")
"1" -> println("IOS")
else -> println("other")
}
when(device.label){
"安卓" -> println("ANDROID")
"iOS" -> println("IOS")
else -> println("other")
}
when(device){
EDeviceType.IOS -> println("IOS")
EDeviceType.ANDROID -> println("ANDROID")
else -> println("other")
}
println(EDeviceType.ofId("0")) //ANDROID
println(EDeviceType.sortedList(true)) //[IOS, ANDROID]enum 可撰寫方法擴充實用度
enum class ShowStatus(val id: String, val title: String, private val isPreserve: Boolean = false) {
// 馬上開播
TEMP("temp", "馬上開播暫存"),
ON_AIR("onAir", "馬上開播直播中"),
PUBLISHED("published", "馬上開播已播出"),
CANCELED("canceled", "馬上開播前user壓取消"),
STREAM_ENDED("streamEnded", "馬上開播因斷流觸發停播"),
// 預約開播
PRESERVED("preserved", "預約開播已預約", true),
PRESERVED_ON_AIR("preservedOnAir", "預約開播直播中", true),
PRESERVED_PUBLISHED("preservedPublished", "預約開播已播出", true),
PRESERVED_CANCELED("preservedCanceled", "預約開播逾時未開播觸發排程壓取消或user壓刪除", true),
PRESERVED_STREAM_ENDED("preservedStreamEnded", "預約開播因斷流觸發停播", true),
// 違規檔次
BAN("ban", "因違規停播", false);
fun isPlayable(): Boolean {
return this == TEMP || this == PRESERVED
}
fun isStoppable(): Boolean {
return this == ON_AIR || this == PRESERVED_ON_AIR
}
fun isStopped(): Boolean {
return this == PUBLISHED || this == PRESERVED_PUBLISHED
|| this == STREAM_ENDED || this == PRESERVED_STREAM_ENDED
}
fun isBan(): Boolean {
return this == BAN
}
fun toOnAir(): ShowStatus {
return if (isPreserve) PRESERVED_ON_AIR else ON_AIR
}
fun toPublished(): ShowStatus {
return if (isPreserve) PRESERVED_PUBLISHED else PUBLISHED
}
fun toCanceled(): ShowStatus {
return if (isPreserve) PRESERVED_CANCELED else CANCELED
}
fun toStreamEnded(): ShowStatus {
return if (isPreserve) PRESERVED_STREAM_ENDED else STREAM_ENDED
}
fun isCanceled(): Boolean {
return this == CANCELED || this == PRESERVED_CANCELED
}
fun isCancelable(): Boolean {
return this == TEMP || this == PRESERVED
}
companion object {
fun ofId(id: String?): ShowStatus = entries.firstOrNull { it.id == id } ?: TEMP
/**
* 已開播狀態
*/
fun ofPublished(): List<ShowStatus> = listOf(
PUBLISHED, PRESERVED_PUBLISHED, STREAM_ENDED, PRESERVED_STREAM_ENDED,
)
/**
* 開播中狀態
*/
fun ofOnAir(): List<ShowStatus> = listOf(
ON_AIR, PRESERVED_ON_AIR,
)
/**
* 待開播狀態
*/
fun ofTemp(): List<ShowStatus> = listOf(
TEMP, PRESERVED
)
}
}
enum 列舉,取值
enum class RGB { RED, GREEN, BLUE }
fun main() {
for (color in RGB.entries) println(color) // prints RED, GREEN, BLUE
println("The first color is: ${RGB.valueOf("RED")}") // prints "The first color is: RED"
}
enum class RESPONSE( val state: Int) {
SUCCESS(200),
NOT_FOUND(404),
SERVER_ERROR(500),
}
fun main{
for (response in RESPONSE.entries) {
println("Response: ${response.name}, State: ${response.state}, Ordinal: ${response.ordinal}")
}
}
// Response: SUCCESS, State: 200, Ordinal: 0
// Response: NOT_FOUND, State: 404, Ordinal: 1
// Response: SERVER_ERROR, State: 500, Ordinal: 2
參考 :
官方文件 https://kotlinlang.org/docs/enum-classes.html
【Kotlin】【Test】建立臨時單一執行class
建立新的 Kotlin class: 在你的專案中,新增一個 Kotlin class,例如 TestApplication.kt。這個 class 會擔當你的測試入口點。
import org.springframework.boot.autoconfigure.SpringBootApplication
import org.springframework.boot.runApplication
@SpringBootApplication
class TestApplication
fun main(args: Array<String>) {
runApplication<TestApplication>(*args) // 如果不需起整個專案服務,可註解
// todo
println("start test")
}-
在這個例子中,
TestApplication是一個空的 Spring Boot 應用程式,使用@SpringBootApplication標註來指示它是 Spring Boot 的主應用程式。main函式是這個 class 的入口點,通過runApplication方法來啟動 Spring Boot 應用程式。 -
配置新的啟動 class: 如果你需要使用不同的配置或環境,可以在
application.properties或application.yml中設置相應的配置,或在需要時將其傳遞給runApplication的args參數中。 -
執行測試應用程式: 當你想執行這個測試應用程式時,可以直接運行
main函式所在的 Kotlin class,它將啟動並運行你的 Spring Boot 應用程式。
這種方式可以讓你在不影響原先 Spring Boot 應用程式啟動的情況下,新增一個單獨的測試入口點。
【Kotlin】sealed class
在Kotlin 中,sealed class(密封類)是一種特殊的類,它用來表示受限的類層次結構。sealed class及其子類別的定義必須在同一個檔案中,從而確保了編譯時的類型檢查。這種類別通常用於表達某種有限數量的可能狀態或類型。以下是sealed class的一些主要特點和用途:
特點
- 受限層次結構:
sealed class的所有直接子類別必須在同一個檔案中定義,這樣可以確保在編譯時知道所有可能的子類別。 - 抽象類別:
sealed class本身是抽象的,不能直接實例化,只能透過其子類別來實例化。 - 強制列舉:在使用
when表達式時,如果覆寫了所有的子類別分支,就不需要再加else分支,這樣可以在編譯時確保列舉所有情況。
使用場景
- 需要有限的類繼承:您有一組預先定義的、有限的子類來擴展一個類,所有這些子類在編譯時都是已知的。
- 需要類型安全設計:安全性和模式匹配在您的專案中至關重要。特別是對於狀態管理或處理複雜的條件邏輯。
- 使用封閉式 API:您需要為程式庫提供強大且可維護的公共 API,以確保第三方用戶端按預期使用 API。
UI 應用程式中的狀態管理
可以使用sealed來表示應用程式中的不同 UI 狀態。
這種方法允許結構化且安全地處理 UI 變更。
此範例示範如何管理各種 UI 狀態:
sealed class UIState {
data object Loading : UIState()
data class Success(val data: String) : UIState()
data class Error(val exception: Exception) : UIState()
}
fun updateUI(state: UIState) {
when (state) {
is UIState.Loading -> showLoadingIndicator()
is UIState.Success -> showData(state.data)
is UIState.Error -> showError(state.exception)
}
}付款方式處理
實際業務應用中,高效處理各種支付方式是常見的需求。您可以使用具有when表達式的密封類別來實現此類業務邏輯。透過將不同的支付方式表示為密封類的子類,它建立了一個清晰且可管理的交易處理結構:
sealed class Payment {
data class CreditCard(val number: String, val expiryDate: String) : Payment()
data class PayPal(val email: String) : Payment()
data object Cash : Payment()
}
fun processPayment(payment: Payment) {
when (payment) {
is Payment.CreditCard -> processCreditCardPayment(payment.number, payment.expiryDate)
is Payment.PayPal -> processPayPalPayment(payment.email)
Payment.Cash -> processCashPayment()
}
}API 請求-回應處
您可以使用sealed class和密sealed interface來實作處理 API 請求和回應的使用者驗證系統。
使用者認證系統具有登入和登出功能。
介面ApiRequest定義了特定的請求類型:LoginRequest登入和LogoutRequest登出操作。sealed class ApiResponse封裝了不同的回應場景:UserSuccess使用使用者資料、UserNotFound針對缺席的使用者以及Error針對任何故障。
此handleRequest函數使用表達式以類型安全的方式處理這些請求when,同時getUserById模擬使用者檢索:
// Import necessary modules
import io.ktor.server.application.*
import io.ktor.server.resources.*
import kotlinx.serialization.*
///////////////////////////////////////////////////////////////////////////////////////
// Define the sealed interface for API requests using Ktor resources
@Resource("api")
sealed interface ApiRequest
@Serializable
@Resource("login")
data class LoginRequest(val username: String, val password: String) : ApiRequest
@Serializable
@Resource("logout")
object LogoutRequest : ApiRequest
///////////////////////////////////////////////////////////////////////////////////////
// Define the ApiResponse sealed class with detailed response types
sealed class ApiResponse {
data class UserSuccess(val user: UserData) : ApiResponse()
data object UserNotFound : ApiResponse()
data class Error(val message: String) : ApiResponse()
}
///////////////////////////////////////////////////////////////////////////////////////
// User data class to be used in the success response
data class UserData(val userId: String, val name: String, val email: String)
///////////////////////////////////////////////////////////////////////////////////////
// Function to validate user credentials (for demonstration purposes)
fun isValidUser(username: String, password: String): Boolean {
// Some validation logic (this is just a placeholder)
return username == "validUser" && password == "validPass"
}
///////////////////////////////////////////////////////////////////////////////////////
// Function to handle API requests with detailed responses
fun handleRequest(request: ApiRequest): ApiResponse {
return when (request) {
is LoginRequest -> {
// 合法使用者
if (isValidUser(request.username, request.password)) {
ApiResponse.UserSuccess(UserData("userId", "userName", "userEmail"))
} else {
ApiResponse.Error("Invalid username or password")
}
}
is LogoutRequest -> {
// Assuming logout operation always succeeds for this example
ApiResponse.UserSuccess(UserData("userId", "userName", "userEmail")) // For demonstration
}
}
}
// Function to simulate a getUserById call
fun getUserById(userId: String): ApiResponse {
return if (userId == "validUserId") {
ApiResponse.UserSuccess(UserData("validUserId", "John Doe", "john@example.com"))
} else {
ApiResponse.UserNotFound
}
// Error handling would also result in an Error response.
}
// Main function to demonstrate the usage
fun main() {
// 使用帳密登入
val loginResponse = handleRequest(LoginRequest("user", "pass"))
println(loginResponse)
// 登出
val logoutResponse = handleRequest(LogoutRequest)
println(logoutResponse)
// 檢索使用者 (存在,回應成功)
val userResponse = getUserById("validUserId")
println(userResponse)
// 檢索使用者 (不存在,回應失敗)
val userNotFoundResponse = getUserById("invalidId")
println(userNotFoundResponse)
}Java 中的 sealed 關鍵字
Java 17 引入了 sealed 類型,允許你限制哪些類可以繼承這個類。
public sealed class Shape permits Circle, Rectangle, NotAShape {
}
public final class Circle extends Shape {
private final double radius;
public Circle(double radius) {
this.radius = radius;
}
public double getRadius() {
return radius;
}
}
public final class Rectangle extends Shape {
private final double width;
private final double height;
public Rectangle(double width, double height) {
this.width = width;
this.height = height;
}
public double getWidth() {
return width;
}
public double getHeight() {
return height;
}
}
public final class NotAShape extends Shape {
}
C# 中的 sealed 關鍵字
當你將一個類別標記為 sealed 時,這意味著這個類別不能被其他類別繼承。這在需要明確表達某個類別不能被擴展時非常有用,例如當你想要保證某個類別的行為不被改變時。
public sealed class MyClass
{
public void Display()
{
Console.WriteLine("Hello from MyClass");
}
}
// 這將導致編譯錯誤,因為 MyClass 是 sealed 的
// public class DerivedClass : MyClass
// {
// }
public class Program
{
public static void Main()
{
MyClass myClass = new MyClass();
myClass.Display();
}
}
【Kotlin】seale class 與 enum 的比較
差異比較
| 特性 | Sealed Class | Enum |
|---|---|---|
| 使用情景 | 一組相關但不同的狀態或事件 | 一組固定的常量值 |
| 子類數量 | 可以有多個不同類型的子類 | 固定數量的常量 |
| 可擴展性 | 子類必須在相同文件中擴展 | 無法擴展,固定常量 |
| 狀態 | 可以有狀態(文字和屬性) | 通常是不可變的 |
| 設計靈活性 | 更靈活,可以有複雜的層次結構 | 固定簡單 |
| 安全性 | 編譯期檢查未處理的分支 | 固定選項無需額外檢查 |
enum class MachineState {
START, SLEEP, RUNNING
}
fun machineStateChecker(state: MachineState) = when (state) {
MachineState.START -> "Machine is about to start"
MachineState.SLEEP -> "Machine is sleeping"
MachineState.RUNNING -> "Machine is running"
}
fun main(argv: Array<String>) {
val machineState = MachineState.SLEEP
val state = machineStateChecker(machineState)
println("current state = $state")
//current state = Machine is sleeping
}sealed class WorkingState {
// data class
data class Finished(val result: List<String>): WorkingState()
data class ErrorHappened(val whatHappened: String): WorkingState()
// object
object Working: WorkingState()
object EmptyResult: WorkingState()
}
fun machineStatePrinting(workingState: WorkingState) {
when (workingState) {
is WorkingState.Finished -> {
if (workingState.result.isNotEmpty()) {
for ((index, text) in workingState.result.withIndex()) {
println("the ${index + 1} result is $text")
}
}
}
is WorkingState.ErrorHappened -> {
println("""
Error Occurred: reason is
${workingState.whatHappened}
""".trimIndent())
}
WorkingState.Working -> {
println("Printing machine is working...")
}
WorkingState.EmptyResult -> {
println("It's empty result.")
}
}
}
fun main(argv: Array<String>) {
val machineState =
WorkingState.Finished(
mutableListOf(
"print doc 1",
"print doc 2",
"print doc 3",
"print doc 4"
)
)
machineStatePrinting(machineState)
// the job1 result is print doc 1
// the job2 result is print doc 2
// the job3 result is print doc 3
// the job4 result is print doc 4
val secondMachineState = WorkingState.ErrorHappened("no papper")
machineStatePrinting(secondMachineState)
// Error Occurred: reason is no papper
val thirdMachineState = WorkingState.Working
machineStatePrinting(thirdMachineState)
// Printing machine is working...
}
【Kotlin】Scope functions ( run , let, apply, also, let, takeIf and takeUnless)
- 出處
- https://developer.android.com/codelabs/java-to-kotlin#0
- https://kotlinlang.org/docs/scope-functions.html
// 原寫法
val mary = Person("mary")
mary.age = 20
mary.birthplace = "NewYork"
println(mary) // name:mary, age:20, birthplace:NewYork
// 使用scope function 簡化語法加強語意
val john = Person("John") .apply {
age = 18
birthplace = "Taipei"
}
println(john) // name:John, age:18, birthplace:Taipei// Scope functions 可以做到一樣的事,只是寫法不同
// 印出 list 字元長度大於3 的資料
// let, also, run, apply, with
fun main() {
val numbers = mutableListOf("one", "two", "three", "four", "five")
// [3, 3, 5, 4, 4]
// it代表自己
numbers.map { it.length }.filter { it > 3 }.let {
println(it)
}
// 命名(item)代表自己
numbers.map { it.length }.filter { it > 3 }.let { item ->
println(item)
}
// it代表自己
numbers.map { it.length }.filter { it > 3 }.also {
println(it)
}
// 命名(item)代表自己
numbers.map { it.length }.filter { it > 3 }.also { item ->
println(item)
}
// this代表自己
numbers.map { it.length }.filter { it > 3 }.run {
println(this)
}
// this代表自己
numbers.map { it.length }.filter { it > 3 }.apply {
println(this)
}
// this代表自己
val gt3Numbers = numbers.map { it.length }.filter { it > 3 }
with(gt3Numbers){
println(this)
}
}
// 結果都是 [5, 4, 4][官方]判斷如何使用何種function

|
功能 |
物件引用 |
傳回值 |
是擴充函數 |
|
|---|---|---|---|---|
|
|
|
Lambda result |
Yes |
使用這個物件,做以下操作,並返回最後一個操作 |
|
|
|
Lambda result |
Yes |
lambda 同時初始化對象和計算返回值 |
|
|
- |
Lambda result |
否:在沒有上下文物件的情況下調用 |
運行代碼塊並計算結果(lambda) |
|
|
|
Lambda result |
否:將上下文物件作為參數。 |
使用這個物件,做以下操作 |
|
|
|
Context object |
Yes |
將以下賦值應用到物件上 |
|
|
|
Context object |
Yes |
並且還可以對該物件執行以下操作 |
| 回傳值 \ 傳入參考物件 | this | lambda(it) |
| this |
apply |
also |
| bock return (回傳最後一行結果) | run | let |
- 對不可為 null 的物件執行 lambda:let
- 在局部範圍內引入表達式作為變數:let
- 物件配置:apply
- 物件配置和計算結果(初始化物件):run
- 在需要表達式的地方運行語句(lambda):非擴展run
- 附加效果:also
- 將物件的函數進行分組呼叫(Grouping function calls on an objec):with
差異
- 他們引用上下文物件(Context object)的方式。
- 他們的返回值。
fun main() {
val str = "Hello"
// this
str.run {
println("The string's length: $length")
//println("The string's length: ${this.length}") // does the same
}
// it
str.let {
println("The string's length is ${it.length}")
}
}this
run、with、 並透過關鍵字apply引用上下文物件作為 lambda接收器this。因此,在它們的 lambda 中,物件就像在普通類別函數中一樣可用。
val adam = Person("Adam")
.apply {
age = 20 // same as this.age = 20
city = "London"
}
println(adam)it
反過來說,let 和 also 會將上下文對象作為 lambda 參數引用。如果沒有指定參數名稱,則會使用默認名稱 it 來訪問對象。it 比 this 短,並且使用 it 的表達式通常更易於閱讀。
然而,當調用對象的函數或屬性時,你無法像使用 this 一樣隱式地獲取對象。因此,當對象主要用作函數調用中的參數時,通過 it 訪問上下文對象更好。如果在代碼塊中使用多個變量,使用 it 也是更好的選擇。
fun getRandomInt(): Int {
return Random.nextInt(100).also {
writeToLog("getRandomInt() generated value $it")
}
}
val i = getRandomInt()
println(i)
// INFO: getRandomInt() generated value 78
// 78value 的 lambda 參數引用:fun getRandomInt(): Int {
return Random.nextInt(100).also { value ->
writeToLog("getRandomInt() generated value $value")
}
}
val i = getRandomInt()
println(i)
// INFO: getRandomInt() generated value 4
// 4傳回值
上下文對象 (Context object)
apply 和 also 的返回值是上下文對象本身。因此,它們可以作為副步驟包含在調用鏈中:你可以在同一對象上連續調用函數。val numberList = mutableListOf<Double>()
numberList.also { println("Populating the list") }
.apply {
add(2.71)
add(3.14)
add(1.0)
}
.also { println("Sorting the list") }
.sort()fun getRandomInt(): Int {
return Random.nextInt(100).also {
writeToLog("getRandomInt() generated value $it")
}
}
val i = getRandomInt()Lambda result
let、run 和 with 返回的是 lambda 表達式的結果。因此,你可以在將結果賦值給變量、在結果上鏈式操作等情況下使用它們。val numbers = mutableListOf("one", "two", "three")
val countEndsWithE = numbers.run {
add("four")
add("five")
count { it.endsWith("e") }
}
println("There are $countEndsWithE elements that end with e.")
// There are 3 elements that end with e.val numbers = mutableListOf("one", "two", "three")
with(numbers) {
val firstItem = first()
val lastItem = last()
println("First item: $firstItem, last item: $lastItem")
}
// First item: one, last item: threeFunctions
let
- 上下文物件可用作參數 (it)。
- 傳回值是 lambda 結果。
在代碼中,let 可以理解為“使用這個物件,做以下操作,並返回最後一個操作”
val numbers = mutableListOf("one", "two", "three", "four", "five")
val resultList = numbers.map { it.length }.filter { it > 3 }
println(resultList)
// [5, 4, 4]val numbers = mutableListOf("one", "two", "three", "four", "five")
numbers.map { it.length }.filter { it > 3 }.let {
println(it)
// and more function calls if needed
}
// [5, 4, 4]val numbers = mutableListOf("one", "two", "three", "four", "five")
numbers.map { it.length }.filter { it > 3 }.let(::println)
// [5, 4, 4]let 通常用於執行包含非空值的代碼塊。要對非空對象執行操作,可以使用安全調用運算符 ?.,並在其 lambda 中調用 let 來執行操作。
val str: String? = "Hello"
//processNonNullString(str) // compilation error: str can be null
val length = str?.let {
println("let() called on $it")
processNonNullString(it) // OK: 'it' is not null inside '?.let { }'
it.length
}let 引入具有有限作用域的局部變量,以使你的代碼更易於閱讀。要為上下文對象定義一個新變量,可以將其名稱作為 lambda 參數提供,這樣它可以代替默認的 it 使用。val numbers = listOf("one", "two", "three", "four")
val modifiedFirstItem = numbers.first().let { firstItem ->
println("The first item of the list is '$firstItem'")
if (firstItem.length >= 5) firstItem else "!" + firstItem + "!"
}.uppercase()
println("First item after modifications: '$modifiedFirstItem'")
// The first item of the list is 'one'
// First item after modifications: '!ONE!'with
- 上下文物件可用作接收器 (this)。
- 傳回值是 lambda 結果。
由於 with 不是擴展函數:上下文對象作為參數傳遞,但在 lambda 內部,它可以作為接收者 (this) 使用。
我們建議在不需要返回結果時使用 with 來調用上下文對象上的函數。
在代碼中,with 可以理解為“使用這個對象,做以下操作。”
val numbers = mutableListOf("one", "two", "three")
with(numbers) {
println("'with' is called with argument $this")
println("It contains $size elements")
}
// 'with' is called with argument [one, two, three]
// It contains 3 elementswith 引入一個輔助對象,其屬性或函數用於計算值。val numbers = mutableListOf("one", "two", "three")
val firstAndLast = with(numbers) {
"The first element is ${first()}," +
" the last element is ${last()}"
}
println(firstAndLast)run
- 上下文物件可用作接收器 (this)。
- 傳回值是 lambda 結果。
run 的功能與 with 相似,但它是作為擴展函數實現的。因此,像 let 一樣,你可以使用點符號在上下文對象上調用它。
run 當你的 lambda 同時初始化對象和計算返回值時非常有用。
val service = MultiportService("https://example.kotlinlang.org", 80)
val result = service.run {
port = 8080
query(prepareRequest() + " to port $port")
}
// the same code written with let() function:
val letResult = service.let {
it.port = 8080
it.query(it.prepareRequest() + " to port ${it.port}")
}
// Result for query 'Default request to port 8080'
// Result for query 'Default request to port 8080'你也可以以非擴展函數的形式調用 run。非擴展變體的 run 沒有上下文對象,但仍然返回 lambda 的結果。非擴展 run 允許你在需要表達式的地方執行多個語句的代碼塊。在代碼中,非擴展 run 可以理解為“運行代碼塊並計算結果。”
val hexNumberRegex = run {
val digits = "0-9"
val hexDigits = "A-Fa-f"
val sign = "+-"
Regex("[$sign]?[$digits$hexDigits]+")
}
for (match in hexNumberRegex.findAll("+123 -FFFF !%*& 88 XYZ")) {
println(match.value)
}
// +123
// -FFFF
// 88val getHexNumberRegex: () -> Regex = {
val digits = "0-9"
val hexDigits = "A-Fa-f"
val sign = "+-"
return Regex("[$sign]?[$digits$hexDigits]+")
}
apply
- 上下文物件可用作接收器 (this)。
- 傳回值是物件本身。
apply 返回上下文對象本身,因此建議在不返回值的代碼塊中使用它,並且主要操作接收者對象的成員。apply 的最常見用例是對對象進行配置。這類調用可以理解為“將以下賦值應用到物件上。”val adam = Person("Adam").apply {
age = 32
city = "London"
}
println(adam)
// Person(name=Adam, age=32, city=London)另一個 apply 的使用場景是將其包含在多個調用鏈中以進行更複雜的處理。
data class Address(var street: String = "", var city: String = "")
data class Person(var name: String = "", var address: Address = Address())
val person = Person().apply {
name = "Alice"
address = Address().apply {
street = "123 Main St"
city = "Wonderland"
}
}
println(person) // Output: Person(name=Alice, address=Address(street=123 Main St, city=Wonderland))
在這個例子中,我們使用 apply 配置 Person 對象的屬性,並在內部使用另一個 apply 來配置 Address 對象。這樣的鏈式調用使得代碼結構更清晰,易於維護。
also
- 上下文物件可用作參數 (it)。
- 傳回值是物件本身。
also 對於執行一些需要上下文對象作為參數的操作非常有用。使用 also 用於那些需要對象引用而不是其屬性和函數的情況,或者當你不想影響外部作用域的 this 參考時。val numbers = mutableListOf("one", "two", "three")
numbers
.also { println("The list elements before adding new one: $it") }
.add("four")
// The list elements before adding new one: [one, two, three]takeIf and takeUnless
takeIf 和 takeUnless 是 Kotlin 標準庫中的函數,允許你在調用鏈中嵌入對對象狀態的檢查。
當對一個對象調用 takeIf 並傳遞一個條件時,如果該對象滿足該條件,則返回這個對象;否則返回 null。因此,takeIf 是針對單個對象的過濾函數。
val number = Random.nextInt(100)
val evenOrNull = number.takeIf { it % 2 == 0 }
val oddOrNull = number.takeUnless { it % 2 == 0 }
println("even: $evenOrNull, odd: $oddOrNull")
// even: 62, odd: null在使用 takeIf 和 takeUnless 之後鏈式調用其他函數時,請不要忘記執行空值檢查或使用安全調用運算符 ?.,因為它們的返回值是可為空的。
val str = "Hello"
val caps = str.takeIf { it.isNotEmpty() }?.uppercase()
//val caps = str.takeIf { it.isNotEmpty() }.uppercase() //compilation error
println(caps)
// HELLOtakeIf 和 takeUnless 與作用域函數結合使用時特別有用。例如,你可以將 takeIf 和 takeUnless 與 let 鏈式調用,以便在符合給定條件的對象上執行代碼塊。具體來說,先對對象調用 takeIf,然後使用安全調用(?.)調用 let。對於不符合條件的對象,takeIf 會返回 null,因此 let 不會被調用。
fun displaySubstringPosition(input: String, sub: String) {
input.indexOf(sub).takeIf { it >= 0 }?.let {
println("The substring $sub is found in $input.")
println("Its start position is $it.")
}
}
displaySubstringPosition("010000011", "11")
displaySubstringPosition("010000011", "12")
// The substring 11 is found in 010000011.
// Its start position is 7.以下是一個示例,展示如何在不使用 takeIf 或作用域函數的情況下編寫相同的功能:
fun displaySubstringPosition(input: String, sub: String) {
val index = input.indexOf(sub)
if (index >= 0) {
println("The substring $sub is found in $input.")
println("Its start position is $index.")
}
}
displaySubstringPosition("010000011", "11")
displaySubstringPosition("010000011", "12")
// The substring 11 is found in 010000011.
// Its start position is 7.
【kotlin】Inline functions (官方文件翻譯)
出處 https://kotlinlang.org/docs/inline-functions.html
使用高階函式會帶來某些執行時期的負擔:每個函式都是一個物件,而且會捕捉到閉包。閉包是可以在函式內部存取的變數範圍。記憶體配置(包括函式物件和類別的配置)以及虛擬呼叫都會引入執行時期的額外負擔。
但在許多情況下,這種額外負擔可以通過內聯化 lambda 表達式來消除。以下展示的函式就是這種情況的好例子。lock() 函式可以很容易地在呼叫點內聯化。請考慮以下情況:
lock(l) { foo() }與其為參數創建一個函式物件並生成呼叫,編譯器可以發出以下程式碼:
l.lock()
try {
foo()
} finally {
l.unlock()
}要讓編譯器這樣做,可以使用 inline 修飾符標記 lock() 函式:
inline fun <T> lock(lock: Lock, body: () -> T): T { ... }inline 修飾符會影響函式本身和傳遞給它的 lambda 表達式:所有這些都會內聯到呼叫點。
內聯可能會導致生成的程式碼變大。然而,如果合理地進行內聯(避免內聯大型函式),在效能方面將會有顯著的提升,特別是在迴圈內的“多態性”呼叫點。
noinline
如果你不希望傳遞給內聯函式的所有 lambda 表達式都被內聯,可以使用 noinline 修飾符標記部分函式參數:
inline fun foo(inlined: () -> Unit, noinline notInlined: () -> Unit) { ... }可內聯的 lambda 表達式只能在內聯函式內被呼叫,或作為可內聯的參數傳遞。然而,使用 noinline 修飾符的 lambda 表達式則可以以任何方式操作,包括儲存在欄位中或傳遞。
@Suppress("NOTHING_TO_INLINE") 註解來抑制這個警告)。non-local returns 非本地返回
fun foo() {
ordinaryFunction {
return // ERROR: cannot make `foo` return here
}
}fun foo() {
inlined {
return // OK: the lambda is inlined
}
}這種在 lambda 內部但退出包含函式的返回稱為非本地返回。這種構造通常出現在循環中,而內聯函式通常會包裹這樣的循環。
fun hasZeros(ints: List<Int>): Boolean {
ints.forEach {
if (it == 0) return true // returns from hasZeros
}
return false
}注意,一些內聯函式可能會從不同的執行上下文(如局部物件或巢狀函式)而不是直接從函式主體內調用作為參數傳遞給它們的 lambda。在這種情況下,lambda 中也不允許非本地控制流。為了指示內聯函式的 lambda 參數不能使用非本地返回,可以使用 crossinline 修飾符來標記 lambda 參數:
inline fun f(crossinline body: () -> Unit) {
val f = object: Runnable {
override fun run() = body()
}
// ...
}break 和 continue 在內聯 lambda 中目前還不可用,但我們計劃未來也支援它們。
Reified type parameters 具現化(reified)型別參數
有時你需要訪問作為參數傳遞的型別:
fun <T> TreeNode.findParentOfType(clazz: Class<T>): T? {
var p = parent
while (p != null && !clazz.isInstance(p)) {
p = p.parent
}
@Suppress("UNCHECKED_CAST")
return p as T?
}這裡,你遍歷一棵樹並使用反射來檢查節點是否具有某種類型。這一切都很好,但呼叫點並不十分美觀:
treeNode.findParentOfType(MyTreeNode::class.java)更好的解決方案是直接將型別作為參數傳遞給這個函式。你可以這樣調用它:
treeNode.findParentOfType<MyTreeNode>()為了實現這一點,內聯函式支持具現化(reified)型別參數,因此你可以這樣寫:
inline fun <reified T> TreeNode.findParentOfType(): T? {
var p = parent
while (p != null && p !is T) {
p = p.parent
}
return p as T?
}上述代碼使用 reified 修飾符來賦予型別參數在函式內部可訪問的能力,幾乎就像它是一個普通的類別一樣。由於函式被內聯,不需要使用反射,並且現在你可以使用像 !is 和 as 這樣的普通操作符。同時,你可以像上面展示的那樣調用這個函式:myTree.findParentOfType<MyTreeNodeType>()。
雖然在許多情況下不需要使用反射,但你仍然可以使用具現化(reified)型別參數來使用它:
inline fun <reified T> membersOf() = T::class.members
fun main(s: Array<String>) {
println(membersOf<StringBuilder>().joinToString("\n"))
}普通函式(未標記為內聯)不能具有具現化(reified)參數。沒有運行時表示(例如非具現化的型別參數或類似 Nothing 的虛構型別)的型別不能作為具現化型別參數的參數。
Inline prperties
在 Kotlin 中,inline 修飾符確實可以用於沒有後端字段的屬性的訪問器上。你可以為個別的屬性訪問器添加註解:
val foo: Foo
inline get() = Foo()
var bar: Bar
get() = ...
inline set(v) { ... }你也可以對整個屬性進行註解,這將使其所有的訪問器都標記為內聯:
inline var bar: Bar
get() = ...
set(v) { ... }在呼叫處,內聯訪問器會像普通的內聯函式一樣被內聯。
restrictions for public API inline functions
公共 API 的內聯函式限制
當內聯函式是公共或受保護的,但不屬於私有或內部聲明的一部分時,它被視為模組的公共 API。它可以在其他模組中被調用並且在這些調用點被內聯。然而,這會帶來二進制不兼容性的風險,如果調用模組在聲明模組變更後未重新編譯。
為了消除由模組的非公共 API 變更引入的這種不兼容性風險,公共 API 的內聯函式不允許在其內部使用非公共 API 的聲明(私有和內部)。
內部聲明可以使用 @PublishedApi 注解,這允許它在公共 API 的內聯函式中使用。當內部的內聯函式標記為 @PublishedApi 時,其函式體被視為公共,並且受到與公共函式相同的可見性限制和檢查。
【kotlin】因為需要 < reified T> 取得泛型型別,所以從 inline functions 開始
參考:
https://kotlinlang.org/docs/inline-functions.html
泛型基礎 (三) — Java 與 Kotlin 向下相容、Type Erasure 和 Reifiable
Inline functions - Kotlin Vocabulary
Kotlin 的 inline、noinline、crossline function
從Type Erasure 開始
型別擦除(Type Erasure)是 JVM 泛型的一個特性,在執行時會移除泛型型別資訊。這意味著在編譯後,所有的泛型型別資訊都會被擦除,導致在運行時無法直接訪問或判斷泛型的具體型別。
型別擦除的原因
型別擦除的主要原因是為了保持向後兼容性。Java 在設計泛型時,需要確保編譯後的程式碼能夠在不支持泛型的 JVM 上運行。通過在編譯時檢查型別並在運行時擦除泛型資訊,Java 能夠確保新舊版本的兼容性。
型別擦除的影響
型別擦除會導致一些限制和問題,包括:
1.運行時無法獲取泛型資訊:
-
- 由於型別資訊在運行時被擦除,無法在運行時獲取泛型的具體型別。例如:
fun <T> checkType(obj: T) {
val button = "Btn String"
if (button is T) { // 編譯會失敗
println("it's String")
}
}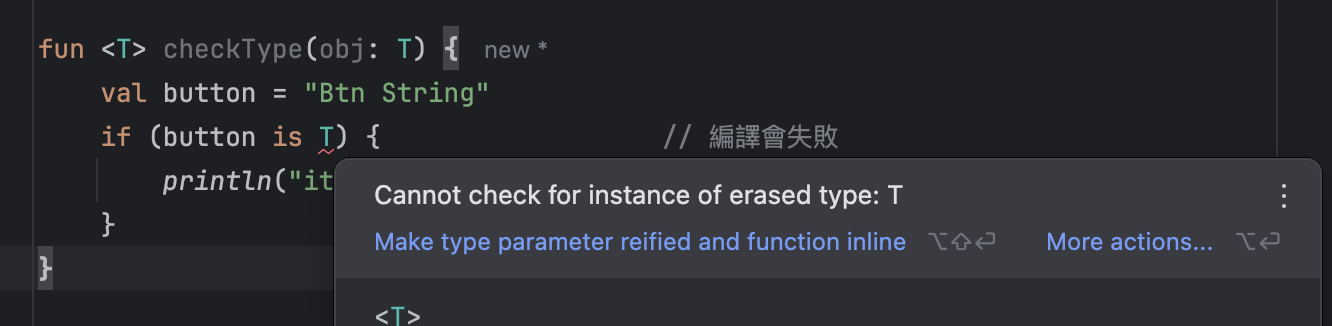
2.型別轉換的警告:
- 在編譯時會產生未經檢查的型別轉換警告,因為編譯器無法完全確保型別的安全性。
val rawList: List<*> = ArrayList<Any>()
val stringList: List<String> = rawList as List<String> // 未經檢查的型別轉換警告
3.創建泛型型別的實例:
- 由於運行時無法確定泛型的具體型別,無法直接創建泛型型別的實例。
class MyClass<T> {
fun createInstance(): T {
return T() // 錯誤,無法創建泛型型別的實例
}
}型別擦除的工作原理
型別擦除的工作原理如下:
替換泛型參數:
- 在編譯時,編譯器會用它們的邊界(上限)替換泛型參數。如果沒有明確的邊界,則使用
Object作為默認邊界。例如,List<T>會被替換為List<Object>。
插入型別檢查和轉換:
- 在編譯後的程式碼中插入型別檢查和轉換,以確保在運行時的型別安全。例如:
List<String> stringList = new ArrayList<>();
stringList.add("Hello");
String str = stringList.get(0); // 編譯後,將插入型別轉換 (String)
克服型別擦除的方法
在某些情況下,可以使用以下方法克服型別擦除的限制:
傳遞型別參數:
- 可以通過傳遞
Class<T>或TypeToken<T>來保留型別資訊。
public <T> T createInstance(Class<T> clazz) throws InstantiationException, IllegalAccessException {
return clazz.newInstance();
}
使用反射:
-
- 使用反射可以在運行時獲取一些泛型資訊,儘管這可能會變得複雜且難以維護。
import java.lang.reflect.ParameterizedType
import java.lang.reflect.Type
// 定義一個泛型類
class GenericClass<T>
// 繼承泛型類並指定具體的泛型型別
class StringGenericClass : GenericClass<String>()
fun main() {
// 創建一個 StringGenericClass 的實例
val instance = StringGenericClass()
// 獲取泛型類的超類型(即 GenericClass<String>)
val superclass: Type = instance::class.java.genericSuperclass
if (superclass is ParameterizedType) {
// 獲取泛型參數的型別(即 String)
val actualTypeArgument = superclass.actualTypeArguments[0]
println("泛型參數的型別是:${actualTypeArgument.typeName}")
} else {
println("無法獲取泛型參數的型別")
}
}
Kotlin 的 reified 型別參數:
-
- 在 Kotlin 中,使用
reified關鍵字來保留泛型型別資訊,以便在運行時可以訪問這些資訊。
- 在 Kotlin 中,使用
使用 reidied 必須使用 inline function
所以...
inline function
在 Kotlin 中,使用 inline 修飾符可以將函式的內容插入到每一個函式呼叫的地方,而不是像普通函式那樣進行函式調用。這樣做可以減少函式調用帶來的開銷,特別是當函式體非常簡單且多次調用時,有助於提升程式的執行效能。
// 原本的function 在呼叫到hello() 會去hello 執行內部 println 動作
fun main(args: Array<String>) {
hello()
}
fun hello() {
println("Hello World !!")
}
/**
* inline functino (加了inline)
* 編譯時會將hello 內容插入呼叫位置
*/
fun main(args: Array<String>) {
println("Hello World !!") // <- 將hello 內容插入
}
inline fun hello() {
println("Hello World !!")
}
也可以使用 lambda
fun main(args: Array<String>) {
todo{
println("hello world")
}
}
inline fun todo(doSomeThing:()->Unit) {
doSomeThing()
}以下是使用 inline 修飾符的一些特點和注意事項:
-
函式內容插入:被標記為
inline的函式在被調用時,其函式體內的程式碼會被直接插入到呼叫處,而不是進行常規的函式調用。 -
減少函式調用開銷:這樣做可以減少函式調用帶來的堆疊和參數傳遞開銷,特別是對於一些簡單的函式,可以有效提升執行效能。
-
限制和注意事項:由於內聯函式將函式體內容插入到每一個呼叫點,所以函式體內不能使用非公共 API 的聲明(如私有或內部聲明)。這是為了避免在模組之間的二進制不兼容性問題。
總結來說,Kotlin 中的內聯函式是一種提高執行效能的機制,特別適合於一些較短和簡單的函式,可以有效地減少函式調用的開銷。
有時你需要訪問作為參數傳遞的型別:
fun <T> TreeNode.findParentOfType(clazz: Class<T>): T? {
var p = parent
while (p != null && !clazz.isInstance(p)) {
p = p.parent
}
// 沒有reified 會發出警告用下面這行消除
@Suppress("UNCHECKED_CAST")
return p as T?
}// 所以會長得像這樣
treeNode.findParentOfType(MyTreeNode::class.java)更好的解決方案是直接將型別作為參數傳遞給這個函式。你可以這樣調用它:
treeNode.findParentOfType<MyTreeNode>()為了實現這一點,內聯函式支持具現化(reified)型別參數,因此你可以這樣寫:
inline fun <reified T> TreeNode.findParentOfType(): T? {
var p = parent
while (p != null && p !is T) {
p = p.parent
}
return p as T?
}inline fun <reified T> example(value: T) {
// 在函式內部可以使用 T 的真實類型信息
println("Type of value is: ${T::class.simpleName}")
}
fun main() {
example(42) // 調用時傳入 Int
example("Hello") // 調用時傳入 String
}
// Type of value is: Int
// Type of value is: String
private inline fun <reified T : BaseEntity> gsonProcessAndSaveMongodb(
value: String,
repo: MongoRepository<T, *>
): T {
val data: T = gson.fromJson(value, T::class.java)
logger.info("{} data is {}", T::class.simpleName, data)
repo.save(data)
return data
}
////////////////////////////////////////////////////////////////
val topic: String = record.topic()
val key: String = removeRandomKey(record.key())
val value: String = record.value()
when (key) {
APP_LIVE_USER -> {
gsonProcessAndSaveMongodb(value, appLiveUserRepo)
}
APP_LIVE_PAGE_VIEW -> {
gsonProcessAndSaveMongodb(value, appLivePageViewRepo)
}
.....
}特點和優點
使用 reified 型別參數有幾個主要優點:
- 運行時類型資訊:通過
reified,函式內部可以獲取到泛型型別的實際類型資訊,例如使用T::class可以獲取到T的KClass對象。 - 簡化語法:不需要額外的類型轉換或者反射操作,使得程式碼更加清晰和簡潔。
- 效能:因為函式是內聯的,且使用了
reified型別,編譯器可以在編譯時期進行更多的優化,而無需在運行時進行額外的操作。
注意事項
使用 reified 型別參數有一些限制和注意事項:
- 只能用於內聯函式中,因為它需要編譯器能夠直接插入泛型實體化的程式碼。
- 只能在函式內部使用
T::class或類似的語法來獲取泛型型別的類型資訊,無法在函式外部進行操作。 reified型別參數僅限於函式內部,不影響函式的參數或返回類型的宣告。
總結來說,reified 型別參數是 Kotlin 中一個強大的功能,用於在泛型程式碼中取得運行時類型資訊,提升了程式碼的靈活性和效能。
noinline
如果有多個參數,不想被inline 可以使用關鍵字 noinline
fun main(args: Array<String>) {
todo({
println("hello world")
},{
println("hello world2")
})
}
inline fun todo(
doSomeThing:()->Unit,
noinline doSomeThing2:()->Unit
) {
doSomeThing()
doSomeThing2()
}crossinline
inline functtion 使用 return 會有意想不到的狀況,可使用 crossinline 強迫使用 return@XXX 退出
fun main(args: Array<String>) {
todo({
println("hello world")
return // 因為使用inline,return 後以下不會執行
},{
println("hello world2")
})
}
inline fun todo(
doSomeThing:()->Unit,
doSomeThing2:()->Unit
) {
doSomeThing()
doSomeThing2()
}
// hello world
fun main(args: Array<String>) {
todo({
println("hello world")
return@todo // 使用crossinline 會強迫使用 return@{function name} 跳出
},{
println("hello world2")
})
}
inline fun todo(
crossinline doSomeThing:()->Unit,
doSomeThing2:()->Unit
) {
doSomeThing()
doSomeThing2()
}
// hello world
// hello world2
Scope function 就是使用 inline function
@kotlin.internal.InlineOnly
表示這個函式是一個內聯函式,但它只能在 Kotlin 標準函式庫內部使用。這個註解通常用於指示編譯器只將這個函式內聯化,而不生成實際的函式調用。
let
val str: String? = "Hello"
//processNonNullString(str) // compilation error: str can be null
val length = str?.let {
println("let() called on $it")
it.length
}
println(length) // 5inline fun <T, R> T.let(block: (T) -> R): R 函式定義:
inline fun:這表示let函式是一個內聯函式,其函式體會被內聯到每一個函式調用處。<T, R>:這是泛型參數列表。T表示函式調用的對象的類型,而R表示block函式的返回類型。T.let(block: (T) -> R):這是函式的簽名。它擁有一個block參數,這個block是一個接受T類型參數並返回R類型的函數。: R:函式的返回類型是R,即block函式的返回值類型。
/**
* Calls the specified function [block] with `this` value as its argument and returns its result.
*
* For detailed usage information see the documentation for [scope functions](https://kotlinlang.org/docs/reference/scope-functions.html#let).
*/
@kotlin.internal.InlineOnly
public inline fun <T, R> T.let(block: (T) -> R): R {
contract {
callsInPlace(block, InvocationKind.EXACTLY_ONCE)
}
return block(this)
}apply
val john = Person("John") .apply {
age = 18
birthplace = "Taipei"
}
println(john) // name:John, age:18, birthplace:Taipeiinline fun <T> T.apply(block: T.() -> Unit): T 函式定義:
inline fun:這表示apply函式是一個內聯函式,其函式體會被內聯到每一個函式調用處。<T>:這是一個泛型參數,表示函式可以操作任意類型T的對象。T.apply(block: T.() -> Unit):這是函式的簽名。它接受一個名為block的參數,這個block是一個以T類型的接收者(receiver)為上下文的函數型參數,沒有任何輸入,並且沒有返回值 (Unit)。: T:函式的返回類型是T,也就是函式調用的對象本身。
/**
* Calls the specified function [block] with `this` value as its receiver and returns `this` value.
*
* For detailed usage information see the documentation for [scope functions](https://kotlinlang.org/docs/reference/scope-functions.html#apply).
*/
@kotlin.internal.InlineOnly
public inline fun <T> T.apply(block: T.() -> Unit): T {
contract {
callsInPlace(block, InvocationKind.EXACTLY_ONCE)
}
block()
return this
}
/**
* Calls the specified function [block] and returns its result.
*
* For detailed usage information see the documentation for [scope functions](https://kotlinlang.org/docs/reference/scope-functions.html#run).
*/
@kotlin.internal.InlineOnly
public inline fun <R> run(block: () -> R): R {
contract {
callsInPlace(block, InvocationKind.EXACTLY_ONCE)
}
return block()
}
/**
* Calls the specified function [block] with `this` value as its receiver and returns its result.
*
* For detailed usage information see the documentation for [scope functions](https://kotlinlang.org/docs/reference/scope-functions.html#run).
*/
@kotlin.internal.InlineOnly
public inline fun <T, R> T.run(block: T.() -> R): R {
contract {
callsInPlace(block, InvocationKind.EXACTLY_ONCE)
}
return block()
}
/**
* Calls the specified function [block] with the given [receiver] as its receiver and returns its result.
*
* For detailed usage information see the documentation for [scope functions](https://kotlinlang.org/docs/reference/scope-functions.html#with).
*/
@kotlin.internal.InlineOnly
public inline fun <T, R> with(receiver: T, block: T.() -> R): R {
contract {
callsInPlace(block, InvocationKind.EXACTLY_ONCE)
}
return receiver.block()
}
/**
* Calls the specified function [block] with `this` value as its receiver and returns `this` value.
*
* For detailed usage information see the documentation for [scope functions](https://kotlinlang.org/docs/reference/scope-functions.html#apply).
*/
@kotlin.internal.InlineOnly
public inline fun <T> T.apply(block: T.() -> Unit): T {
contract {
callsInPlace(block, InvocationKind.EXACTLY_ONCE)
}
block()
return this
}
/**
* Calls the specified function [block] with `this` value as its argument and returns `this` value.
*
* For detailed usage information see the documentation for [scope functions](https://kotlinlang.org/docs/reference/scope-functions.html#also).
*/
@kotlin.internal.InlineOnly
@SinceKotlin("1.1")
public inline fun <T> T.also(block: (T) -> Unit): T {
contract {
callsInPlace(block, InvocationKind.EXACTLY_ONCE)
}
block(this)
return this
}
/**
* Calls the specified function [block] with `this` value as its argument and returns its result.
*
* For detailed usage information see the documentation for [scope functions](https://kotlinlang.org/docs/reference/scope-functions.html#let).
*/
@kotlin.internal.InlineOnly
public inline fun <T, R> T.let(block: (T) -> R): R {
contract {
callsInPlace(block, InvocationKind.EXACTLY_ONCE)
}
return block(this)
}
【Kotlin】Pair
Pair
在 Kotlin 中,Pair 是一個用於表示一對相關數據的數據結構。Pair 是一個簡單的二元組,包含兩個值,這兩個值可以是不同類型的。Pair 類的主要目的是為了方便存儲和傳遞成對的數據。
創建 Pair
你可以使用 Pair 類的構造函數來創建一個 Pair 對象。構造函數接受兩個參數,分別對應 first 和 second 值。
val pair = Pair("Hello", 42)
println(pair.first) // 輸出: Hello
println(pair.second) // 輸出: 42
Kotlin 也提供了一個方便的中綴函數 to,它可以用來創建一個 Pair 對象。這使得創建 Pair 更加簡潔。
val pair = "Hello" to 42
println(pair.first) // 輸出: Hello
println(pair.second) // 輸出: 42
使用 Pair
Pair 可以用於各種場景,比如返回多個值的函數,或者需要將兩個相關數據存儲在一起的情況。
// 函數返回一個 Pair
fun getPersonInfo(): Pair<String, Int> {
return "Alice" to 30
}
val personInfo = getPersonInfo()
println("Name: ${personInfo.first}, Age: ${personInfo.second}")
// 輸出: Name: Alice, Age: 30
Pair 在 Map 中的應用
Pair 在處理 Map 時非常有用。例如,你可以使用 Pair 來初始化一個 Map,或者在操作 Map 時使用 Pair。
val map = mapOf("one" to 1, "two" to 2, "three" to 3)
println(map) // 輸出: {one=1, two=2, three=3}
// 使用 Pair 更新 Map
val updatedMap = map + ("four" to 4)
println(updatedMap) // 輸出: {one=1, two=2, three=3, four=4}
解構 Pair
Kotlin 提供了解構聲明,這使得從 Pair 中提取數據變得更加簡單。
val (name, age) = getPersonInfo()
println("Name: $name, Age: $age")
// 輸出: Name: Alice, Age: 30
Pair 類的其他方法
Pair 類還提供了一些其他有用的方法,比如 toString()、equals() 和 hashCode(),這些方法可以讓你更方便地使用 Pair。
val pair1 = "Hello" to 42
val pair2 = Pair("Hello", 42)
println(pair1.toString()) // 輸出: (Hello, 42)
println(pair1 == pair2) // 輸出: true
println(pair1.hashCode()) // 輸出: 依據具體實現的哈希值
總的來說,Pair 是一個簡單但功能強大的數據結構,適合用於存儲和操作成對的數據。在 Kotlin 中,Pair 的使用非常直觀且方便。
【Kotlin】Collections (官方文件)
來源: https://kotlinlang.org/docs/collections-overview.html
Collections overview
Kotlin標準庫提供了一套全面的工具來管理集合——這些集合是問題解決中重要且經常操作的變數數量(可能為零)的項目群組。
集合是大多數編程語言中的常見概念,所以如果你熟悉例如Java或Python的集合,可以跳過這個介紹,直接進入詳細章節。
一個集合通常包含相同類型(及其子類型)的若干對象。集合中的對象稱為元素或項目。例如,一個系所的所有學生形成一個集合,可以用來計算他們的平均年齡。
以下是Kotlin中相關的集合類型:
-
List是一個有序集合,可以通過索引——反映其位置的整數——訪問元素。元素在列表中可以出現多次。列表的一個例子是電話號碼:它是一組數字,順序很重要,而且可以重複。
-
Set是一個唯一元素的集合。它反映了數學上的集合抽象:一組不重複的對象。一般來說,集合元素的順序沒有意義。例如,彩票上的號碼形成一個集合:它們是唯一的,順序並不重要。
-
Map(或字典)是一組鍵值對。鍵是唯一的,每個鍵映射到一個確切的值。值可以重複。Map用於存儲對象之間的邏輯連接,例如員工的ID和他們的職位。
Kotlin允許你在操作集合時,不用考慮存儲在其中的對象的確切類型。換句話說,向字符串列表中添加字符串的方式與向整數列表或自定義類別列表中添加元素的方式相同。因此,Kotlin標準庫提供了泛型介面、類別和函數,用於創建、填充和管理任何類型的集合。
集合介面和相關函數位於kotlin.collections package中。我們來概覽一下其內容。
構建集合
從元素構建
創建集合最常見的方法是使用標準庫函數listOf<T>()、setOf<T>()、mutableListOf<T>()、mutableSetOf<T>()。如果你提供一個以逗號分隔的集合元素列表作為參數,編譯器會自動檢測元素類型。在創建空集合時,需要明確指定類型。
val numbersSet = setOf("one", "two", "three", "four")
val emptySet = mutableSetOf<String>()
同樣的功能也適用於map,使用函數mapOf()和mutableMapOf()。map的鍵和值是以Pair對象傳遞的(通常通過to中綴函數創建)。
val numbersMap = mapOf("key1" to 1, "key2" to 2, "key3" to 3, "key4" to 1)
需要注意的是,to表示法會創建一個短暫存在的Pair對象,所以建議僅在性能不是關鍵時使用它。為了避免過多的記憶體使用,可以使用其他方式。例如,可以創建一個可變map並使用寫操作來填充它。apply()函數可以幫助保持初始化的流暢性。
val numbersMap = mutableMapOf<String, String>().apply {
this["one"] = "1"
this["two"] = "2"
}
使用集合構建函數創建
另一種創建集合的方法是調用構建函數——buildList()、buildSet()或buildMap()。它們創建一個新的、可變的相應類型的集合,使用寫操作填充它,然後返回包含相同元素的只讀集合:
val map = buildMap {
put("a", 1)
put("b", 0)
put("c", 4)
}
println(map) // {a=1, b=0, c=4}
空集合
也有一些函數可以創建沒有任何元素的集合:emptyList()、emptySet()和emptyMap()。在創建空集合時,應該明確指定集合將持有的元素類型。
val empty = emptyList<String>()
List的初始化函數
對於list,有一個類似構造函數的函數,它接受列表大小和基於索引定義元素值的初始化函數。
val doubled = List(3) { it * 2 }
println(doubled)
// [0, 2, 4]具體類型構造函數
要創建具體類型的集合,例如ArrayList或LinkedList,可以使用這些類型的可用構造函數。對於Set和Map的實現也有類似的構造函數。
val linkedList = LinkedList<String>(listOf("one", "two", "three"))
val presizedSet = HashSet<Int>(32)
複製
要創建一個包含與現有集合相同元素的集合,可以使用複製函數。標準庫的集合複製函數會創建淺層複製集合,引用相同的元素。因此,對集合元素所做的更改會反映在所有其副本中。
集合複製函數,如toList()、toMutableList()、toSet()等,會在特定時刻創建集合的快照。其結果是一個包含相同元素的新集合。如果從原集合中添加或移除元素,這不會影響副本。副本可以獨立於源進行更改。
val alice = Person("Alice")
val sourceList = mutableListOf(alice, Person("Bob"))
val copyList = sourceList.toList()
sourceList.add(Person("Charles"))
alice.name = "Alicia"
println("First item's name is: ${sourceList[0].name} in source and ${copyList[0].name} in copy")
println("List size is: ${sourceList.size} in source and ${copyList.size} in copy")
// First item's name is: Alicia in source and Alicia in copy
// List size is: 3 in source and 2 in copy這些函數也可以用來將集合轉換為其他類型,例如從列表構建集合,反之亦然。
val sourceList = mutableListOf(1, 2, 3)
val copySet = sourceList.toMutableSet()
copySet.add(3)
copySet.add(4)
println(copySet)
// [1, 2, 3, 4]另外,可以創建對同一集合實例的新引用。當你使用現有集合初始化一個集合變量時,就會創建新引用。因此,當通過某個引用修改集合實例時,這些更改會反映在所有引用中。
val sourceList = mutableListOf(1, 2, 3)
val referenceList = sourceList
referenceList.add(4)
println("Source size: ${sourceList.size}") // Source size: 4
集合初始化可以用來限制可變性。例如,如果你創建一個List引用到一個MutableList,編譯器會在你試圖通過此引用修改集合時產生錯誤。
val sourceList = mutableListOf(1, 2, 3)
val referenceList: List<Int> = sourceList
//referenceList.add(4) //compilation error
sourceList.add(4)
println(referenceList) // shows the current state of sourceList
調用其他集合上的函數
集合可以作為對其他集合進行各種操作的結果來創建。例如,過濾列表會創建一個包含匹配過濾條件的元素的新列表:
val numbers = listOf("one", "two", "three", "four")
val longerThan3 = numbers.filter { it.length > 3 }
println(longerThan3)
// [three, four]
map 會根據轉換結果產生一個列表:
val numbers = setOf(1, 2, 3)
println(numbers.map { it * 3 })
println(numbers.mapIndexed { idx, value -> value * idx })
// [3, 6, 9]
// [0, 2, 6]associate 產生maps:
val numbers = listOf("one", "two", "three", "four")
println(numbers.associateWith { it.length })
// {one=3, two=3, three=5, four=4}有關Kotlin中集合操作的更多信息,請參見集合操作概述。
迭代器(Iterator)
為了遍歷集合元素,Kotlin標準庫支持常用的迭代器機制——這些對象可以順序地訪問元素而不暴露集合的底層結構。當你需要一個一個地處理集合中的所有元素時,迭代器非常有用,例如,打印值或進行類似的更新。
迭代器可以通過調用iterator()函數從Iterable<T>介面的繼承者(包括Set和List)獲得。
一旦獲得迭代器,它會指向集合的第一個元素;調用next()函數返回該元素並將迭代器位置移動到下一個元素(如果存在的話)。
一旦迭代器遍歷了最後一個元素,它將不能再用於檢索元素;也不能將其重置到任何先前的位置。要再次遍歷集合,需要創建一個新的迭代器。
val numbers = listOf("one", "two", "three", "four")
val numbersIterator = numbers.iterator()
while (numbersIterator.hasNext()) {
println(numbersIterator.next())
// one
// two
// three
// four
}
另一種遍歷Iterable集合的方法是眾所周知的for循環。當在集合上使用for時,你會隱式地獲得迭代器。因此,下面的代碼等同於上面的例子:
val numbers = listOf("one", "two", "three", "four")
for (item in numbers) {
println(item)
// one
// two
// three
// four
}
最後,有一個有用的forEach()函數,讓你可以自動迭代集合並為每個元素執行給定的代碼。因此,相同的例子看起來如下:
val numbers = listOf("one", "two", "three", "four")
numbers.forEach {
println(it)
// one
// two
// three
// four
}
列表迭代器
對於列表,有一個特殊的迭代器實現:ListIterator。它支持雙向迭代列表:向前和向後。
向後迭代通過hasPrevious()和previous()函數實現。此外,ListIterator還提供有關元素索引的信息,通過nextIndex()和previousIndex()函數。
val numbers = listOf("one", "two", "three", "four")
val listIterator = numbers.listIterator()
while (listIterator.hasNext()) listIterator.next()
println("Iterating backwards:")
// Iterating backwards:
while (listIterator.hasPrevious()) {
print("Index: ${listIterator.previousIndex()}")
println(", value: ${listIterator.previous()}")
// Index: 3, value: four
// Index: 2, value: three
// Index: 1, value: two
// Index: 0, value: one
}
能夠雙向迭代意味著ListIterator在到達最後一個元素後仍然可以使用。
可變迭代器
對於迭代可變集合,有MutableIterator,它擴展了Iterator並增加了元素移除函數remove()。因此,你可以在迭代集合時移除元素。
val numbers = mutableListOf("one", "two", "three", "four")
val mutableIterator = numbers.iterator()
mutableIterator.next()
mutableIterator.remove()
println("After removal: $numbers")
// After removal: [two, three, four]
除了移除元素外,MutableListIterator還可以在迭代列表時插入和替換元素,通過使用add()和set()函數。
val numbers = mutableListOf("one", "four", "four")
val mutableListIterator = numbers.listIterator()
mutableListIterator.next()
mutableListIterator.add("two")
println(numbers)
// [one, two, four, four]
mutableListIterator.next()
mutableListIterator.set("three")
println(numbers)
// [one, two, three, four]範圍與級數
Kotlin允許你使用kotlin.ranges包中的.rangeTo()和.rangeUntil()函數輕鬆創建值的範圍。
要創建:
- 閉合範圍,使用
..運算符調用.rangeTo()函數。 - 開放範圍,使用
..<運算符調用.rangeUntil()函數。
例如:
// 閉合範圍
println(4 in 1..4) // true
// 開放範圍
println(4 in 1..<4) // false
範圍特別適用於在for循環中進行迭代:
for (i in 1..4) print(i)
// 1234
要反向迭代數字,可以使用downTo函數代替..:
for (i in 4 downTo 1) print(i)
// 4321
也可以使用step函數以任意步長(不一定是1)迭代數字:
for (i in 0..8 step 2) print(i)
println()
// 02468
for (i in 0..<8 step 2) print(i)
println()
// 0246
for (i in 8 downTo 0 step 2) print(i)
// 86420
級數
整數類型(如Int、Long和Char)的範圍可以視為算術級數。在Kotlin中,這些級數由特定類型定義:IntProgression、LongProgression和CharProgression。
級數有三個基本屬性:第一個元素、最後一個元素和非零步長。第一個元素是first,隨後的元素是前一個元素加上步長。帶有正步長的級數迭代等同於Java/JavaScript中的索引for循環。
for (int i = first; i <= last; i += step) {
// ...
}
當你通過迭代範圍隱式地創建級數時,這個級數的第一個和最後一個元素是範圍的端點,步長為1。
for (i in 1..10) print(i)
// 12345678910
要定義自訂的級數步長,可以在範圍上使用step函數。
for (i in 1..8 step 2) print(i)
// 1357
級數的最後一個元素計算方法如下:
- 對於正步長:不大於結束值的最大值,使得
(last - first) % step == 0。 - 對於負步長:不小於結束值的最小值,使得
(last - first) % step == 0。
因此,最後一個元素不一定是指定的結束值。
for (i in 1..9 step 3) print(i) // 最後一個元素是7
// 147
級數實現了Iterable<N>,其中N分別是Int、Long或Char,所以你可以在各種集合函數中使用它們,如map、filter等。
println((1..10).filter { it % 2 == 0 })
// [2, 4, 6, 8, 10]序列(Sequence)
除了集合,Kotlin標準庫還包含另一種類型——序列(Sequence)。與集合不同,序列不包含元素,而是在迭代時生成它們。序列提供與Iterable相同的函數,但實現了另一種多步集合處理的方法。
當對Iterable進行多步處理時,這些步驟是急切執行的:每個處理步驟完成並返回其結果——一個中間集合。下一步在這個集合上執行。相反,序列的多步處理在可能的情況下是懶惰執行的:實際計算僅在請求整個處理鏈的結果時發生。
操作執行的順序也不同:序列對每個元素依次執行所有處理步驟。相反,Iterable完成整個集合的每一步,然後進入下一步。
因此,序列使你可以避免構建中間步驟的結果,從而提高整個集合處理鏈的性能。然而,序列的懶惰性質增加了一些開銷,這在處理較小的集合或進行簡單計算時可能是顯著的。因此,你應該同時考慮序列和Iterable,並決定哪個更適合你的情況。
創建
從元素創建
要創建序列,請調用sequenceOf()函數並列出其參數中的元素。
val numbersSequence = sequenceOf("four", "three", "two", "one")
從Iterable創建
如果你已經有一個Iterable對象(例如List或Set),可以通過調用asSequence()從中創建序列。
val numbers = listOf("one", "two", "three", "four")
val numbersSequence = numbers.asSequence()
從函數創建(from chunks)
另一種創建序列的方法是使用計算其元素的函數來構建它。要基於函數創建序列,請調用generateSequence()並將此函數作為參數。可以選擇性地將第一個元素指定為明確的值或函數調用的結果。當提供的函數返回null時,序列生成停止。因此,下面示例中的序列是無限的。
val oddNumbers = generateSequence(1) { it + 2 } // `it` 是前一個元素
println(oddNumbers.take(5).toList())
// println(oddNumbers.count()) // 錯誤:序列是無限的
要使用generateSequence()創建有限序列,請提供在最後一個元素之後返回null的函數。
val oddNumbersLessThan10 = generateSequence(1) { if (it < 8) it + 2 else null }
println(oddNumbersLessThan10.count())
從塊創建
最後,有一個函數允許你逐個或按任意大小的塊生成序列元素——sequence()函數。該函數接受包含yield()和yieldAll()函數調用的lambda表達式。它們將元素返回給序列消費者,並掛起sequence()的執行,直到消費者請求下一個元素。yield()以單個元素作為參數;yieldAll()可以接受Iterable對象、迭代器或另一個序列。yieldAll()的序列參數可以是無限的。然而,這樣的調用必須是最後一個:所有後續調用將永遠不會執行。
val oddNumbers = sequence {
yield(1)
yieldAll(listOf(3, 5))
yieldAll(generateSequence(7) { it + 2 })
}
println(oddNumbers.take(5).toList())
序列操作
序列操作根據其狀態要求分為以下幾類:
- 無狀態操作:不需要狀態並獨立處理每個元素,例如
map()或filter()。無狀態操作也可以需要少量常數狀態來處理元素,例如take()或drop()。 - 有狀態操作:需要大量狀態,通常與序列中元素的數量成正比。
如果序列操作返回另一個序列,該序列是懶惰生成的,則稱為中間操作。否則,該操作是終端操作。例如,終端操作包括toList()或sum()。序列元素只能通過終端操作檢索。
序列可以多次迭代;但是某些序列實現可能會限制自己只能迭代一次。在它們的文檔中會特別提到這一點。
序列處理示例
讓我們通過一個例子來看看Iterable和序列之間的區別。
Iterable
假設你有一個單詞列表。下面的代碼過濾出長度超過三個字符的單詞,並打印出前四個這樣的單詞的長度。
val words = "The quick brown fox jumps over the lazy dog".split(" ")
val lengthsList = words.filter { println("filter: $it"); it.length > 3 }
.map { println("length: ${it.length}"); it.length }
.take(4)
println("Lengths of first 4 words longer than 3 chars:")
println(lengthsList)
/*
filter: The
filter: quick
filter: brown
filter: fox
filter: jumps
filter: over
filter: the
filter: lazy
filter: dog
length: 5
length: 5
length: 5
length: 4
length: 4
Lengths of first 4 words longer than 3 chars:
[5, 5, 5, 4]
*/運行此代碼時,你會看到filter()和map()函數按代碼中出現的順序執行。首先,你會看到所有元素的filter:,然後是過濾後的元素的length:,最後是最後兩行的輸出。
這就是列表處理的方式:

列表處理
序列
現在用序列寫相同的代碼:
val words = "The quick brown fox jumps over the lazy dog".split(" ")
// 將List轉換為Sequence
val wordsSequence = words.asSequence()
val lengthsSequence = wordsSequence.filter { println("filter: $it"); it.length > 3 }
.map { println("length: ${it.length}"); it.length }
.take(4)
println("Lengths of first 4 words longer than 3 chars:")
// 終端操作:將結果作為List獲取
println(lengthsSequence.toList())
/**
Lengths of first 4 words longer than 3 chars:
filter: The
filter: quick
length: 5
filter: brown
length: 5
filter: fox
filter: jumps
length: 5
filter: over
length: 4
[5, 5, 5, 4]
*/此代碼的輸出顯示,filter()和map()函數僅在構建結果列表時調用。因此,你首先看到文本行"Lengths of..",然後序列處理開始。注意,對於過濾後的元素,map在過濾下一個元素之前執行。當結果大小達到4時,處理停止,因為這是take(4)可以返回的最大大小。
序列處理如下:

序列處理
在此示例中,序列處理用了18步,而使用列表的處理用了23步。
希望這些範例有助於你在開發Kotlin程式時瞭解序列與集合的使用差異及其優劣勢,特別是在處理多步集合操作時。
集合操作概述
Kotlin標準庫提供了多種函數,用於對集合進行操作。這些操作包括簡單的操作(如獲取或添加元素)以及更複雜的操作(如搜索、排序、過濾、轉換等)。
擴展函數與成員函數
集合操作在標準庫中以兩種方式聲明:集合介面的成員函數和擴展函數。
成員函數定義了集合類型所必需的操作。例如,Collection包含檢查其是否為空的函數isEmpty();List包含用於索引訪問元素的函數get()等。
當你創建自己的集合介面實現時,必須實現其成員函數。為了使新實現的創建更容易,可以使用標準庫中的集合介面的骨架實現:AbstractCollection、AbstractList、AbstractSet、AbstractMap及其可變對應物。
其他集合操作則聲明為擴展函數。這些包括過濾、轉換、排序和其他集合處理函數。
常用操作
常用操作可用於只讀和可變集合。常用操作分為以下幾組:
- 轉換
- 過濾
- 加號和減號操作符
- 分組
- 檢索集合部分
- 檢索單個元素
- 排序
- 聚合操作
這些頁面上描述的操作返回其結果而不影響原始集合。例如,過濾操作生成一個包含所有匹配過濾條件的元素的新集合。這些操作的結果應該存儲在變量中,或以其他方式使用,例如,傳遞給其他函數。
val numbers = listOf("one", "two", "three", "four")
numbers.filter { it.length > 3 } // numbers沒有任何變化,結果丟失
println("numbers are still $numbers")
val longerThan3 = numbers.filter { it.length > 3 } // 結果存儲在longerThan3中
println("numbers longer than 3 chars are $longerThan3")
對於某些集合操作,可以指定目標對象。目標對象是可變集合,函數將其結果項附加到該集合中,而不是返回新的對象。對於具有目標的操作,有帶有To後綴的單獨函數名稱,例如filterTo()代替filter()或associateTo()代替associate()。這些函數將目標集合作為附加參數。
val numbers = listOf("one", "two", "three", "four")
val filterResults = mutableListOf<String>() // 目標對象
numbers.filterTo(filterResults) { it.length > 3 }
numbers.filterIndexedTo(filterResults) { index, _ -> index == 0 }
println(filterResults) // 包含兩次操作的結果
為了方便起見,這些函數返回目標集合,因此你可以在函數調用的相應參數中直接創建它:
// 將數字過濾到新的哈希集,從而消除結果中的重複項
val result = numbers.mapTo(HashSet()) { it.length }
println("distinct item lengths are $result")
具有目標的函數適用於過濾、關聯、分組、展平和其他操作。完整的目標操作列表請參見Kotlin集合參考。
寫操作
對於可變集合,還有改變集合狀態的寫操作。這些操作包括添加、刪除和更新元素。寫操作列在寫操作以及List特定操作和Map特定操作的對應部分中。
對於某些操作,有成對的函數執行相同的操作:一個在原地應用操作,另一個返回結果作為單獨的集合。例如,sort()對可變集合進行原地排序,因此其狀態改變;sorted()創建一個包含相同元素的新集合,按排序順序排列。
val numbers = mutableListOf("one", "two", "three", "four")
val sortedNumbers = numbers.sorted()
println(numbers == sortedNumbers) // false
numbers.sort()
println(numbers == sortedNumbers) // true集合轉換操作
Kotlin標準庫提供了一組用於集合轉換的擴展函數。這些函數根據提供的轉換規則從現有集合構建新集合。以下是可用的集合轉換函數概述。
映射 (Map)
映射轉換通過對另一個集合的元素應用函數來創建集合。基本的映射函數是map()。它將給定的lambda函數應用於每個元素,並返回lambda結果的列表。結果的順序與原始元素的順序相同。要應用同時使用元素索引作為參數的轉換,請使用mapIndexed()。
val numbers = setOf(1, 2, 3)
println(numbers.map { it * 3 })
println(numbers.mapIndexed { idx, value -> value * idx })
如果轉換在某些元素上產生null,可以通過調用mapNotNull()代替map(),或mapIndexedNotNull()代替mapIndexed()來過濾結果集合中的null。
val numbers = setOf(1, 2, 3)
println(numbers.mapNotNull { if (it == 2) null else it * 3 })
println(numbers.mapIndexedNotNull { idx, value -> if (idx == 0) null else value * idx })
在轉換地圖時,你有兩個選擇:變換鍵而保持值不變,反之亦然。要對鍵應用給定的轉換,使用mapKeys();反過來,mapValues()轉換值。這兩個函數都使用將map條目作為參數的轉換,因此你可以同時操作其鍵和值。
val numbersMap = mapOf("key1" to 1, "key2" to 2, "key3" to 3, "key11" to 11)
println(numbersMap.mapKeys { it.key.uppercase() })
println(numbersMap.mapValues { it.value + it.key.length })
拉鍊 (Zip)
拉鍊轉換是從兩個集合中相同位置的元素構建對。在Kotlin標準庫中,這是通過zip()擴展函數完成的。
當在一個集合或數組上調用並將另一個集合(或數組)作為參數時,zip()返回一個Pair對象的列表。接收集合的元素是這些對中的第一個元素。
如果集合大小不同,zip()的結果是較小的大小;較大集合的最後元素不包括在結果中。
zip()也可以以中綴形式調用,即a zip b。
val colors = listOf("red", "brown", "grey")
val animals = listOf("fox", "bear", "wolf")
println(colors zip animals)
val twoAnimals = listOf("fox", "bear")
println(colors.zip(twoAnimals))
你也可以用一個帶有兩個參數的轉換函數調用zip():接收元素和參數元素。在這種情況下,結果列表包含對接收元素和參數元素的對調用轉換函數的返回值。
val colors = listOf("red", "brown", "grey")
val animals = listOf("fox", "bear", "wolf")
println(colors.zip(animals) { color, animal -> "The ${animal.replaceFirstChar { it.uppercase() }} is $color"})
當你有一個Pair列表時,可以進行反向轉換——解壓縮,從這些對中構建兩個列表:
第一個列表包含原始列表中每個Pair的第一個元素。
第二個列表包含第二個元素。
要解壓縮一個Pair列表,調用unzip()。
val numberPairs = listOf("one" to 1, "two" to 2, "three" to 3, "four" to 4)
println(numberPairs.unzip())
關聯 (Associate)
關聯轉換允許從集合元素及其相關的某些值構建map。在不同的關聯類型中,元素可以是關聯map中的鍵或值。
基本的關聯函數associateWith()創建一個map,其中原始集合的元素是鍵,值是由給定的轉換函數生成的。如果兩個元素相等,只有最後一個會保留在map中。
val numbers = listOf("one", "two", "three", "four")
println(numbers.associateWith { it.length })
要構建map,其集合元素作為值,有associateBy()函數。它接收一個函數,該函數根據元素的值返回鍵。如果兩個元素的鍵相等,只有最後一個會保留在map中。
associateBy()也可以與值轉換函數一起調用。
val numbers = listOf("one", "two", "three", "four")
println(numbers.associateBy { it.first().uppercaseChar() })
println(numbers.associateBy(keySelector = { it.first().uppercaseChar() }, valueTransform = { it.length }))
另一種方法是使用associate()構建map,其中鍵和值都從集合元素中生成。它接收一個lambda函數,該函數返回一個Pair:對應的map條目的鍵和值。
需要注意的是,associate()會產生短暫存在的Pair對象,這可能會影響性能。因此,當性能不是關鍵或比其他選項更可取時,應使用associate()。
一個示例是當鍵和值是一起從元素生成時。
val names = listOf("Alice Adams", "Brian Brown", "Clara Campbell")
println(names.associate { name -> parseFullName(name).let { it.lastName to it.firstName } })
在這裡,我們首先對元素調用轉換函數,然後從該函數的結果屬性構建一個對。
展平 (Flatten)
如果你操作嵌套集合,你可能會發現標準庫提供的平展訪問嵌套集合元素的函數很有用。
第一個函數是flatten()。你可以在集合的集合上調用它,例如,一個List的Set。該函數返回一個包含所有嵌套集合元素的單個列表。
val numberSets = listOf(setOf(1, 2, 3), setOf(4, 5, 6), setOf(1, 2))
println(numberSets.flatten())
另一個函數flatMap()提供了一種靈活的方式來處理嵌套集合。它接收一個函數,該函數將集合元素映射到另一個集合。結果,flatMap()返回其對所有元素的返回值的單個列表。因此,flatMap()的行為類似於隨後調用map()(以集合作為映射結果)和flatten()。
val containers = listOf(
StringContainer(listOf("one", "two", "three")),
StringContainer(listOf("four", "five", "six")),
StringContainer(listOf("seven", "eight"))
)
println(containers.flatMap { it.values })
字符串表示 (String representation)
如果你需要以可讀格式檢索集合內容,請使用將集合轉換為字符串的函數:joinToString()和joinTo()。
joinToString()根據提供的參數構建單個字符串。joinTo()做同樣的事,但將結果附加到給定的Appendable對象。
當使用默認參數調用時,這些函數返回的結果類似於對集合調用toString():元素的字符串表示形式以逗號和空格分隔的字符串。
val numbers = listOf("one", "two", "three", "four")
println(numbers)
println(numbers.joinToString())
val listString = StringBuffer("The list of numbers: ")
numbers.joinTo(listString)
println(listString)
要構建自定義字符串表示,可以在函數參數中指定其參數:分隔符、前綴和後綴。結果字符串將以前綴開始,以後綴結束。分隔符將在每個元素之後出現,除了最後一個元素。
val numbers = listOf("one", "two", "three", "four")
println(numbers.joinToString(separator = " | ", prefix = "start: ", postfix = ": end"))
對於較大的集合,你可能希望指定限制——將包含在結果中的元素數量。如果集合大小超過限制,所有其他元素將被替換為單個截斷參數值。
val numbers = listOf("one", "two", "three", "four")
println(numbers.joinToString { "Element: ${it.uppercase()}"})過濾集合
過濾是集合處理中最常見的任務之一。在Kotlin中,過濾條件由謂詞定義——這些lambda函數接收一個集合元素並返回一個布爾值:true表示給定元素符合謂詞,false表示相反。
標準庫包含一組擴展函數,允許你在一次調用中過濾集合。這些函數不會更改原始集合,因此它們可用於可變和只讀集合。要操作過濾結果,應將其賦值給變量或在過濾後鏈接函數。
根據謂詞過濾
基本的過濾函數是filter()。當用謂詞調用時,filter()返回符合條件的集合元素。對於List和Set,結果集合是List,對於Map,結果也是Map。
val numbers = listOf("one", "two", "three", "four")
val longerThan3 = numbers.filter { it.length > 3 }
println(longerThan3)
val numbersMap = mapOf("key1" to 1, "key2" to 2, "key3" to 3, "key11" to 11)
val filteredMap = numbersMap.filter { (key, value) -> key.endsWith("1") && value > 10 }
println(filteredMap)
filter()中的謂詞只能檢查元素的值。如果你想在過濾中使用元素的位置,請使用filterIndexed()。它接收一個帶有兩個參數的謂詞:索引和元素的值。
要根據否定條件過濾集合,使用filterNot()。它返回一個對謂詞結果為false的元素列表。
val numbers = listOf("one", "two", "three", "four")
val filteredIdx = numbers.filterIndexed { index, s -> (index != 0) && (s.length < 5) }
val filteredNot = numbers.filterNot { it.length <= 3 }
println(filteredIdx)
println(filteredNot)
還有一些函數可以通過過濾給定類型的元素來縮小元素類型:
filterIsInstance()返回給定類型的集合元素。對List<Any>調用filterIsInstance<T>()返回List<T>,從而允許你對其項目調用T類型的函數。
val numbers = listOf(null, 1, "two", 3.0, "four")
println("All String elements in upper case:")
numbers.filterIsInstance<String>().forEach {
println(it.uppercase())
}
filterNotNull()返回所有非空元素。對List<T?>調用filterNotNull()返回List<T: Any>,從而允許你將元素作為非空對象處理。
val numbers = listOf(null, "one", "two", null)
numbers.filterNotNull().forEach {
println(it.length) // length is unavailable for nullable Strings
}
分區 (Partition)
另一個過濾函數——partition()——根據謂詞過濾集合,並將不符合條件的元素保存在單獨的列表中。因此,你會得到一對列表作為返回值:第一個列表包含符合謂詞的元素,第二個列表包含原始集合中的其他所有元素。
val numbers = listOf("one", "two", "three", "four")
val (match, rest) = numbers.partition { it.length > 3 }
println(match)
println(rest)
測試謂詞 (Test predicates)
最後,有一些函數只是將謂詞測試集合元素:
any():如果至少有一個元素符合給定謂詞,則返回true。none():如果沒有元素符合給定謂詞,則返回true。all():如果所有元素都符合給定謂詞,則返回true。注意,對空集合調用任何有效謂詞時,all()返回true。這種行為在邏輯中稱為真空真理。
val numbers = listOf("one", "two", "three", "four")
println(numbers.any { it.endsWith("e") })
println(numbers.none { it.endsWith("a") })
println(numbers.all { it.endsWith("e") })
println(emptyList<Int>().all { it > 5 }) // vacuous truth
any()和none()也可以不帶謂詞使用:在這種情況下,它們只是檢查集合是否為空。any()返回true如果有元素,否則返回false;none()做相反的事。
val numbers = listOf("one", "two", "three", "four")
val empty = emptyList<String>()
println(numbers.any())
println(empty.any())
println(numbers.none())
println(empty.none())加號和減號操作符
在Kotlin中,加號(+)和減號(-)操作符是為集合定義的。它們將集合作為第一個操作數;第二個操作數可以是元素或另一個集合。返回值是一個新的只讀集合:
plus的結果包含原始集合中的元素以及第二個操作數中的元素。minus的結果包含原始集合中的元素,但去除了第二個操作數中的元素。如果第二個操作數是元素,minus會移除它的首次出現;如果是集合,則移除其所有元素的出現。
val numbers = listOf("one", "two", "three", "four")
val plusList = numbers + "five"
val minusList = numbers - listOf("three", "four")
println(plusList) // [one, two, three, four, five]
println(minusList) // [one, two]
對映射的加號和減號操作符
關於映射(Map)的加號和減號操作符的詳細信息,請參見映射特定操作。
增強賦值操作符
增強賦值操作符plusAssign(+=)和minusAssign(-=)也為集合定義。然而,對於只讀集合,它們實際上使用plus或minus操作符並嘗試將結果賦值給相同的變量。因此,它們僅適用於var只讀集合。對於可變集合,如果是val,它們會修改集合。更多詳細信息請參見集合寫操作。
分組
Kotlin標準庫提供了一組用於對集合元素進行分組的擴展函數。基本的分組函數groupBy()接受一個lambda函數並返回一個Map。在這個Map中,每個鍵是lambda結果,對應的值是返回該結果的元素列表。此函數可以用來,例如,按字符串的首字母對字符串列表進行分組。
你還可以使用第二個lambda參數來調用groupBy(),這是一個值轉換函數。在使用兩個lambda的groupBy()的結果Map中,keySelector函數生成的鍵被映射到值轉換函數的結果,而不是原始元素。
以下示例展示了如何使用groupBy()函數按字符串的首字母對字符串進行分組,使用for運算符迭代結果Map中的組,然後使用keySelector函數將值轉換為大寫:
val numbers = listOf("one", "two", "three", "four", "five")
// 使用 groupBy() 按首字母對字符串進行分組
val groupedByFirstLetter = numbers.groupBy { it.first().uppercase() }
println(groupedByFirstLetter)
// {O=[one], T=[two, three], F=[four, five]}
// 迭代每個組並打印鍵及其相關的值
for ((key, value) in groupedByFirstLetter) {
println("Key: $key, Values: $value")
}
// Key: O, Values: [one]
// Key: T, Values: [two, three]
// Key: F, Values: [four, five]
// 按首字母對字符串進行分組並將值轉換為大寫
val groupedAndTransformed = numbers.groupBy(keySelector = { it.first() }, valueTransform = { it.uppercase() })
println(groupedAndTransformed)
// {o=[ONE], t=[TWO, THREE], f=[FOUR, FIVE]}
如果你想對元素進行分組,然後一次性對所有組應用操作,請使用groupingBy()函數。它返回一個Grouping類型的實例。Grouping實例允許你以懶惰的方式對所有組應用操作:這些組實際上是在操作執行之前構建的。
具體而言,Grouping支持以下操作:
eachCount()計算每個組中的元素數量。fold()和reduce()對每個組作為單獨的集合執行fold和reduce操作,並返回結果。aggregate()將給定操作依次應用於每個組中的所有元素,並返回結果。這是對Grouping執行任何操作的通用方法。當fold或reduce不夠時,使用它來實現自定義操作。
你可以在結果Map上使用for運算符來迭代由groupingBy()函數創建的組。這允許你訪問每個鍵和與該鍵相關的元素計數。
以下示例展示了如何使用groupingBy()函數按字符串的首字母對字符串進行分組,計算每個組中的元素數量,然後迭代每個組以打印鍵和元素的數量:
val numbers = listOf("one", "two", "three", "four", "five")
// 使用 groupingBy() 按首字母對字符串進行分組並計算每個組中的元素數量
val grouped = numbers.groupingBy { it.first() }.eachCount()
// 迭代每個組並打印鍵及其相關的值
for ((key, count) in grouped) {
println("Key: $key, Count: $count")
// Key: o, Count: 1
// Key: t, Count: 2
// Key: f, Count: 2
}
這樣,你可以根據特定的條件對集合元素進行分組,並對分組結果進行進一步的操作。
檢索集合部分
Kotlin標準庫包含一組擴展函數,用於檢索集合的部分內容。這些函數提供多種方式來選擇結果集合的元素:明確列出它們的位置、指定結果大小等。
切片 (Slice)
slice() 返回具有給定索引的集合元素列表。索引可以作為範圍或整數值的集合傳遞。
val numbers = listOf("one", "two", "three", "four", "five", "six")
println(numbers.slice(1..3)) // [two, three, four]
println(numbers.slice(0..4 step 2)) // [one, three, five]
println(numbers.slice(setOf(3, 5, 0))) // [four, six, one]
取出和丟棄 (Take and drop)
要從第一個元素開始取出指定數量的元素,使用take()函數。要取出最後的元素,使用takeLast()。當傳遞的數量大於集合大小時,這兩個函數都返回整個集合。
要取出除了給定數量的第一個或最後一個元素之外的所有元素,分別調用drop()和dropLast()函數。
val numbers = listOf("one", "two", "three", "four", "five", "six")
println(numbers.take(3)) // [one, two, three]
println(numbers.takeLast(3)) // [four, five, six]
println(numbers.drop(1)) // [two, three, four, five, six]
println(numbers.dropLast(5)) // [one]
你還可以使用謂詞來定義取出或丟棄的元素數量。有四個與上面描述的函數類似的函數:
takeWhile()是帶有謂詞(predicates)的take():它取出直到不匹配謂詞的第一個元素為止(不包括該元素)的元素。如果第一個集合元素不匹配謂詞,結果為空。takeLastWhile()類似於takeLast():它從集合末尾取出匹配謂詞的元素範圍。範圍的第一個元素是不匹配謂詞的最後一個元素的下一個元素。如果最後的集合元素不匹配謂詞,結果為空。dropWhile()與帶有相同謂詞的takeWhile()相反:它返回從不匹配謂詞的第一個元素到結尾的元素。dropLastWhile()與帶有相同謂詞的takeLastWhile()相反:它返回從開始到不匹配謂詞的最後一個元素的元素。
val numbers = listOf("one", "two", "three", "four", "five", "six")
println(numbers.takeWhile { !it.startsWith('f') }) // [one, two, three, four]
println(numbers.takeLastWhile { it != "three" }) // [four, five, six]
println(numbers.dropWhile { it.length == 3 }) // [four, five, six]
println(numbers.dropLastWhile { it.contains('i') }) // [one, two, three]
分塊 (Chunked)
要將集合拆分為給定大小的部分,使用chunked()函數。chunked()接受一個參數——塊的大小,並返回一個包含給定大小的列表的列表。第一個塊從第一個元素開始並包含大小元素,第二個塊包含接下來的大小元素,依此類推。最後一個塊可能大小較小。
val numbers = (0..13).toList()
println(numbers.chunked(3)) // [[0, 1, 2], [3, 4, 5], [6, 7, 8], [9, 10, 11], [12, 13]]
你還可以立即對返回的塊應用轉換。為此,調用chunked()時提供轉換函數。lambda參數是集合的一個塊。當chunked()與轉換一起調用時,這些塊是短暫的列表,應該在該lambda中消費。
val numbers = (0..13).toList()
println(numbers.chunked(3) { it.sum() }) // [3, 12, 21, 30, 25]
窗口 (Windowed)
你可以檢索集合元素的所有可能的給定大小的範圍。用於獲取它們的函數稱為windowed():它返回元素範圍的列表,就像你通過滑動窗口查看集合一樣。與chunked()不同,windowed()返回從每個集合元素開始的元素範圍。所有窗口都作為單個列表的元素返回。
val numbers = listOf("one", "two", "three", "four", "five")
println(numbers.windowed(3)) // [[one, two, three], [two, three, four], [three, four, five]]
windowed()提供了可選參數,使其更具靈活性:
step定義了兩個相鄰窗口的第一個元素之間的距離。默認值為1,因此結果包含從所有元素開始的窗口。如果將步長增加到2,你將只會獲得從奇數元素開始的窗口:第一、第三,依此類推。partialWindows包含從集合末尾的元素開始的較小大小的窗口。例如,如果你請求三個元素的窗口,你無法為最後兩個元素構建它們。在這種情況下,啟用partialWindows將包含大小為2和1的兩個列表。
最後,你可以立即對返回的範圍應用轉換。為此,調用windowed()時提供轉換函數。
val numbers = (1..10).toList()
println(numbers.windowed(3, step = 2, partialWindows = true)) // [[1, 2, 3], [3, 4, 5], [5, 6, 7], [7, 8, 9], [9, 10]]
println(numbers.windowed(3) { it.sum() }) // [6, 9, 12, 15, 18, 21, 24, 27]
要構建兩元素的窗口,有一個單獨的函數——zipWithNext()。它創建接收集合的相鄰元素對。請注意,zipWithNext()不會將集合分成對;它為每個元素(除了最後一個)創建一個Pair,因此其結果對於[1, 2, 3, 4]是[[1, 2], [2, 3], [3, 4]],而不是[[1, 2], [3, 4]]。zipWithNext()也可以與轉換函數一起調用;該轉換函數應接受接收集合的兩個元素作為參數。
val numbers = listOf("one", "two", "three", "four", "five")
println(numbers.zipWithNext()) // [(one, two), (two, three), (three, four), (four, five)]
println(numbers.zipWithNext { s1, s2 -> s1.length > s2.length }) // [false, false, false, true]
這些擴展函數使你能夠靈活地檢索和處理集合的部分內容。
檢索單個元素
Kotlin集合提供了一組函數,用於從集合中檢索單個元素。本頁描述的函數適用於列表和集合。
按位置檢索
要檢索特定位置的元素,可以使用elementAt()函數。調用該函數並傳入一個整數作為參數,你將獲得給定位置的集合元素。第一個元素的位置是0,最後一個元素的位置是size - 1。
elementAt()對於不提供索引訪問的集合或靜態上未知提供索引訪問的集合很有用。在列表的情況下,更符合習慣的是使用索引訪問操作符(get()或[])。
val numbers = linkedSetOf("one", "two", "three", "four", "five")
println(numbers.elementAt(3)) // four
val numbersSortedSet = sortedSetOf("one", "two", "three", "four")
println(numbersSortedSet.elementAt(0)) // one (元素按升序存儲)
還有一些用於檢索集合的第一個和最後一個元素的有用別名:first()和last()。
val numbers = listOf("one", "two", "three", "four", "five")
println(numbers.first()) // one
println(numbers.last()) // five
為了避免在檢索不存在位置的元素時拋出異常,可以使用elementAt()的安全變體:
elementAtOrNull()當指定位置超出集合範圍時返回null。elementAtOrElse()另外接受一個lambda函數,該函數將一個整數參數映射為集合元素類型的實例。當調用超出範圍的位置時,elementAtOrElse()返回該lambda對給定值的結果。
val numbers = listOf("one", "two", "three", "four", "five")
println(numbers.elementAtOrNull(5)) // null
println(numbers.elementAtOrElse(5) { index -> "The value for index $index is undefined" })
// The value for index 5 is undefined
按條件檢索
函數first()和last()也讓你可以搜索集合中符合給定謂詞的元素。當你調用帶有測試集合元素的謂詞的first()時,你將獲得謂詞為true的第一個元素。反過來,帶有謂詞的last()返回匹配謂詞的最後一個元素。
val numbers = listOf("one", "two", "three", "four", "five", "six")
println(numbers.first { it.length > 3 }) // three
println(numbers.last { it.startsWith("f") }) // five
如果沒有元素匹配謂詞,這兩個函數會拋出異常。為了避免這種情況,使用firstOrNull()和lastOrNull():如果沒有找到匹配的元素,它們返回null。
val numbers = listOf("one", "two", "three", "four", "five", "six")
println(numbers.firstOrNull { it.length > 6 }) // null
如果它們的名字更適合你的情況,可以使用別名:
find()代替firstOrNull()findLast()代替lastOrNull()
val numbers = listOf(1, 2, 3, 4)
println(numbers.find { it % 2 == 0 }) // 2
println(numbers.findLast { it % 2 == 0 }) // 4
帶選擇器的檢索
如果你需要在檢索元素之前對集合進行映射,可以使用firstNotNullOf()函數。它結合了兩個操作:
- 使用選擇器函數映射集合
- 返回結果中的第一個非空值
如果結果集合中沒有非空元素,firstNotNullOf()會拋出NoSuchElementException。使用對應的firstNotNullOfOrNull()來在這種情況下返回null。
val list = listOf<Any>(0, "true", false)
// 將每個元素轉換為字符串並返回具有所需長度的第一個
val longEnough = list.firstNotNullOf { item -> item.toString().takeIf { it.length >= 4 } }
println(longEnough) // true
隨機元素
如果你需要檢索集合的任意元素,調用random()函數。可以不帶參數調用它,或者將Random對象作為隨機性的來源。
val numbers = listOf(1, 2, 3, 4)
println(numbers.random())
在空集合上,random()會拋出異常。要接收null,請使用randomOrNull()。
檢查元素存在
要檢查集合中是否存在某個元素,使用contains()函數。如果有一個等於函數參數的集合元素,它返回true。可以使用in關鍵字以操作符形式調用contains()。
要一次檢查多個實例的存在,調用containsAll()並將這些實例的集合作為參數。
val numbers = listOf("one", "two", "three", "four", "five", "six")
println(numbers.contains("four")) // true
println("zero" in numbers) // false
println(numbers.containsAll(listOf("four", "two"))) // true
println(numbers.containsAll(listOf("one", "zero"))) // false
此外,可以通過調用isEmpty()或isNotEmpty()檢查集合中是否包含任何元素。
val numbers = listOf("one", "two", "three", "four", "five", "six")
println(numbers.isEmpty()) // false
println(numbers.isNotEmpty()) // true
val empty = emptyList<String>()
println(empty.isEmpty()) // true
println(empty.isNotEmpty()) // false
這些擴展函數使你能夠靈活地檢索和處理集合中的單個元素。
排序
元素的順序是某些集合類型的重要方面。例如,兩個具有相同元素的列表,如果它們的元素順序不同,它們就不相等。
在Kotlin中,可以通過幾種方式定義對象的順序。
首先是自然順序。它是為實現Comparable介面的類型定義的。當沒有指定其他順序時,會使用自然順序來對其進行排序。
大多數內建類型是可比較的:
- 數字類型使用傳統的數值順序:1大於0;-3.4f大於-5f,依此類推。
- 字符和字符串使用詞典順序:b大於a;world大於hello。
要為自定義類型定義自然順序,請使該類型成為Comparable的實現者。這需要實現compareTo()函數。compareTo()必須接受同類型的另一個對象作為參數,並返回一個整數值,表示哪個對象更大:
- 正值表示接收對象更大。
- 負值表示它小於參數。
- 零表示兩個對象相等。
以下是一個排序版本的類,該版本由主要部分和次要部分組成。
class Version(val major: Int, val minor: Int): Comparable<Version> {
override fun compareTo(other: Version): Int = when {
this.major != other.major -> this.major compareTo other.major // compareTo() 以中綴形式
this.minor != other.minor -> this.minor compareTo other.minor
else -> 0
}
}
fun main() {
println(Version(1, 2) > Version(1, 3)) // false
println(Version(2, 0) > Version(1, 5)) // true
}
自定義順序允許你以所需的方式對任何類型的實例進行排序。特別是,你可以為不可比較的對象定義順序,或為可比較類型定義自然順序以外的順序。要為某種類型定義自定義順序,請為其創建Comparator。Comparator包含compare()函數:它接受一個類的兩個實例,並返回它們之間比較的整數結果。結果的解釋方式與上述compareTo()結果相同。
val lengthComparator = Comparator { str1: String, str2: String -> str1.length - str2.length }
println(listOf("aaa", "bb", "c").sortedWith(lengthComparator)) // [c, bb, aaa]
擁有lengthComparator,你可以按字符串長度排列,而不是按默認的詞典順序。
定義Comparator的一種更簡便的方法是使用標準庫中的compareBy()函數。compareBy()接受一個lambda函數,該函數從實例生成一個Comparable值,並將自定義順序定義為生成值的自然順序。
使用compareBy(),上面示例中的長度比較器如下所示:
println(listOf("aaa", "bb", "c").sortedWith(compareBy { it.length })) // [c, bb, aaa]
Kotlin集合包提供了用於按自然順序、自定義順序甚至隨機順序排序集合的函數。在本頁中,我們將描述適用於只讀集合的排序函數。這些函數返回其結果作為包含原始集合元素的新集合,並按請求的順序排列。要了解有關原地排序可變集合的函數,請參見列表特定操作。
自然順序
基本函數sorted()和sortedDescending()根據其自然順序返回升序和降序排序的集合元素。這些函數適用於Comparable元素的集合。
val numbers = listOf("one", "two", "three", "four")
println("Sorted ascending: ${numbers.sorted()}") // Sorted ascending: [four, one, three, two]
println("Sorted descending: ${numbers.sortedDescending()}") // Sorted descending: [two, three, one, four]
自定義順序
對於自定義順序排序或不可比較對象排序,有sortedBy()和sortedByDescending()函數。它們接受一個選擇器函數,該函數將集合元素映射為Comparable值,並按這些值的自然順序排序集合。
val numbers = listOf("one", "two", "three", "four")
val sortedNumbers = numbers.sortedBy { it.length }
println("Sorted by length ascending: $sortedNumbers") // Sorted by length ascending: [one, two, four, three]
val sortedByLast = numbers.sortedByDescending { it.last() }
println("Sorted by the last letter descending: $sortedByLast") // Sorted by the last letter descending: [four, two, one, three]
要為集合排序定義自定義順序,可以提供自己的Comparator。為此,調用sortedWith()函數並傳入你的Comparator。使用此函數,按字符串長度排序看起來如下所示:
val numbers = listOf("one", "two", "three", "four")
println("Sorted by length ascending: ${numbers.sortedWith(compareBy { it.length })}") // Sorted by length ascending: [one, two, four, three]
反向順序
可以使用reversed()函數檢索反向順序的集合。
val numbers = listOf("one", "two", "three", "four")
println(numbers.reversed()) // [four, three, two, one]
reversed()返回包含元素副本的新集合。因此,如果你稍後更改原始集合,這不會影響以前獲得的reversed()結果。
另一個反轉函數 - asReversed()
返回相同集合實例的反轉視圖,因此如果原始列表不會更改,它可能比reversed()更輕量且更可取。
val numbers = listOf("one", "two", "three", "four")
val reversedNumbers = numbers.asReversed()
println(numbers) // [one, two, three, four]
println(numbers.reversed()) // [four, three, two, one]
println(numbers) // [one, two, three, four]
println(reversedNumbers) // [four, three, two, one]如果原始列表是可變的,它的所有更改都會反映在其反轉視圖中,反之亦然。
val numbers = mutableListOf("one", "two", "three", "four")
val reversedNumbers = numbers.asReversed()
println(reversedNumbers) // [four, three, two, one]
numbers.add("five")
println(reversedNumbers) // [five, four, three, two, one]
然而,如果列表的可變性未知或源根本不是列表,reversed()更可取,因為它的結果是未來不會更改的副本。
隨機順序
最後,有一個返回包含隨機順序的集合元素的新列表的函數——shuffled()。你可以不帶參數調用它,或將Random對象作為參數。
val numbers = listOf("one", "two", "three", "four")
println(numbers.shuffled())
這些函數使你能夠靈活地排序集合,並根據需要檢索其元素。
聚合操作
Kotlin集合包含一些常用的聚合操作函數——這些操作根據集合的內容返回單個值。大多數這些操作都是眾所周知的,並且在其他語言中也以相同方式工作:
minOrNull()和maxOrNull()分別返回最小和最大的元素。對於空集合,它們返回null。average()返回數字集合中元素的平均值。sum()返回數字集合中元素的總和。count()返回集合中的元素數量。
fun main() {
val numbers = listOf(6, 42, 10, 4)
println("Count: ${numbers.count()}") // Count: 4
println("Max: ${numbers.maxOrNull()}") // Max: 42
println("Min: ${numbers.minOrNull()}") // Min: 4
println("Average: ${numbers.average()}") // Average: 15.5
println("Sum: ${numbers.sum()}") // Sum: 62
}
還有一些函數可以通過特定的選擇器函數或自定義的Comparator來檢索最小和最大的元素:
maxByOrNull()和minByOrNull()接受一個選擇器函數,並返回該函數返回值最大的或最小的元素。maxWithOrNull()和minWithOrNull()接受一個Comparator對象,並根據該Comparator返回最大或最小的元素。maxOfOrNull()和minOfOrNull()接受一個選擇器函數,並返回該選擇器函數的最大或最小返回值。maxOfWithOrNull()和minOfWithOrNull()接受一個Comparator對象,並根據該Comparator返回選擇器函數的最大或最小返回值。
這些函數在空集合上返回null。還有一些替代函數——maxOf、minOf、maxOfWith和minOfWith——它們與對應的函數作用相同,但在空集合上會拋出NoSuchElementException。
val numbers = listOf(5, 42, 10, 4)
val min3Remainder = numbers.minByOrNull { it % 3 }
println(min3Remainder) // 4
val strings = listOf("one", "two", "three", "four")
val longestString = strings.maxWithOrNull(compareBy { it.length })
println(longestString) // three
除了常規的sum(),還有一個高級求和函數sumOf(),它接受一個選擇器函數並返回該函數應用於所有集合元素的總和。選擇器可以返回不同的數字類型:Int、Long、Double、UInt和ULong(在JVM上還包括BigInteger和BigDecimal)。
val numbers = listOf(5, 42, 10, 4)
println(numbers.sumOf { it * 2 }) // 122
println(numbers.sumOf { it.toDouble() / 2 }) // 30.5
Fold和Reduce
對於更具體的情況,有reduce()和fold()函數,它們將提供的操作依次應用於集合元素並返回累積結果。該操作接受兩個參數:先前的累積值和集合元素。
這兩個函數的區別在於fold()接受一個初始值,並在第一步中將其作為累積值,而reduce()的第一步使用第一個和第二個元素作為操作參數。
val numbers = listOf(5, 2, 10, 4)
val simpleSum = numbers.reduce { sum, element -> sum + element } // 5 + 2 +10 + 4
println(simpleSum) // 21
val sumDoubled = numbers.fold(0) { sum, element -> sum + element * 2 } // 0 + 5*2 + 2*2 + 10*2 + 4*2
println(sumDoubled) // 42
// 錯誤:第一個元素未在結果中加倍
// val sumDoubledReduce = numbers.reduce { sum, element -> sum + element * 2 }
// println(sumDoubledReduce)
上述示例顯示了區別:fold()用於計算加倍元素的總和。如果將相同的函數傳遞給reduce(),它將返回另一個結果,因為它在第一步中使用列表的第一個和第二個元素作為參數,因此第一個元素不會被加倍。
要對元素按相反順序應用函數,請使用reduceRight()和foldRight()函數。它們的工作方式類似於fold()和reduce(),但從最後一個元素開始,然後繼續到前一個。請注意,當從右到左進行折疊或歸約時,操作參數會改變順序:首先是元素,然後是累積值。
val numbers = listOf(5, 2, 10, 4)
val sumDoubledRight = numbers.foldRight(0) { element, sum -> sum + element * 2 } // 0 + 4*2 + 10*2 + 2*2 + 5*2
println(sumDoubledRight) // 42
你還可以應用將元素索引作為參數的操作。為此,使用reduceIndexed()和foldIndexed()函數,將元素索引作為操作的第一個參數。
最後,有一些函數將此類操作應用於集合元素,從右到左——reduceRightIndexed()和foldRightIndexed()。
val numbers = listOf(5, 2, 10, 4)
val sumEven = numbers.foldIndexed(0) { idx, sum, element -> if (idx % 2 == 0) sum + element else sum }
println(sumEven) // 15
val sumEvenRight = numbers.foldRightIndexed(0) { idx, element, sum -> if (idx % 2 == 0) sum + element else sum }
println(sumEvenRight) // 14
所有的歸約操作在空集合上會拋出異常。要接收null,請使用它們的*OrNull()對應函數:
reduceOrNull()reduceRightOrNull()reduceIndexedOrNull()reduceRightIndexedOrNull()
如果你希望保存中間累加值,請使用runningFold()(或其同義詞scan())和runningReduce()函數。
val numbers = listOf(0, 1, 2, 3, 4, 5)
val runningReduceSum = numbers.runningReduce { sum, item -> sum + item }
val runningFoldSum = numbers.runningFold(10) { sum, item -> sum + item }
println(runningReduceSum) // [0, 1, 3, 6, 10, 15]
println(runningFoldSum) // [10, 10, 11, 13, 16, 20, 25]
如果你需要在操作參數中使用索引,請使用runningFoldIndexed()或runningReduceIndexed()。
集合寫操作
可變集合支持更改集合內容的操作,例如添加或移除元素。本頁將描述所有可變集合實現可用的寫操作。關於列表和映射的特定操作,請分別參見列表特定操作和映射特定操作。
添加元素
要向列表或集合添加單個元素,使用add()函數。指定的對象會附加到集合的末尾。
val numbers = mutableListOf(1, 2, 3, 4)
numbers.add(5)
println(numbers) // [1, 2, 3, 4, 5]
addAll()將參數對象的每個元素添加到列表或集合。參數可以是Iterable、Sequence或Array。接收者和參數的類型可以不同,例如,可以將集合中的所有項目添加到列表中。
當在列表上調用時,addAll()按參數中的順序添加新元素。你也可以在調用addAll()時指定元素位置作為第一個參數。參數集合的第一個元素將插入到此位置。參數集合的其他元素將跟隨它,將接收者元素移到末尾。
val numbers = mutableListOf(1, 2, 5, 6)
numbers.addAll(arrayOf(7, 8))
println(numbers) // [1, 2, 5, 6, 7, 8]
numbers.addAll(2, setOf(3, 4))
println(numbers) // [1, 2, 3, 4, 5, 6, 7, 8]
你還可以使用原地版本的加號操作符plusAssign (+=)添加元素。當應用於可變集合時,+=將第二個操作數(元素或另一個集合)附加到集合的末尾。
val numbers = mutableListOf("one", "two")
numbers += "three"
println(numbers) // [one, two, three]
numbers += listOf("four", "five")
println(numbers) // [one, two, three, four, five]
移除元素
要從可變集合中移除元素,使用remove()函數。remove()接受元素值並移除此值的第一個出現。
val numbers = mutableListOf(1, 2, 3, 4, 3)
numbers.remove(3) // 移除第一個`3`
println(numbers) // [1, 2, 4, 3]
numbers.remove(5) // 不移除任何東西
println(numbers) // [1, 2, 4, 3]
要一次移除多個元素,有以下函數:
removeAll()移除參數集合中的所有元素。或者,你可以將它與謂詞作為參數一起調用;在這種情況下,該函數會移除謂詞為true的所有元素。retainAll()是removeAll()的反向操作:它移除除參數集合之外的所有元素。當與謂詞一起使用時,它僅保留匹配謂詞的元素。clear()移除列表中的所有元素,並使其變空。
val numbers = mutableListOf(1, 2, 3, 4)
println(numbers) // [1, 2, 3, 4]
numbers.retainAll { it >= 3 }
println(numbers) // [3, 4]
numbers.clear()
println(numbers) // []
val numbersSet = mutableSetOf("one", "two", "three", "four")
numbersSet.removeAll(setOf("one", "two"))
println(numbersSet) // [three, four]
另一種從集合中移除元素的方法是使用減號操作符minusAssign (-=)——原地版本的minus。第二個參數可以是元素類型的單個實例或另一個集合。當右側是單個元素時,-=移除它的第一次出現。反之,如果它是一個集合,則會移除其元素的所有出現。例如,如果列表包含重複的元素,它們會一次性移除。第二個操作數可以包含集合中不存在的元素。這些元素不會影響操作的執行。
val numbers = mutableListOf("one", "two", "three", "three", "four")
numbers -= "three"
println(numbers) // [one, two, three, four]
numbers -= listOf("four", "five")
//numbers -= listOf("four") // 與上面相同
println(numbers) // [one, two, three]
更新元素
列表和映射還提供了用於更新元素的操作。它們在列表特定操作和映射特定操作中描述。對於集合,更新沒有意義,因為它實際上是移除一個元素並添加另一個元素。
這些操作使你能夠靈活地管理可變集合的內容,添加、移除和更新元素以滿足應用程序的需求。
List特定操作
列表是Kotlin中最受歡迎的內建集合類型。對列表元素的索引訪問提供了一套強大的操作。
按索引檢索元素
列表支持所有常見的元素檢索操作:elementAt()、first()、last()等。在列表中特定的是對元素的索引訪問,因此最簡單的讀取元素方式是通過索引檢索。這可以通過帶有索引作為參數的get()函數或簡寫的[index]語法來完成。
如果列表大小小於指定的索引,會拋出異常。有兩個其他函數可以幫助你避免這些異常:
getOrElse()允許你提供計算默認值的函數,以便在索引不存在時返回該值。getOrNull()返回null作為默認值。
val numbers = listOf(1, 2, 3, 4)
println(numbers.get(0)) // 1
println(numbers[0]) // 1
//numbers.get(5) // exception!
println(numbers.getOrNull(5)) // null
println(numbers.getOrElse(5) { it }) // 5
檢索列表部分
除了檢索集合部分的常見操作外,列表還提供了subList()函數,該函數返回指定元素範圍的視圖作為列表。因此,如果原始集合的元素發生變化,它也會在先前創建的子列表中變化,反之亦然。
val numbers = (0..13).toList()
println(numbers.subList(3, 6)) // [3, 4, 5]
查找元素位置
線性搜索
在任何列表中,你可以使用indexOf()和lastIndexOf()函數查找元素的位置。它們返回列表中等於給定參數的元素的第一個和最後一個位置。如果沒有這樣的元素,這兩個函數返回-1。
val numbers = listOf(1, 2, 3, 4, 2, 5)
println(numbers.indexOf(2)) // 1
println(numbers.lastIndexOf(2)) // 4
還有一對函數,它們接受謂詞並搜索匹配的元素:
indexOfFirst()返回匹配謂詞的第一個元素的索引,如果沒有這樣的元素則返回-1。indexOfLast()返回匹配謂詞的最後一個元素的索引,如果沒有這樣的元素則返回-1。
val numbers = mutableListOf(1, 2, 3, 4)
println(numbers.indexOfFirst { it > 2}) // 2
println(numbers.indexOfLast { it % 2 == 1}) // 2
有序列表中的二分搜索
還有一種在列表中搜索元素的方法——二分搜索。它比其他內建搜索函數快得多,但要求列表按某個順序升序排序:自然順序或函數參數中提供的其他順序。否則,結果是未定義的。
要在排序列表中搜索元素,調用binarySearch()函數並傳遞值作為參數。如果存在這樣的元素,該函數返回其索引;否則,它返回(-insertionPoint - 1),其中insertionPoint是應插入此元素以保持列表排序的索引。如果有多個具有給定值的元素,搜索可以返回其中任何一個的索引。
你還可以指定一個索引範圍進行搜索:在這種情況下,該函數僅在提供的兩個索引之間搜索。
val numbers = mutableListOf("one", "two", "three", "four")
numbers.sort()
println(numbers) // [four, one, three, two]
println(numbers.binarySearch("two")) // 3
println(numbers.binarySearch("z")) // -5
println(numbers.binarySearch("two", 0, 2)) // -3
使用Comparator的二分搜索
當列表元素不可比較時,你應該提供一個Comparator來使用二分搜索。列表必須根據此Comparator按升序排序。讓我們看一個例子:
val productList = listOf(
Product("WebStorm", 49.0),
Product("AppCode", 99.0),
Product("DotTrace", 129.0),
Product("ReSharper", 149.0))
println(productList.binarySearch(Product("AppCode", 99.0), compareBy<Product> { it.price }.thenBy { it.name }))
這裡有一個Product實例的列表,這些實例不可比較,還有一個定義順序的Comparator:如果p1的價格小於p2的價格,則p1在p2之前。因此,擁有按此順序升序排列的列表,我們使用binarySearch()來查找指定Product的索引。
當列表使用不同於自然順序的順序時,自定義比較器也很方便,例如,對字符串元素使用不區分大小寫的順序。
val colors = listOf("Blue", "green", "ORANGE", "Red", "yellow")
println(colors.binarySearch("RED", String.CASE_INSENSITIVE_ORDER)) // 3
使用比較函數的二分搜索
使用比較函數進行二分搜索可以讓你在不提供顯式搜索值的情況下查找元素。相反,它接受一個將元素映射為Int值的比較函數,並搜索該函數返回零的元素。列表必須按所提供函數的升序排序;換句話說,從一個列表元素到下一個列表元素,比較返回值必須遞增。
data class Product(val name: String, val price: Double)
fun priceComparison(product: Product, price: Double) = sign(product.price - price).toInt()
fun main() {
val productList = listOf(
Product("WebStorm", 49.0),
Product("AppCode", 99.0),
Product("DotTrace", 129.0),
Product("ReSharper", 149.0))
println(productList.binarySearch { priceComparison(it, 99.0) }) // 1
}
比較器和比較函數的二分搜索也可以在列表範圍內執行。
列表寫操作
除了在集合寫操作中描述的集合修改操作外,可變列表還支持特定的寫操作。這些操作使用索引訪問元素,以擴展列表的修改功能。
添加
要將元素添加到列表的特定位置,使用add()和addAll()並提供元素插入位置作為附加參數。所有位於該位置之後的元素將右移。
val numbers = mutableListOf("one", "five", "six")
numbers.add(1, "two")
numbers.addAll(2, listOf("three", "four"))
println(numbers) // [one, two, three, four, five, six]
更新
列表還提供了替換給定位置的元素的函數——set()及其操作符形式[]。set()不會改變其他元素的索引。
val numbers = mutableListOf("one", "five", "three")
numbers[1] = "two"
println(numbers) // [one, two, three]
fill()簡單地將所有集合元素替換為指定值。
val numbers = mutableListOf(1, 2, 3, 4)
numbers.fill(3)
println(numbers) // [3, 3, 3, 3]
移除
要從列表中移除特定位置的元素,使用removeAt()函數並提供位置作為參數。被移除元素之後的所有元素索引將減少一。
val numbers = mutableListOf(1, 2, 3, 4, 3)
numbers.removeAt(1)
println(numbers) // [1, 3, 4, 3]
排序
在集合排序中,我們描述了按特定順序檢索集合元素的操作。對於可變列表,標準庫提供了類似的擴展函數,這些函數執行相同的排序操作。當你將這樣的操作應用於列表實例時,它會改變該實例中元素的順序。
原地排序函數的名稱與適用於只讀列表的函數名稱相似,但沒有ed/d後
綴:
- 所有排序函數的名稱中用
sort*代替sorted*:sort()、sortDescending()、sortBy()等。 shuffle()代替shuffled()。reverse()代替reversed()。
調用asReversed()於可變列表時,返回的另一個可變列表是原列表的反轉視圖。該視圖中的變更會反映在原始列表中。以下示例顯示了可變列表的排序函數:
val numbers = mutableListOf("one", "two", "three", "four")
numbers.sort()
println("Sort into ascending: $numbers") // [four, one, three, two]
numbers.sortDescending()
println("Sort into descending: $numbers") // [two, three, one, four]
numbers.sortBy { it.length }
println("Sort into ascending by length: $numbers") // [one, two, four, three]
numbers.sortByDescending { it.last() }
println("Sort into descending by the last letter: $numbers") // [four, two, one, three]
numbers.sortWith(compareBy<String> { it.length }.thenBy { it })
println("Sort by Comparator: $numbers") // [one, two, four, three]
numbers.shuffle()
println("Shuffle: $numbers") // [three, one, two, four]
numbers.reverse()
println("Reverse: $numbers") // [four, two, one, three]
這些操作使你能夠靈活地管理和修改列表中的元素,以滿足各種需求。
Set特定操作
Kotlin集合包中包含了一些常見操作的擴展函數,如查找交集、合併或從另一個集合中減去集合。
合併集合
要將兩個集合合併為一個集合,使用union()函數。它可以以中綴形式使用,即a union b。注意,對於有序集合,操作數的順序很重要。在結果集合中,第一個操作數的元素排在第二個操作數的元素之前:
val numbers = setOf("one", "two", "three")
// 按順序輸出
println(numbers union setOf("four", "five"))
// [one, two, three, four, five]
println(setOf("four", "five") union numbers)
// [four, five, one, two, three]
查找交集和差集
要查找兩個集合之間的交集(即同時存在於兩個集合中的元素),使用intersect()函數。要查找不在另一個集合中的集合元素,使用subtract()函數。這兩個函數也可以以中綴形式調用,例如a intersect b:
val numbers = setOf("one", "two", "three")
// 相同輸出
println(numbers intersect setOf("two", "one"))
// [one, two]
println(numbers subtract setOf("three", "four"))
// [one, two]
println(numbers subtract setOf("four", "three"))
// [one, two]
查找對稱差
要查找存在於兩個集合中的任一集合但不在其交集中存在的元素(即對稱差),你可以使用union()函數。對於這種操作,計算兩個集合之間的差異並合併結果:
val numbers = setOf("one", "two", "three")
val numbers2 = setOf("three", "four")
// 合併差異
println((numbers - numbers2) union (numbers2 - numbers))
// [one, two, four]
列表的集合操作
你也可以將union()、intersect()和subtract()函數應用於列表。不過,它們的結果總是set。在這個結果中,所有的重複元素都會合併為一個,且無法進行索引訪問:
val list1 = listOf(1, 1, 2, 3, 5, 8, -1)
val list2 = listOf(1, 1, 2, 2, 3, 5)
// 兩個列表相交的結果是一個集合
println(list1 intersect list2)
// [1, 2, 3, 5]
// 相同元素合併為一個
println(list1 union list2)
// [1, 2, 3, 5, 8, -1]
這些操作使你能夠靈活地管理和操作set,以滿足不同的需求。
Map 特定操作
在 Map 中,鍵和值的類型是用戶定義的。基於鍵的訪問使得 Map 特定的處理功能變得可能,從通過鍵獲取值到分別過濾鍵和值。在本頁中,我們將介紹標準庫中的 Map 處理函數。
檢索鍵和值
要從 Map 中檢索值,必須提供鍵作為 get() 函數的參數。也支持簡寫的 [key] 語法。如果找不到給定的鍵,則返回 null。還有一個 getValue() 函數,其行為略有不同:如果在 Map 中找不到鍵,則會拋出異常。此外,還有兩個選項來處理鍵的缺失:
getOrElse()的工作方式與列表相同:不存在鍵的值從給定的 lambda 函數返回。getOrDefault()在找不到鍵時返回指定的默認值。
val numbersMap = mapOf("one" to 1, "two" to 2, "three" to 3)
println(numbersMap.get("one")) // 1
println(numbersMap["one"]) // 1
println(numbersMap.getOrDefault("four", 10)) // 10
println(numbersMap["five"]) // null
//numbersMap.getValue("six") // exception!
要對 Map 的所有鍵或所有值執行操作,可以分別從 keys 和 values 屬性中檢索它們。keys 是一組所有 Map 鍵,values 是所有 Map 值的集合。
val numbersMap = mapOf("one" to 1, "two" to 2, "three" to 3)
println(numbersMap.keys) // [one, two, three]
println(numbersMap.values) // [1, 2, 3]
過濾
你可以使用 filter() 函數來過濾 Map,與其他集合一樣。當對 Map 調用 filter() 時,將一個帶有 Pair 作為參數的謂詞(predicate)傳遞給它。這使得你可以在過濾謂詞中同時使用鍵和值。
val numbersMap = mapOf("key1" to 1, "key2" to 2, "key3" to 3, "key11" to 11)
val filteredMap = numbersMap.filter { (key, value) -> key.endsWith("1") && value > 10}
println(filteredMap) // {key11=11}
還有兩種特定的過濾 Map 的方法:按鍵和按值。對於每種方法,都有一個函數:filterKeys() 和 filterValues()。這兩個函數都返回一個新的 Map,其中包含匹配給定謂詞的 entries。filterKeys() 的謂詞只檢查元素的鍵,filterValues() 的謂詞只檢查值。
val numbersMap = mapOf("key1" to 1, "key2" to 2, "key3" to 3, "key11" to 11)
val filteredKeysMap = numbersMap.filterKeys { it.endsWith("1") }
val filteredValuesMap = numbersMap.filterValues { it < 10 }
println(filteredKeysMap) // {key1=1, key11=11}
println(filteredValuesMap) // {key1=1, key2=2, key3=3}
加號和減號操作符
由於基於鍵訪問元素,加號 (+) 和減號 (-) 操作符在 Map 中的工作方式與其他集合不同。加號返回一個包含其兩個操作數元素的 Map:左側的 Map 和右側的 Pair 或另一個 Map。當右側操作數包含鍵存在於左側 Map 中的 entries 時,結果 Map 包含來自右側的 entries。
val numbersMap = mapOf("one" to 1, "two" to 2, "three" to 3)
println(numbersMap + Pair("four", 4)) // {one=1, two=2, three=3, four=4}
println(numbersMap + Pair("one", 10)) // {one=10, two=2, three=3}
println(numbersMap + mapOf("five" to 5, "one" to 11)) // {one=11, two=2, three=3, five=5}
減號從左側 Map 中的 entries 創建一個 Map,除了右側操作數中的鍵。所以,右側操作數可以是單個鍵或鍵的集合:列表、集合等。
val numbersMap = mapOf("one" to 1, "two" to 2, "three" to 3)
println(numbersMap - "one") // {two=2, three=3}
println(numbersMap - listOf("two", "four")) // {one=1, three=3}
有關在可變 Map 上使用加號賦值 (+=) 和減號賦值 (-=) 操作符的詳細信息,請參見下面的 Map 寫操作。
Map 寫操作
可變 Map(Mutable maps) 提供 Map 特定的寫操作。這些操作允許你使用基於鍵的訪問來更改 Map 內容。
有些規則定義了 Map 上的寫操作:
- 值可以更新。反之,鍵永遠不變:一旦添加 entry,其鍵是固定的。
- 對於每個鍵,總是有一個與之關聯的單個值。你可以添加和移除整個 entry。
以下是標準庫中可變 Map 上可用的寫操作函數的描述。
添加和更新 entry
要向可變 Map 添加新的鍵值對,使用 put()。當將新 entry 放入 LinkedHashMap(默認 Map 實現)時,它會被添加,使其在迭代 Map 時出現在最後。在排序 Map 中,新元素的位置由其鍵的順序定義。
val numbersMap = mutableMapOf("one" to 1, "two" to 2)
numbersMap.put("three", 3)
println(numbersMap) // {one=1, two=2, three=3}
要一次添加多個 entry,使用 putAll()。其參數可以是 Map 或一組 Pair:Iterable、Sequence 或 Array。
val numbersMap = mutableMapOf("one" to 1, "two" to 2, "three" to 3)
numbersMap.putAll(setOf("four" to 4, "five" to 5))
println(numbersMap) // {one=1, two=2, three=3, four=4, five=5}
put() 和 putAll() 都會覆蓋已存在鍵的值。因此,你可以使用它們來更新 Map entries 的值。
val numbersMap = mutableMapOf("one" to 1, "two" to 2)
val previousValue = numbersMap.put("one", 11)
println("value associated with 'one', before: $previousValue, after: ${numbersMap["one"]}")
println(numbersMap) // {one=11, two=2}
你也可以使用簡寫操作符形式向 Map 添加新 entry。有兩種方式:
plusAssign (+=)操作符。[]操作符的set()別名。
val numbersMap = mutableMapOf("one" to 1, "two" to 2)
numbersMap["three"] = 3 // 調用 numbersMap.put("three", 3)
numbersMap += mapOf("four" to 4, "five" to 5)
println(numbersMap) // {one=1, two=2, three=3, four=4, five=5}
當鍵存在於 Map 中時,操作符會覆蓋相應 entry 的值。
移除 entry
要從可變 Map 中移除 entry,使用 remove() 函數。調用 remove() 時,可以傳遞鍵或整個鍵值對。如果同時指定了鍵和值,則只有當值與第二個參數匹配時,該鍵的元素才會被移除。
val numbersMap = mutableMapOf("one" to 1, "two" to 2, "three" to 3)
numbersMap.remove("one")
println(numbersMap) // {two=2, three=3}
numbersMap.remove("three", 4) // 不移除任何東西
println(numbersMap) // {two=2, three=3}
你也可以根據鍵或值從可變 Map 中移除 entries。要做到這一點,調用 remove() 在 Map 的 `
keys或values中提供鍵或值。如果調用values,remove()` 只會移除第一個與給定值匹配的 entry。
val numbersMap = mutableMapOf("one" to 1, "two" to 2, "three" to 3, "threeAgain" to 3)
numbersMap.keys.remove("one")
println(numbersMap) // {two=2, three=3, threeAgain=3}
numbersMap.values.remove(3)
println(numbersMap) // {two=2, threeAgain=3}
minusAssign (-=) 操作符同樣適用於可變 Map。
val numbersMap = mutableMapOf("one" to 1, "two" to 2, "three" to 3)
numbersMap -= "two"
println(numbersMap) // {one=1, three=3}
numbersMap -= "five" // 不移除任何東西
println(numbersMap) // {one=1, three=3}【Kotlin】Collection
來源: https://kotlinlang.org/docs/collections-overview.html
cheatsheet: 網站 , xantier_kotlin_collection-extensions.pdf
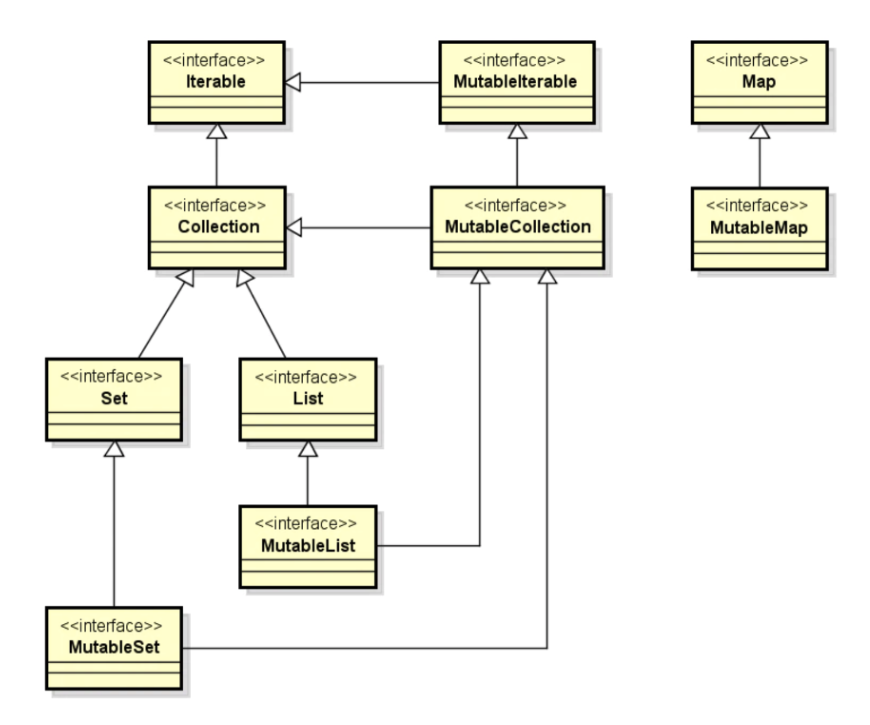
【集合概述】
Kotlin標準庫提供了一套全面的工具來管理集合——這些集合是問題解決中重要且經常操作的變數數量(可能為零)的項目群組。
集合是大多數編程語言中的常見概念,所以如果你熟悉例如Java或Python的集合,可以跳過這個介紹,直接進入詳細章節。
一個集合通常包含相同類型(及其子類型)的若干對象。集合中的對象稱為元素或項目。例如,一個系所的所有學生形成一個集合,可以用來計算他們的平均年齡。
以下是Kotlin中相關的集合類型:
-
List是一個有序集合,可以通過索引——反映其位置的整數——訪問元素。元素在列表中可以出現多次。列表的一個例子是電話號碼:它是一組數字,順序很重要,而且可以重複。
-
Set是一個唯一元素的集合。它反映了數學上的集合抽象:一組不重複的對象。一般來說,集合元素的順序沒有意義。例如,彩票上的號碼形成一個集合:它們是唯一的,順序並不重要。
-
Map(或字典)是一組鍵值對。鍵是唯一的,每個鍵映射到一個確切的值。值可以重複。Map用於存儲對象之間的邏輯連接,例如員工的ID和他們的職位。
Kotlin允許你在操作集合時,不用考慮存儲在其中的對象的確切類型。換句話說,向字符串列表中添加字符串的方式與向整數列表或自定義類別列表中添加元素的方式相同。因此,Kotlin標準庫提供了泛型介面、類別和函數,用於創建、填充和管理任何類型的集合。
集合介面和相關函數位於kotlin.collections package中。我們來概覽一下其內容。
【構建集合】
從元素構建
創建集合最常見的方法是使用標準庫函數listOf<T>()、setOf<T>()、mutableListOf<T>()、mutableSetOf<T>()。如果你提供一個以逗號分隔的集合元素列表作為參數,編譯器會自動檢測元素類型。在創建空集合時,需要明確指定類型。
val numbersSet = setOf("one", "two", "three", "four")
val emptySet = mutableSetOf<String>()
同樣的功能也適用於map,使用函數mapOf()和mutableMapOf()。map的鍵和值是以Pair對象傳遞的(通常通過to中綴函數創建)。
val numbersMap = mapOf("key1" to 1, "key2" to 2, "key3" to 3, "key4" to 1)
需要注意的是,to表示法會創建一個短暫存在的Pair對象,所以建議僅在性能不是關鍵時使用它。為了避免過多的記憶體使用,可以使用其他方式。例如,可以創建一個可變map並使用寫操作來填充它。apply()函數可以幫助保持初始化的流暢性。
val numbersMap = mutableMapOf<String, String>().apply {
this["one"] = "1"
this["two"] = "2"
}
使用集合構建函數創建
另一種創建集合的方法是調用構建函數——buildList()、buildSet()或buildMap()。它們創建一個新的、可變的相應類型的集合,使用寫操作填充它,然後返回包含相同元素的只讀集合:
val map = buildMap {
put("a", 1)
put("b", 0)
put("c", 4)
}
println(map) // {a=1, b=0, c=4}
空集合
也有一些函數可以創建沒有任何元素的集合:emptyList()、emptySet()和emptyMap()。在創建空集合時,應該明確指定集合將持有的元素類型。
val empty = emptyList<String>()
List的初始化函數
對於list,有一個類似構造函數的函數,它接受列表大小和基於索引定義元素值的初始化函數。
val doubled = List(3) { it * 2 }
println(doubled)
// [0, 2, 4]具體類型構造函數
要創建具體類型的集合,例如ArrayList或LinkedList,可以使用這些類型的可用構造函數。對於Set和Map的實現也有類似的構造函數。
val linkedList = LinkedList<String>(listOf("one", "two", "three"))
val presizedSet = HashSet<Int>(32)
複製
要創建一個包含與現有集合相同元素的集合,可以使用複製函數。標準庫的集合複製函數會創建淺層複製集合,引用相同的元素。因此,對集合元素所做的更改會反映在所有其副本中。
集合複製函數,如toList()、toMutableList()、toSet()等,會在特定時刻創建集合的快照。其結果是一個包含相同元素的新集合。如果從原集合中添加或移除元素,這不會影響副本。副本可以獨立於源進行更改。
val alice = Person("Alice")
val sourceList = mutableListOf(alice, Person("Bob"))
val copyList = sourceList.toList()
sourceList.add(Person("Charles"))
alice.name = "Alicia"
println("First item's name is: ${sourceList[0].name} in source and ${copyList[0].name} in copy")
println("List size is: ${sourceList.size} in source and ${copyList.size} in copy")
// First item's name is: Alicia in source and Alicia in copy
// List size is: 3 in source and 2 in copy這些函數也可以用來將集合轉換為其他類型,例如從列表構建集合,反之亦然。
val sourceList = mutableListOf(1, 2, 3)
val copySet = sourceList.toMutableSet()
copySet.add(3)
copySet.add(4)
println(copySet)
// [1, 2, 3, 4]另外,可以創建對同一集合實例的新引用。當你使用現有集合初始化一個集合變量時,就會創建新引用。因此,當通過某個引用修改集合實例時,這些更改會反映在所有引用中。
val sourceList = mutableListOf(1, 2, 3)
val referenceList = sourceList
referenceList.add(4)
println("Source size: ${sourceList.size}") // Source size: 4
集合初始化可以用來限制可變性。例如,如果你創建一個List引用到一個MutableList,編譯器會在你試圖通過此引用修改集合時產生錯誤。
val sourceList = mutableListOf(1, 2, 3)
val referenceList: List<Int> = sourceList
//referenceList.add(4) //compilation error
sourceList.add(4)
println(referenceList) // shows the current state of sourceList
調用其他集合上的函數
集合可以作為對其他集合進行各種操作的結果來創建。例如,過濾列表會創建一個包含匹配過濾條件的元素的新列表:
val numbers = listOf("one", "two", "three", "four")
val longerThan3 = numbers.filter { it.length > 3 }
println(longerThan3)
// [three, four]
map 會根據轉換結果產生一個列表:
val numbers = setOf(1, 2, 3)
println(numbers.map { it * 3 })
println(numbers.mapIndexed { idx, value -> value * idx })
// [3, 6, 9]
// [0, 2, 6]associate 產生maps:
val numbers = listOf("one", "two", "three", "four")
println(numbers.associateWith { it.length })
// {one=3, two=3, three=5, four=4}有關Kotlin中集合操作的更多信息,請參見集合操作概述。
【迭代器(Iterator)】
為了遍歷集合元素,Kotlin標準庫支持常用的迭代器機制——這些對象可以順序地訪問元素而不暴露集合的底層結構。當你需要一個一個地處理集合中的所有元素時,迭代器非常有用,例如,打印值或進行類似的更新。
迭代器可以通過調用iterator()函數從Iterable<T>介面的繼承者(包括Set和List)獲得。
一旦獲得迭代器,它會指向集合的第一個元素;調用next()函數返回該元素並將迭代器位置移動到下一個元素(如果存在的話)。
一旦迭代器遍歷了最後一個元素,它將不能再用於檢索元素;也不能將其重置到任何先前的位置。要再次遍歷集合,需要創建一個新的迭代器。
val numbers = listOf("one", "two", "three", "four")
val numbersIterator = numbers.iterator()
while (numbersIterator.hasNext()) {
println(numbersIterator.next())
// one
// two
// three
// four
}
另一種遍歷Iterable集合的方法是眾所周知的for循環。當在集合上使用for時,你會隱式地獲得迭代器。因此,下面的代碼等同於上面的例子:
val numbers = listOf("one", "two", "three", "four")
for (item in numbers) {
println(item)
// one
// two
// three
// four
}
最後,有一個有用的forEach()函數,讓你可以自動迭代集合並為每個元素執行給定的代碼。因此,相同的例子看起來如下:
val numbers = listOf("one", "two", "three", "four")
numbers.forEach {
println(it)
// one
// two
// three
// four
}
列表迭代器
對於列表,有一個特殊的迭代器實現:ListIterator。它支持雙向迭代列表:向前和向後。
向後迭代通過hasPrevious()和previous()函數實現。此外,ListIterator還提供有關元素索引的信息,通過nextIndex()和previousIndex()函數。
val numbers = listOf("one", "two", "three", "four")
val listIterator = numbers.listIterator()
while (listIterator.hasNext()) listIterator.next()
println("Iterating backwards:")
// Iterating backwards:
while (listIterator.hasPrevious()) {
print("Index: ${listIterator.previousIndex()}")
println(", value: ${listIterator.previous()}")
// Index: 3, value: four
// Index: 2, value: three
// Index: 1, value: two
// Index: 0, value: one
}
能夠雙向迭代意味著ListIterator在到達最後一個元素後仍然可以使用。
可變迭代器
對於迭代可變集合,有MutableIterator,它擴展了Iterator並增加了元素移除函數remove()。因此,你可以在迭代集合時移除元素。
val numbers = mutableListOf("one", "two", "three", "four")
val mutableIterator = numbers.iterator()
mutableIterator.next()
mutableIterator.remove()
println("After removal: $numbers")
// After removal: [two, three, four]
除了移除元素外,MutableListIterator還可以在迭代列表時插入和替換元素,通過使用add()和set()函數。
val numbers = mutableListOf("one", "four", "four")
val mutableListIterator = numbers.listIterator()
mutableListIterator.next()
mutableListIterator.add("two")
println(numbers)
// [one, two, four, four]
mutableListIterator.next()
mutableListIterator.set("three")
println(numbers)
// [one, two, three, four]【範圍(Ranges)與級數(Progessions)】
Kotlin允許你使用kotlin.ranges包中的.rangeTo()和.rangeUntil()函數輕鬆創建值的範圍。
範圍
要創建:
- 閉合範圍,使用
..運算符調用.rangeTo()函數。 - 開放範圍,使用
..<運算符調用.rangeUntil()函數。
例如:
// 閉合範圍
println(4 in 1..4) // true
// 開放範圍
println(4 in 1..<4) // false
範圍特別適用於在for循環中進行迭代:
for (i in 1..4) print(i)
// 1234
要反向迭代數字,可以使用downTo函數代替..:
for (i in 4 downTo 1) print(i)
// 4321
也可以使用step函數以任意步長(不一定是1)迭代數字:
for (i in 0..8 step 2) print(i)
println()
// 02468
for (i in 0..<8 step 2) print(i)
println()
// 0246
for (i in 8 downTo 0 step 2) print(i)
// 86420
級數
整數類型(如Int、Long和Char)的範圍可以視為算術級數。在Kotlin中,這些級數由特定類型定義:IntProgression、LongProgression和CharProgression。
級數有三個基本屬性:第一個元素、最後一個元素和非零步長。第一個元素是first,隨後的元素是前一個元素加上步長。帶有正步長的級數迭代等同於Java/JavaScript中的索引for循環。
for (int i = first; i <= last; i += step) {
// ...
}
當你通過迭代範圍隱式地創建級數時,這個級數的第一個和最後一個元素是範圍的端點,步長為1。
for (i in 1..10) print(i)
// 12345678910
要定義自訂的級數步長,可以在範圍上使用step函數。
for (i in 1..8 step 2) print(i)
// 1357
級數的最後一個元素計算方法如下:
- 對於正步長:不大於結束值的最大值,使得
(last - first) % step == 0。 - 對於負步長:不小於結束值的最小值,使得
(last - first) % step == 0。
因此,最後一個元素不一定是指定的結束值。
for (i in 1..9 step 3) print(i) // 最後一個元素是7
// 147
級數實現了Iterable<N>,其中N分別是Int、Long或Char,所以你可以在各種集合函數中使用它們,如map、filter等。
println((1..10).filter { it % 2 == 0 })
// [2, 4, 6, 8, 10]【序列(Sequence)】
除了集合,Kotlin標準庫還包含另一種類型——序列(Sequence)。與集合不同,序列不包含元素,而是在迭代時生成它們。序列提供與Iterable相同的函數,但實現了另一種多步集合處理的方法。
當對Iterable進行多步處理時,這些步驟是急切執行的:每個處理步驟完成並返回其結果——一個中間集合。下一步在這個集合上執行。相反,序列的多步處理在可能的情況下是懶惰執行的:實際計算僅在請求整個處理鏈的結果時發生。
操作執行的順序也不同:序列對每個元素依次執行所有處理步驟。相反,Iterable完成整個集合的每一步,然後進入下一步。
因此,序列使你可以避免構建中間步驟的結果,從而提高整個集合處理鏈的性能。然而,序列的懶惰性質增加了一些開銷,這在處理較小的集合或進行簡單計算時可能是顯著的。因此,你應該同時考慮序列和Iterable,並決定哪個更適合你的情況。
創建
從元素創建
要創建序列,請調用sequenceOf()函數並列出其參數中的元素。
val numbersSequence = sequenceOf("four", "three", "two", "one")
從Iterable創建
如果你已經有一個Iterable對象(例如List或Set),可以通過調用asSequence()從中創建序列。
val numbers = listOf("one", "two", "three", "four")
val numbersSequence = numbers.asSequence()
從函數創建
另一種創建序列的方法是使用計算其元素的函數來構建它。要基於函數創建序列,請調用generateSequence()並將此函數作為參數。可以選擇性地將第一個元素指定為明確的值或函數調用的結果。當提供的函數返回null時,序列生成停止。因此,下面示例中的序列是無限的。
val oddNumbers = generateSequence(1) { it + 2 } // `it` 是前一個元素
println(oddNumbers.take(5).toList())
// println(oddNumbers.count()) // 錯誤:序列是無限的
要使用generateSequence()創建有限序列,請提供在最後一個元素之後返回null的函數。
val oddNumbersLessThan10 = generateSequence(1) { if (it < 8) it + 2 else null }
println(oddNumbersLessThan10.count())
從塊創建(from chunks)
最後,有一個函數允許你逐個或按任意大小的塊生成序列元素——sequence()函數。該函數接受包含yield()和yieldAll()函數調用的lambda表達式。它們將元素返回給序列消費者,並掛起sequence()的執行,直到消費者請求下一個元素。yield()以單個元素作為參數;yieldAll()可以接受Iterable對象、迭代器或另一個序列。yieldAll()的序列參數可以是無限的。然而,這樣的調用必須是最後一個:所有後續調用將永遠不會執行。
val oddNumbers = sequence {
yield(1)
yieldAll(listOf(3, 5))
yieldAll(generateSequence(7) { it + 2 })
}
println(oddNumbers.take(5).toList())
// [1, 3, 5, 7, 9]
序列操作
序列操作根據其狀態要求分為以下幾類:
- 無狀態操作:不需要狀態並獨立處理每個元素,例如
map()或filter()。無狀態操作也可以需要少量常數狀態來處理元素,例如take()或drop()。 - 有狀態操作:需要大量狀態,通常與序列中元素的數量成正比。
如果序列操作返回另一個序列,該序列是懶惰生成的,則稱為中間操作。否則,該操作是終端操作。例如,終端操作包括toList()或sum()。序列元素只能通過終端操作檢索。
序列可以多次迭代;但是某些序列實現可能會限制自己只能迭代一次。在它們的文檔中會特別提到這一點。
序列處理示例
讓我們通過一個例子來看看Iterable和序列之間的區別。
Iterable
假設你有一個單詞列表。下面的代碼過濾出長度超過三個字符的單詞,並打印出前四個這樣的單詞的長度。
val words = "The quick brown fox jumps over the lazy dog".split(" ")
val lengthsList = words.filter { println("filter: $it"); it.length > 3 }
.map { println("length: ${it.length}"); it.length }
.take(4)
println("Lengths of first 4 words longer than 3 chars:")
println(lengthsList)
/*
filter: The
filter: quick
filter: brown
filter: fox
filter: jumps
filter: over
filter: the
filter: lazy
filter: dog
length: 5
length: 5
length: 5
length: 4
length: 4
Lengths of first 4 words longer than 3 chars:
[5, 5, 5, 4]
*/運行此代碼時,你會看到filter()和map()函數按代碼中出現的順序執行。首先,你會看到所有元素的filter:,然後是過濾後的元素的length:,最後是最後兩行的輸出。
這就是列表處理的方式:
列表處理
序列
現在用序列寫相同的代碼:
val words = "The quick brown fox jumps over the lazy dog".split(" ")
// 將List轉換為Sequence
val wordsSequence = words.asSequence()
val lengthsSequence = wordsSequence.filter { println("filter: $it"); it.length > 3 }
.map { println("length: ${it.length}"); it.length }
.take(4)
println("Lengths of first 4 words longer than 3 chars:")
// 終端操作:將結果作為List獲取
println(lengthsSequence.toList())
/**
Lengths of first 4 words longer than 3 chars:
filter: The
filter: quick
length: 5
filter: brown
length: 5
filter: fox
filter: jumps
length: 5
filter: over
length: 4
[5, 5, 5, 4]
*/此代碼的輸出顯示,filter()和map()函數僅在構建結果列表時調用。因此,你首先看到文本行"Lengths of..",然後序列處理開始。注意,對於過濾後的元素,map在過濾下一個元素之前執行。當結果大小達到4時,處理停止,因為這是take(4)可以返回的最大大小。
序列處理如下:
序列處理
在此示例中,序列處理用了18步,而使用列表的處理用了23步。
希望這些範例有助於你在開發Kotlin程式時瞭解序列與集合的使用差異及其優劣勢,特別是在處理多步集合操作時。
【集合操作概述】
Kotlin標準庫提供了多種函數,用於對集合進行操作。這些操作包括簡單的操作(如獲取或添加元素)以及更複雜的操作(如搜索、排序、過濾、轉換等)。
擴展函數與成員函數
集合操作在標準庫中以兩種方式聲明:集合介面的成員函數和擴展函數。
成員函數定義了集合類型所必需的操作。例如,Collection包含檢查其是否為空的函數isEmpty();List包含用於索引訪問元素的函數get()等。
當你創建自己的集合介面實現時,必須實現其成員函數。為了使新實現的創建更容易,可以使用標準庫中的集合介面的骨架實現:AbstractCollection、AbstractList、AbstractSet、AbstractMap及其可變對應物。
其他集合操作則聲明為擴展函數。這些包括過濾、轉換、排序和其他集合處理函數。
常用操作
常用操作可用於只讀和可變集合。常用操作分為以下幾組:
- 轉換 (map, zip, associate, flatten)
- 過濾 (filter)
- 加號和減號操作符 (+, -)
- 分組 (groupBy)
- 檢索集合部分 (slice, tack drop, chunked, window)
- 檢索單個元素 (get, find, first, last, random)
- 排序 (sorted)
- 聚合操作 (minOrNull, maxOrNull, average, sum, count, fold, reduce)
這些頁面上描述的操作返回其結果而不影響原始集合。例如,過濾操作生成一個包含所有匹配過濾條件的元素的新集合。這些操作的結果應該存儲在變量中,或以其他方式使用,例如,傳遞給其他函數。
val numbers = listOf("one", "two", "three", "four")
numbers.filter { it.length > 3 } // numbers沒有任何變化,結果丟失
println("numbers are still $numbers")
val longerThan3 = numbers.filter { it.length > 3 } // 結果存儲在longerThan3中
println("numbers longer than 3 chars are $longerThan3")
對於某些集合操作,可以指定目標對象。目標對象是可變集合,函數將其結果項附加到該集合中,而不是返回新的對象。對於具有目標的操作,有帶有To後綴的單獨函數名稱,例如filterTo()代替filter()或associateTo()代替associate()。這些函數將目標集合作為附加參數。
val numbers = listOf("one", "two", "three", "four")
val filterResults = mutableListOf<String>() // 目標對象
numbers.filterTo(filterResults) { it.length > 3 }
println(filterResults) // [three, four]
numbers.filterIndexedTo(filterResults) { index, _ -> index == 0 }
println(filterResults) // [three, four, one] 包含兩次操作的結果為了方便起見,這些函數返回目標集合,因此你可以在函數調用的相應參數中直接創建它:
// 將數字過濾到新的Hashset,從而消除結果中的重複項
val numbers = listOf("one", "two", "three", "four")
val result = numbers.mapTo(HashSet()) { it.length }
println("distinct item lengths are $result")
// distinct item lengths are [3, 4, 5]
或是已經初始化後的資料附加在後面
val numbers = listOf("one", "two", "three", "four", "five")
val tmpMap = mutableListOf<String>("aa")
val tmpMap2 = mutableListOf<String>("bb")
println(numbers.mapTo(tmpMap){it})
// [aa, one, two, three, four, five]
println(numbers.filterTo(tmpMap2){it.length > 3})
// [bb, three, four, five]寫操作
對於可變集合,還有改變集合狀態的寫操作。這些操作包括添加、刪除和更新元素。寫操作列在寫操作以及List特定操作和Map特定操作的對應部分中。
對於某些操作,有成對的函數執行相同的操作:一個在原地應用操作,另一個返回結果作為單獨的集合。例如,sort()對可變集合進行原地排序,因此其狀態改變;sorted()創建一個包含相同元素的新集合,按排序順序排列。
val numbers = mutableListOf("one", "two", "three", "four")
val sortedNumbers = numbers.sorted()
println(sortedNumbers) // [four, one, three, two]
println(numbers == sortedNumbers) // false
numbers.sort()
println(numbers) // [four, one, three, two]
println(numbers == sortedNumbers) // true【集合轉換操作】
Kotlin標準庫提供了一組用於集合轉換的擴展函數。這些函數根據提供的轉換規則從現有集合構建新集合。以下是可用的集合轉換函數概述。
映射 (Map)
- map
- mapIndexed
- mapNotNull
- mapIndexedNotNull
- mapKeys
- mapValues
映射轉換通過對另一個集合的元素應用函數來創建集合。基本的映射函數是map()。它將給定的lambda函數應用於每個元素,並返回lambda結果的列表。結果的順序與原始元素的順序相同。要應用同時使用元素索引作為參數的轉換,請使用mapIndexed()。
val numbers = setOf(1, 2, 3)
println(numbers.map { it * 3 })
// [3, 6, 9]
println(numbers.mapIndexed { idx, value -> value * idx })
// [0, 2, 6]如果轉換在某些元素上產生null,可以通過調用mapNotNull()代替map(),或mapIndexedNotNull()代替mapIndexed()來過濾結果集合中的null。
val numbers = setOf(1, 2, 3)
println(numbers.mapNotNull { if (it == 2) null else it * 3 })
// [3, 9]
println(numbers.mapIndexedNotNull { idx, value -> if (idx == 0) null else value * idx })
// [2, 6]在轉換Map時,你有兩個選擇:變換鍵而保持值不變,反之亦然。要對鍵應用給定的轉換,使用mapKeys();反過來,mapValues()轉換值。這兩個函數都使用將map條目作為參數的轉換,因此你可以同時操作其鍵和值。
val numbersMap = mapOf("key1" to 1, "key2" to 2, "key3" to 3, "key11" to 11)
println(numbersMap.mapKeys { it.key.uppercase() })
// {KEY1=1, KEY2=2, KEY3=3, KEY11=11}
println(numbersMap.mapValues { it.value + it.key.length })
// {key1=5, key2=6, key3=7, key11=16}
Zip
zip轉換是從兩個集合中相同位置的元素構建對。在Kotlin標準庫中,這是通過zip()擴展函數完成的。
當在一個集合或數組上調用並將另一個集合(或數組)作為參數時,zip()返回一個Pair對象的列表。接收集合的元素是這些對中的第一個元素。
如果集合大小不同,zip()的結果是較小的大小;較大集合的最後元素不包括在結果中。
zip()也可以以中綴形式調用,即a zip b。
val colors = listOf("red", "brown", "grey")
val animals = listOf("fox", "bear", "wolf")
println(colors zip animals)
// [(red, fox), (brown, bear), (grey, wolf)]
val twoAnimals = listOf("fox", "bear")
println(colors.zip(twoAnimals))
// [(red, fox), (brown, bear)]你也可以用一個帶有兩個參數的轉換函數調用zip():接收元素和參數元素。在這種情況下,結果列表包含對接收元素和參數元素的對調用轉換函數的返回值。
val colors = listOf("red", "brown", "grey")
val animals = listOf("fox", "bear", "wolf")
println(colors.zip(animals) { color, animal -> "The ${animal.replaceFirstChar { it.uppercase() }} is $color"})
// [The Fox is red, The Bear is brown, The Wolf is grey]當你有一個Pair列表時,可以進行反向轉換——解壓縮,從這些對中構建兩個列表:
第一個列表包含原始列表中每個Pair的第一個元素。
第二個列表包含第二個元素。
要解壓縮一個Pair列表,調用unzip()。
val numberPairs = listOf("one" to 1, "two" to 2, "three" to 3, "four" to 4)
println(numberPairs.unzip()) // 返回 pair ([one, two, three, four], [1, 2, 3, 4])
println(numberPairs.unzip().toList()) // 返回 List [[one, two, three, four], [1, 2, 3, 4]]關聯 (Associate) (list to map)
- associateWith
- associateWithTo
- associateBy
- associate
關聯轉換允許從集合元素及其相關的某些值構建map。在不同的關聯類型中,元素可以是關聯map中的鍵或值。
基本的關聯函數associateWith()創建一個map,其中原始集合的元素是鍵,值是由給定的轉換函數生成的。如果兩個元素相等,只有最後一個會保留在map中。
val numbers = listOf("one", "two", "three", "four")
println(numbers.associateWith { it.length })
// {one=3, two=3, three=5, four=4}
val fruits = listOf("apple", "banana", "cherry")
val lengthMap = mutableMapOf<String, Int>()
fruits.associateWithTo(lengthMap) { it.length }
println(lengthMap) // {apple=5, banana=6, cherry=6}要構建map,其集合元素作為值,有associateBy()函數。它接收一個函數,該函數根據元素的值返回鍵。如果兩個元素的鍵相等,只有最後一個會保留在map中。
associateBy()也可以與值轉換函數一起調用。
val numbers = listOf("one", "two", "three", "four")
println(numbers.associateBy { it.first().uppercaseChar() }
// {O=one, T=three, F=four}
println(numbers.associateBy({ it.first() }, { it.length }))
// {O=one, T=three, F=four}
println(numbers.associateBy(keySelector = { it.first().uppercaseChar() }, valueTransform = { it.length }))
// {O=3, T=5, F=4}
另一種方法是使用associate()構建map,其中鍵和值都從集合元素中生成。它接收一個lambda函數,該函數返回一個Pair:對應的map條目的鍵和值。
需要注意的是,associate()會產生短暫存在的Pair對象,這可能會影響性能。因此,當性能不是關鍵或比其他選項更可取時,應使用associate()。
一個示例是當鍵和值是一起從元素生成時。
val names = listOf("Alice Adams", "Brian Brown", "Clara Campbell")
println(names.associate { name -> parseFullName(name).let { it.lastName to it.firstName } })
// {Adams=Alice, Brown=Brian, Campbell=Clara}在這裡,我們首先對元素調用轉換函數,然後從該函數的結果屬性構建一個對。
展平 (Flatten)
- flatten
- flatMap
如果你操作嵌套集合,你可能會發現標準庫提供的平展訪問嵌套集合元素的函數很有用。
第一個函數是flatten()。你可以在集合的集合上調用它,例如,一個List的Set。該函數返回一個包含所有嵌套集合元素的單個列表。
val numberSets = listOf(setOf(1, 2, 3), setOf(4, 5, 6), setOf(1, 2))
println(numberSets)
// [[1, 2, 3], [4, 5, 6], [1, 2]]
println(numberSets.flatten())
// [1, 2, 3, 4, 5, 6, 1, 2]另一個函數flatMap()提供了一種靈活的方式來處理嵌套集合。它接收一個函數,該函數將集合元素映射到另一個集合。結果,flatMap()返回其對所有元素的返回值的單個列表。因此,flatMap()的行為類似於隨後調用map()(以集合作為映射結果)和flatten()。
// 就是先map 再flatten
val list = listOf(1, 2, 3)
val result = list.flatMap { listOf(it, it * 2) }
// [1, 2, 2, 4, 3, 6]data class Person(var name:String,var age:Int)
fun main() {
val numberSets = listOf(
listOf(Person("A",12), Person("B",13)),
listOf(Person("C",11), Person("D",14), Person("B",13))
)
println(numberSets)
/*
[
[Person(name=A, age=12), Person(name=B, age=13)],
[Person(name=C, age=11), Person(name=D, age=14), Person(name=B, age=13)]
]
*/
println(numberSets.flatMap{it})
// [Person(name=A, age=12), Person(name=B, age=13), Person(name=C, age=11), Person(name=D, age=14), Person(name=B, age=13)]
}字符串表示 (String representation)
- joinToString
- joinTo
如果你需要以可讀格式檢索集合內容,請使用將集合轉換為字符串的函數:joinToString()和joinTo()。
joinToString()根據提供的參數構建單個字符串。joinTo()做同樣的事,但將結果附加到給定的Appendable對象。
當使用默認參數調用時,這些函數返回的結果類似於對集合調用toString():元素的字符串表示形式以逗號和空格分隔的字符串。
val numbers = listOf("one", "two", "three", "four")
println(numbers) // [one, two, three, four]
println(numbers.joinToString()) // one, two, three, four
val listString = StringBuffer("The list of numbers: ")
numbers.joinTo(listString)
println(listString)
// The list of numbers: one, two, three, four要構建自定義字符串表示,可以在函數參數中指定其參數:分隔符、前綴和後綴。結果字符串將以前綴開始,以後綴結束。分隔符將在每個元素之後出現,除了最後一個元素。
val numbers = listOf("one", "two", "three", "four")
println(numbers.joinToString(separator = " | ", prefix = "start: ", postfix = ": end"))
// start: one | two | three | four: end
對於較大的集合,你可能希望指定限制——將包含在結果中的元素數量。如果集合大小超過限制,所有其他元素將被替換為單個截斷參數值。
val numbers = (1..100).toList()
println(numbers.joinToString(limit = 10, truncated = "<...>"))
// 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, <...>最後,要自定義元素本身的表示,請提供 transform 函數。
val numbers = listOf("one", "two", "three", "four")
println(numbers.joinToString { "Element: ${it.uppercase()}"})
// Element: ONE, Element: TWO, Element: THREE, Element: FOUR【過濾集合】
過濾是集合處理中最常見的任務之一。在Kotlin中,過濾條件由謂詞定義——這些lambda函數接收一個集合元素並返回一個布爾值:true表示給定元素符合謂詞,false表示相反。
標準庫包含一組擴展函數,允許你在一次調用中過濾集合。這些函數不會更改原始集合,因此它們可用於可變和只讀集合。要操作過濾結果,應將其賦值給變量或在過濾後鏈接函數。
根據條件過濾
- filter
- filterIndexed
- fiterNot
- filterIsInstance
- filterNotNull
基本的過濾函數是filter()。當用謂詞調用時,filter()返回符合條件的集合元素。對於List和Set,返回結果是List,對於Map,返回結果也是Map。
val numbers = listOf("one", "two", "three", "four")
val longerThan3 = numbers.filter { it.length > 3 }
println(longerThan3) // [three, four]
val numbersMap = mapOf("key1" to 1, "key2" to 2, "key3" to 3, "key11" to 11)
val filteredMap = numbersMap.filter { (key, value) -> key.endsWith("1") && value > 10 }
println(filteredMap) // {key11=11}
filter()中的謂詞只能檢查元素的值。如果你想在過濾中使用元素的位置,請使用filterIndexed()。它接收一個帶有兩個參數的謂詞:索引和元素的值。
要根據否定條件過濾集合,使用filterNot()。它返回一個對謂詞結果為false的元素列表。
val numbers = listOf("one", "two", "three", "four")
val filteredIdx = numbers.filterIndexed { index, s -> (index != 0) && (s.length < 5) }
val filteredNot = numbers.filterNot { it.length <= 3 }
println(filteredIdx) // [two, four]
println(filteredNot) // [three, four]
還有一些函數可以通過過濾特定類型的元素來縮小元素類型:
filterIsInstance()返回給定類型的集合元素。對List<Any>調用filterIsInstance<T>()返回List<T>,從而允許你對其項目調用T類型的函數。
val numbers = listOf(null, 1, "two", 3.0, "four")
println("All String elements in upper case:")
numbers.filterIsInstance<String>().forEach {
println(it.uppercase())
}
/*
All String elements in upper case:
TWO
FOUR
*/filterNotNull()返回所有非空元素。對List<T?>調用filterNotNull()返回List<T: Any>,從而允許你將元素作為非空對象處理。
val numbers = listOf(null, "one", "two", null)
numbers.filterNotNull().forEach {
println(it.length) // length is unavailable for nullable Strings
}
// 3
// 3分區 (Partition)
另一個過濾函數——partition()——根據條件過濾集合,並將不符合條件的元素保存在單獨的列表中。因此,你會得到一對列表作為返回值:第一個列表包含符合條件的元素,第二個列表包含原始集合中的其他所有元素。
val numbers = listOf("one", "two", "three", "four")
val (match, rest) = numbers.partition { it.length > 3 }
println(match)
// [three, four]
println(rest)
// [one, two]
測試謂詞 (Test predicates)
最後,有一些函數只是將測試集合元素:
any():如果至少有一個元素符合判斷式,則返回true。none():如果沒有元素符合判斷式,則返回true。all():如果所有元素都符合判斷式,則返回true。注意,對空集合而言,all()返回true。
val numbers = listOf("one", "two", "three", "four")
println(numbers.any { it.endsWith("e") }) // true
println(numbers.none { it.endsWith("a") }) // true
println(numbers.all { it.endsWith("e") }) // false
println(emptyList<Int>().all { it > 5 }) // true
any()和none()也可以不帶判斷式:在這種情況下,它們只是檢查集合是否為空。any()返回true如果有元素,否則返回false;none()做相反的事。
val numbers = listOf("one", "two", "three", "four")
val empty = emptyList<String>()
println(numbers.any()) // true
println(empty.any()) // false
println(numbers.none()) // false
println(empty.none()) // true【加號和減號操作符】
在Kotlin中,加號(+)和減號(-)操作符是為集合定義的。它們將集合作為第一個操作數;第二個操作數可以是元素或另一個集合。返回值是一個新的只讀集合:
plus的結果包含原始集合中的元素以及第二個操作數中的元素。minus的結果包含原始集合中的元素,但去除了第二個操作數中的元素。如果第二個操作數是元素,minus會移除它的首次出現;如果是集合,則移除其所有元素的出現。
val numbers = listOf("one", "two", "three", "four")
val plusList = numbers + "five"
val minusList = numbers - listOf("three", "four")
println(plusList) // [one, two, three, four, five]
println(minusList) // [one, two]
【分組】
Kotlin標準庫提供了一組用於對集合元素進行分組的擴展函數。基本的分組函數groupBy()接受一個lambda函數並返回一個Map。在這個Map中,每個鍵是lambda結果,對應的值是返回該結果的元素列表。此函數可以用來,例如,按字符串的首字母對字符串列表進行分組。
你還可以使用第二個lambda參數來調用groupBy(),這是一個值轉換函數。在使用兩個lambda的groupBy()的結果Map中,keySelector函數生成的鍵被映射到值轉換函數的結果,而不是原始元素。
以下示例展示了如何使用groupBy()函數按字符串的首字母對字符串進行分組,使用for運算符迭代結果Map中的組,然後使用keySelector函數將值轉換為大寫:
val numbers = listOf("one", "two", "three", "four", "five")
// 使用 groupBy() 按首字母對字符串進行分組
val groupedByFirstLetter = numbers.groupBy { it.first().uppercase() }
println(groupedByFirstLetter)
// {O=[one], T=[two, three], F=[four, five]}
// 迭代每個組並打印鍵及其相關的值
for ((key, value) in groupedByFirstLetter) {
println("Key: $key, Values: $value")
}
// Key: O, Values: [one]
// Key: T, Values: [two, three]
// Key: F, Values: [four, five]
// 按首字母對字符串進行分組並將值轉換為大寫
val groupedAndTransformed = numbers.groupBy(keySelector = { it.first() }, valueTransform = { it.uppercase() })
println(groupedAndTransformed)
// {o=[ONE], t=[TWO, THREE], f=[FOUR, FIVE]}
如果你想對元素進行分組,然後一次性對所有組應用操作,請使用groupingBy()函數。它返回一個Grouping類型的實例。Grouping實例允許你以懶惰的方式對所有組應用操作:這些組實際上是在操作執行之前構建的。
具體而言,Grouping支持以下操作:
eachCount()計算每個組中的元素數量。fold()和reduce()對每個組作為單獨的集合執行fold和reduce操作,並返回結果。aggregate()將給定操作依次應用於每個組中的所有元素,並返回結果。這是對Grouping執行任何操作的通用方法。當fold或reduce不夠時,使用它來實現自定義操作。
你可以在結果Map上使用for運算符來迭代由groupingBy()函數創建的組。這允許你訪問每個鍵和與該鍵相關的元素計數。
以下示例展示了如何使用groupingBy()函數按字符串的首字母對字符串進行分組,計算每個組中的元素數量,然後迭代每個組以打印鍵和元素的數量:
val numbers = listOf("one", "two", "three", "four", "five")
// 使用 groupingBy() 按首字母對字符串進行分組並計算每個組中的元素數量
val grouped = numbers.groupingBy { it.first() }.eachCount()
// 迭代每個組並打印鍵及其相關的值
for ((key, count) in grouped) {
println("Key: $key, Count: $count")
// Key: o, Count: 1
// Key: t, Count: 2
// Key: f, Count: 2
}
這樣,你可以根據特定的條件對集合元素進行分組,並對分組結果進行進一步的操作。
// 使用then串接多個排序
private fun sortLiveShows(shows: List<ShowGeneric>): List<ShowGeneric> {
// 銷售版位為直播順序非99的檔次
val (weightedShows, unweightedShows) = shows.partition { it.weight != 99 }
// 直播順序99的檔次再分成開播時間在十分鐘之內跟之外的兩組
val tenMinutesBefore = Date.from(Instant.now().minus(10, ChronoUnit.MINUTES))
val (newUnweightedShows, oldUnweightedShows) = unweightedShows.partition {
it.startAt?.after(tenMinutesBefore) == true
}
// 排序
// 銷售版位檔次排序:按照直播順序排序
val sortedWeightedShows = weightedShows.sortedBy { it.weight }
// 開播十分鐘之內檔次排序:先按照開播時間再按照首次送審時間
val sortedNewUnweightedShows = newUnweightedShows.sortedWith(
compareByDescending<ShowGeneric> { it.startAt }
.then(compareBy { it.getAuditStartAt() })
)
/* 也可以用theyBy
val sortedNewUnweightedShows = newUnweightedShows.sortedWith(
compareByDescending<ShowGeneric> { it.startAt }
.thenBy { it.getAuditStartAt() }
)
*/
// 開播十分中之外檔次排序:random
val sortedOldUnWeightedShows = oldUnweightedShows.shuffled()
// 銷售版位 + 開播十分鐘之內 + 開播十分中之外
return sortedWeightedShows + sortedNewUnweightedShows + sortedOldUnWeightedShows
}【檢索集合部分】
Kotlin標準庫包含一組擴展函數,用於檢索集合的部分內容。這些函數提供多種方式來選擇結果集合的元素:明確列出它們的位置、指定結果大小等。
切片 (Slice)
slice() 返回具有給定索引的集合元素列表。索引可以作為範圍或整數值的集合傳遞。
val numbers = listOf("one", "two", "three", "four", "five", "six")
println(numbers.slice(1..3)) // [two, three, four]
println(numbers.slice(0..4 step 2)) // [one, three, five]
println(numbers.slice(setOf(3, 5, 0))) // [four, six, one]
取出和丟棄 (Take and drop)
要從第一個元素開始取出指定數量的元素,使用take()函數。要取出最後的元素,使用takeLast()。當傳遞的數量大於集合大小時,這兩個函數都返回整個集合。
要取出除了給定數量的第一個或最後一個元素之外的所有元素,分別調用drop()和dropLast()函數。
val numbers = listOf("one", "two", "three", "four", "five", "six")
println(numbers.take(3)) // [one, two, three]
println(numbers.takeLast(3)) // [four, five, six]
println(numbers.drop(1)) // [two, three, four, five, six]
println(numbers.dropLast(5)) // [one]
你還可以使用謂詞來定義取出或丟棄的元素數量。有四個與上面描述的函數類似的函數:
takeWhile()是帶有謂詞(predicates)的take():它取出直到不匹配謂詞的第一個元素為止(不包括該元素)的元素。如果第一個集合元素不匹配謂詞,結果為空。takeLastWhile()類似於takeLast():它從集合末尾取出匹配謂詞的元素範圍。範圍的第一個元素是不匹配謂詞的最後一個元素的下一個元素。如果最後的集合元素不匹配謂詞,結果為空。dropWhile()與帶有相同謂詞的takeWhile()相反:它返回從不匹配謂詞的第一個元素到結尾的元素。dropLastWhile()與帶有相同謂詞的takeLastWhile()相反:它返回從開始到不匹配謂詞的最後一個元素的元素。
val numbers = listOf("one", "two", "three", "four", "five", "six")
println(numbers.takeWhile { !it.startsWith('f') }) // [one, two, three, four]
println(numbers.takeLastWhile { it != "three" }) // [four, five, six]
println(numbers.dropWhile { it.length == 3 }) // [four, five, six]
println(numbers.dropLastWhile { it.contains('i') }) // [one, two, three]
分塊 (Chunked)
要將集合拆分為給定大小的部分,使用chunked()函數。chunked()接受一個參數——塊的大小,並返回一個包含給定大小的列表的列表。第一個塊從第一個元素開始並包含大小元素,第二個塊包含接下來的大小元素,依此類推。最後一個塊可能大小較小。
val numbers = (0..13).toList()
println(numbers.chunked(3)) // [[0, 1, 2], [3, 4, 5], [6, 7, 8], [9, 10, 11], [12, 13]]
你還可以立即對返回的塊應用轉換。為此,調用chunked()時提供轉換函數。lambda參數是集合的一個塊。當chunked()與轉換一起調用時,這些塊是短暫的列表,應該在該lambda中消費。
val numbers = (0..13).toList()
println(numbers.chunked(3) { it.sum() }) // [3, 12, 21, 30, 25]
窗口 (Windowed)
你可以檢索集合元素的所有可能的給定大小的範圍。用於獲取它們的函數稱為windowed():它返回元素範圍的列表,就像你通過滑動窗口查看集合一樣。與chunked()不同,windowed()返回從每個集合元素開始的元素範圍。所有窗口都作為單個列表的元素返回。
val numbers = listOf("one", "two", "three", "four", "five")
println(numbers.windowed(3)) // [[one, two, three], [two, three, four], [three, four, five]]
windowed()提供了可選參數,使其更具靈活性:
step定義了兩個相鄰窗口的第一個元素之間的距離。默認值為1,因此結果包含從所有元素開始的窗口。如果將步長增加到2,你將只會獲得從奇數元素開始的窗口:第一、第三,依此類推。partialWindows包含從集合末尾的元素開始的較小大小的窗口。例如,如果你請求三個元素的窗口,你無法為最後兩個元素構建它們。在這種情況下,啟用partialWindows將包含大小為2和1的兩個列表。
最後,你可以立即對返回的範圍應用轉換。為此,調用windowed()時提供轉換函數。
val numbers = (1..10).toList()
println(numbers.windowed(3, step = 2, partialWindows = true)) // [[1, 2, 3], [3, 4, 5], [5, 6, 7], [7, 8, 9], [9, 10]]
println(numbers.windowed(3) { it.sum() }) // [6, 9, 12, 15, 18, 21, 24, 27]
要構建兩元素的窗口,有一個單獨的函數——zipWithNext()。它創建接收集合的相鄰元素對。請注意,zipWithNext()不會將集合分成對;它為每個元素(除了最後一個)創建一個Pair,因此其結果對於[1, 2, 3, 4]是[[1, 2], [2, 3], [3, 4]],而不是[[1, 2], [3, 4]]。zipWithNext()也可以與轉換函數一起調用;該轉換函數應接受接收集合的兩個元素作為參數。
val numbers = listOf("one", "two", "three", "four", "five")
println(numbers.zipWithNext()) // [(one, two), (two, three), (three, four), (four, five)]
println(numbers.zipWithNext { s1, s2 -> s1.length > s2.length }) // [false, false, false, true]
這些擴展函數使你能夠靈活地檢索和處理集合的部分內容。
【檢索單個元素】
Kotlin集合提供了一組函數,用於從集合中檢索單個元素。本頁描述的函數適用於列表和集合。
- elementAt, elementAtOrNull, elementAtOrElse
- get, getOrNull, getOrElse
- fitst, firstOrNull, find
- last, lastOrNull, findLast
firstNotNullOfOrNull(map 使用)-
random, randomOrNull
按位置檢索
要檢索特定位置的元素,可以使用elementAt()函數。調用該函數並傳入一個整數作為參數,你將獲得給定位置的集合元素。第一個元素的位置是0,最後一個元素的位置是size - 1。
elementAt()對於不提供索引訪問的集合或靜態上未知提供索引訪問的集合很有用。在列表的情況下,更符合習慣的是使用索引訪問操作符(get()或[])。
val numbers = linkedSetOf("one", "two", "three", "four", "five")
println(numbers.elementAt(3)) // four
val numbersSortedSet = sortedSetOf("one", "two", "three", "four")
println(numbersSortedSet.elementAt(0)) // one (元素按升序存儲)
還有一些用於檢索集合的第一個和最後一個元素的有用別名:first()和last()。
val numbers = listOf("one", "two", "three", "four", "five")
println(numbers.first()) // one
println(numbers.last()) // five
為了避免在檢索不存在位置的元素時拋出異常,可以使用elementAt()的安全變體:
elementAtOrNull()當指定位置超出集合範圍時返回null。elementAtOrElse()另外接受一個lambda函數,該函數將一個整數參數映射為集合元素類型的實例。當調用超出範圍的位置時,elementAtOrElse()返回該lambda對給定值的結果。
val numbers = listOf("one", "two", "three", "four", "five")
println(numbers.elementAtOrNull(5)) // null
println(numbers.elementAtOrElse(5) { index -> "The value for index $index is undefined" })
// The value for index 5 is undefined
- elementAtOrNull = getOrNull
- elementAtOrElse = getOrElse
val list = listOf(1,2,3,4)
println(list.getOrElse(1,{9})) // 2
println(list.getOrElse(5,{9})) // 9
println(list.getOrNull(1)) // 2
println(list.getOrNull(5)) // null按條件檢索
函數first()和last()也讓你可以搜索集合中符合特定條件的元素。當你調用帶有測試集合元素的謂詞的first()時,你將獲得符合條件為true的第一個元素。反過來,last()返回匹配條件的最後一個元素。
val numbers = listOf("one", "two", "three", "four", "five", "six")
println(numbers.first { it.length > 3 }) // three
println(numbers.last { it.startsWith("f") }) // five
如果沒有元素匹配,這兩個函數會拋出異常。為了避免這種情況,使用firstOrNull()和lastOrNull():如果沒有找到匹配的元素,它們返回null。
val numbers = listOf("one", "two", "three", "four", "five", "six")
println(numbers.firstOrNull { it.length > 6 }) // null
也可以使用別名:
find()代替firstOrNull()findLast()代替lastOrNull()
val numbers = listOf(1, 2, 3, 4)
println(numbers.find { it % 2 == 0 }) // 2
println(numbers.findLast { it % 2 == 0 }) // 4
帶選擇器的檢索
如果你需要在檢索元素之前對集合進行映射,可以使用firstNotNullOf()函數。它結合了兩個操作:
- 使用map
- 返回結果中的第一個非空值
如果結果集合中沒有非空元素,firstNotNullOf()會拋出NoSuchElementException。使用對應的firstNotNullOfOrNull()來在這種情況下返回null。
val list = listOf<Any>(0, "true", false)
// 將每個元素轉換為字符串並返回具有所需長度的第一個
val longEnough = list.firstNotNullOf { item -> item.toString().takeIf { it.length >= 4 } }
println(longEnough) // true
隨機元素
如果你需要檢索集合的任意元素,調用random()函數。可以不帶參數調用它,或者將Random對象作為隨機性的來源。
val numbers = listOf(1, 2, 3, 4)
println(numbers.random())
在空集合上,random()會拋出異常。要接收null,請使用randomOrNull()。
檢查元素存在
- contains
- containsAll
- isEmpty
- isNotEmpty
要檢查集合中是否存在某個元素,使用contains()函數。如果有一個等於函數參數的集合元素,它返回true。可以使用in關鍵字以操作符形式調用contains()。
要一次檢查多個實例的存在,調用containsAll()並將這些實例的集合作為參數。
val numbers = listOf("one", "two", "three", "four", "five", "six")
println(numbers.contains("four")) // true
println("zero" in numbers) // false
println(numbers.containsAll(listOf("four", "two"))) // true
println(numbers.containsAll(listOf("one", "zero"))) // false
此外,可以通過調用isEmpty()或isNotEmpty()檢查集合中是否包含任何元素。
val numbers = listOf("one", "two", "three", "four", "five", "six")
println(numbers.isEmpty()) // false
println(numbers.isNotEmpty()) // true
val empty = emptyList<String>()
println(empty.isEmpty()) // true
println(empty.isNotEmpty()) // false
這些擴展函數使你能夠靈活地檢索和處理集合中的單個元素。
【排序】
元素的順序是某些集合類型的重要方面。例如,兩個具有相同元素的列表,如果它們的元素順序不同,它們就不相等。
在Kotlin中,可以通過幾種方式定義對象的順序。
首先是自然順序。它是為實現Comparable介面的類型定義的。當沒有指定其他順序時,會使用自然順序來對其進行排序。
大多數內建類型是可比較的:
- 數字類型使用傳統的數值順序:1大於0;-3.4f大於-5f,依此類推。
- 字符和字符串使用詞典順序:b大於a;world大於hello。
要為自定義類型定義自然順序,請使該類型成為Comparable的實現者。這需要實現compareTo()函數。compareTo()必須接受同類型的另一個對象作為參數,並返回一個整數值,表示哪個對象更大:
- 正值表示接收對象更大。
- 負值表示它小於參數。
- 零表示兩個對象相等。
以下是一個排序版本的類,該版本由主要部分和次要部分組成。
class Version(val major: Int, val minor: Int): Comparable<Version> {
override fun compareTo(other: Version): Int = when {
this.major != other.major -> this.major compareTo other.major // compareTo() 以中綴形式
this.minor != other.minor -> this.minor compareTo other.minor
else -> 0
}
}
fun main() {
println(Version(1, 2)) // Version@12edcd21
println(Version(1, 2) > Version(1, 3)) // false
println(Version(2, 0) > Version(1, 5)) // true
}
自定義順序允許你以所需的方式對任何類型的實例進行排序。特別是,你可以為不可比較的對象定義順序,或為可比較類型定義自然順序以外的順序。要為某種類型定義自定義順序,請為其創建Comparator。Comparator包含compare()函數:它接受一個類的兩個實例,並返回它們之間比較的整數結果。結果的解釋方式與上述compareTo()結果相同。
val lengthComparator = Comparator { str1: String, str2: String -> str1.length - str2.length }
println(listOf("aaa", "bb", "c").sortedWith(lengthComparator)) // [c, bb, aaa]
擁有lengthComparator,你可以按字符串長度排列,而不是按默認的詞典順序。
定義Comparator的一種更簡便的方法是使用標準庫中的compareBy()函數。compareBy()接受一個lambda函數,該函數從實例生成一個Comparable值,並將自定義順序定義為生成值的自然順序。
使用compareBy(),上面示例中的長度比較器如下所示:
println(listOf("aaa", "bb", "c").sortedWith(compareBy { it.length })) // [c, bb, aaa]
Kotlin集合包提供了用於按自然順序、自定義順序甚至隨機順序排序集合的函數。在本頁中,我們將描述適用於只讀集合的排序函數。這些函數返回其結果作為包含原始集合元素的新集合,並按請求的順序排列。要了解有關原地排序可變集合的函數,請參見列表特定操作。
自然順序
基本函數sorted()和sortedDescending()根據其自然順序返回升序和降序排序的集合元素。這些函數適用於Comparable元素的集合。
val numbers = listOf("one", "two", "three", "four")
println("Sorted ascending: ${numbers.sorted()}") // Sorted ascending: [four, one, three, two]
println("Sorted descending: ${numbers.sortedDescending()}") // Sorted descending: [two, three, one, four]
自定義順序
對於自定義順序排序或不可比較對象排序,有sortedBy()和sortedByDescending()函數。它們接受一個選擇器函數,該函數將集合元素映射為Comparable值,並按這些值的自然順序排序集合。
val numbers = listOf("one", "two", "three", "four")
val sortedNumbers = numbers.sortedBy { it.length }
println("Sorted by length ascending: $sortedNumbers") // Sorted by length ascending: [one, two, four, three]
val sortedByLast = numbers.sortedByDescending { it.last() }
println("Sorted by the last letter descending: $sortedByLast") // Sorted by the last letter descending: [four, two, one, three]
要為集合排序定義自定義順序,可以提供自己的Comparator。為此,調用sortedWith()函數並傳入你的Comparator。使用此函數,按字符串長度排序看起來如下所示:
val numbers = listOf("one", "two", "three", "four")
println("Sorted by length ascending: ${numbers.sortedWith(compareBy { it.length })}") // Sorted by length ascending: [one, two, four, three]
反向順序
可以使用reversed()函數檢索反向順序的集合。
val numbers = listOf("one", "two", "three", "four")
println(numbers.reversed()) // [four, three, two, one]
reversed()返回包含元素副本的新集合。因此,如果你稍後更改原始集合,這不會影響以前獲得的reversed()結果。
另一個反轉函數 - asReversed()
返回相同集合實例的反轉視圖,因此如果原始列表不會更改,它可能比reversed()更輕量且更可取。
val numbers = listOf("one", "two", "three", "four")
val reversedNumbers = numbers.asReversed()
println(numbers) // [one, two, three, four]
println(numbers.reversed()) // [four, three, two, one]
println(numbers) // [one, two, three, four]
println(reversedNumbers) // [four, three, two, one]如果原始列表是可變的,它的所有更改都會反映在其反轉視圖中,反之亦然。
val numbers = mutableListOf("one", "two", "three", "four")
val reversedNumbers = numbers.asReversed()
println(reversedNumbers) // [four, three, two, one]
numbers.add("five")
println(reversedNumbers) // [five, four, three, two, one]
然而,如果列表的可變性未知或源根本不是列表,reversed()更可取,因為它的結果是未來不會更改的副本。
隨機順序
最後,有一個返回包含隨機順序的集合元素的新列表的函數——shuffled()。你可以不帶參數調用它,或將Random對象作為參數。
val numbers = listOf("one", "two", "three", "four")
println(numbers.shuffled())
這些函數使你能夠靈活地排序集合,並根據需要檢索其元素。
【聚合操作】
Kotlin集合包含一些常用的聚合操作函數——這些操作根據集合的內容返回單個值。大多數這些操作都是眾所周知的,並且在其他語言中也以相同方式工作:
minOrNull()和maxOrNull()分別返回最小和最大的元素。對於空集合,它們返回null。average()返回數字集合中元素的平均值。sum()返回數字集合中元素的總和。count()返回集合中的元素數量。
fun main() {
val numbers = listOf(6, 42, 10, 4)
println("Count: ${numbers.count()}") // Count: 4
println("Max: ${numbers.maxOrNull()}") // Max: 42
println("Min: ${numbers.minOrNull()}") // Min: 4
println("Average: ${numbers.average()}") // Average: 15.5
println("Sum: ${numbers.sum()}") // Sum: 62
}
data class StudentGrade(val name: String, val subject: String, val grade: Int)
fun main() {
val grades = listOf(
StudentGrade("Alice", "Math", 85),
StudentGrade("Alice", "Science", 90),
StudentGrade("Bob", "Math", 75),
StudentGrade("Bob", "Science", 80),
StudentGrade("Charlie", "Math", 95),
StudentGrade("Charlie", "Science", 100)
)
// 將成績根據學生姓名進行分組
val gradesByStudent = grades.groupBy { it.name }
// 對每個學生計算成績的統計數據
for ((student, grades) in gradesByStudent) {
val count = grades.count()
val max = grades.maxByOrNull { it.grade }?.grade
val min = grades.minByOrNull { it.grade }?.grade
val average = grades.map { it.grade }.average()
val sum = grades.sumOf { it.grade }
println("Student: $student")
println(" Count: $count")
println(" Max: $max")
println(" Min: $min")
println(" Average: $average")
println(" Sum: $sum")
println()
}
/*
Student: Alice
Count: 2
Max: 90
Min: 85
Average: 87.5
Sum: 175
Student: Bob
Count: 2
Max: 80
Min: 75
Average: 77.5
Sum: 155
Student: Charlie
Count: 2
Max: 100
Min: 95
Average: 97.5
Sum: 195
*/
}
還有一些函數可以通過特定的選擇器函數或自定義的Comparator來檢索最小和最大的元素:
maxByOrNull()和minByOrNull()接受一個選擇器函數,並返回該函數返回值最大的或最小的元素。maxWithOrNull()和minWithOrNull()接受一個Comparator對象,並根據該Comparator返回最大或最小的元素。maxOfOrNull()和minOfOrNull()接受一個選擇器函數,並返回該選擇器函數的最大或最小返回值。maxOfWithOrNull()和minOfWithOrNull()接受一個Comparator對象,並根據該Comparator返回選擇器函數的最大或最小返回值。
這些函數在空集合上返回null。還有一些替代函數——maxOf、minOf、maxOfWith和minOfWith——它們與對應的函數作用相同,但在空集合上會拋出NoSuchElementException。
val numbers = listOf(5, 42, 10, 4)
val min3Remainder = numbers.minByOrNull { it % 3 }
println(min3Remainder) // 4
val strings = listOf("one", "two", "three", "four")
val longestString = strings.maxWithOrNull(compareBy { it.length })
println(longestString) // three
多重屬性排序
compareBy 是一個 Kotlin 標準庫中的函數,用於創建比較器 (Comparator) 以便於對集合中的元素進行比較和排序。它可以根據一個或多個屬性來比較元素,並且可以輕鬆地用於各種排序操作。
data class Person(val name: String, val age: Int)
val people = listOf(
Person("Alice", 30),
Person("Bob", 25),
Person("Charlie", 30)
)
val sortedPeople = people.sortedWith(compareBy({ it.age }, { it.name }))
println(sortedPeople)
// [Person(name=Bob, age=25), Person(name=Alice, age=30), Person(name=Charlie, age=30)]
/*
改變升降冪排序可以這樣寫
age 升冪, name 降冪
*/
val sortedPeople = people.sortedWith(
compareBy<Person> { it.age }
.thenByDescending { it.name }
)
// age 降冪, name 升冪
val sortedPeople = people.sortedWith(
compareByDescending<Person> { it.age }
.thenBy { it.name }
)除了常規的sum(),還有一個高級求和函數sumOf(),它接受一個選擇器函數並返回該函數應用於所有集合元素的總和。選擇器可以返回不同的數字類型:Int、Long、Double、UInt和ULong(在JVM上還包括BigInteger和BigDecimal)。
val numbers = listOf(5, 42, 10, 4)
println(numbers.sumOf { it * 2 }) // 122
println(numbers.sumOf { it.toDouble() / 2 }) // 30.5
Fold和Reduce
對於更具體的情況,有reduce()和fold()函數,它們將提供的操作依次應用於集合元素並返回累積結果。該操作接受兩個參數:先前的累積值和集合元素。
這兩個函數的區別在於fold()接受一個初始值,並在第一步中將其作為累積值,而reduce()的第一步使用第一個和第二個元素作為操作參數。
val numbers = listOf(5, 2, 10, 4)
val simpleSum = numbers.reduce { sum, element -> sum + element } // 5 + 2 +10 + 4
println(simpleSum) // 21
// 使用map做一樣的事
var simpleSum2 = 0
simpleSum2 = numbers.map { simpleSum2 += it}
.let {
simpleSum2
}
println(simpleSum2) // 21
val sumDoubled = numbers.fold(0) { sum, element -> sum + element * 2 } // 0 + 5*2 + 2*2 + 10*2 + 4*2
println(sumDoubled) // 42
// 錯誤:第一個元素未在結果中加倍
// val sumDoubledReduce = numbers.reduce { sum, element -> sum + element * 2 }
// println(sumDoubledReduce)
上述示例顯示了區別:fold()用於計算加倍元素的總和。如果將相同的函數傳遞給reduce(),它將返回另一個結果,因為它在第一步中使用列表的第一個和第二個元素作為參數,因此第一個元素不會被加倍。
要對元素按相反順序應用函數,請使用reduceRight()和foldRight()函數。它們的工作方式類似於fold()和reduce(),但從最後一個元素開始,然後繼續到前一個。請注意,當從右到左進行折疊或歸約時,操作參數會改變順序:首先是元素,然後是累積值。
val numbers = listOf(5, 2, 10, 4)
val sumDoubledRight = numbers.foldRight(0) { element, sum -> sum + element * 2 } // 0 + 4*2 + 10*2 + 2*2 + 5*2
println(sumDoubledRight) // 42
你還可以應用將元素索引作為參數的操作。為此,使用reduceIndexed()和foldIndexed()函數,將元素索引作為操作的第一個參數。
最後,有一些函數將此類操作應用於集合元素,從右到左——reduceRightIndexed()和foldRightIndexed()。
val numbers = listOf(5, 2, 10, 4)
val sumEven = numbers.foldIndexed(0) { idx, sum, element -> if (idx % 2 == 0) sum + element else sum }
println(sumEven) // 15
val sumEvenRight = numbers.foldRightIndexed(0) { idx, element, sum -> if (idx % 2 == 0) sum + element else sum }
println(sumEvenRight) // 14
所有的歸約操作在空集合上會拋出異常。要接收null,請使用它們的*OrNull()對應函數:
reduceOrNull()reduceRightOrNull()reduceIndexedOrNull()reduceRightIndexedOrNull()
如果你希望保存中間累加值,請使用runningFold()(或其同義詞scan())和runningReduce()函數。
val numbers = listOf(0, 1, 2, 3, 4, 5)
val runningReduceSum = numbers.runningReduce { sum, item -> sum + item }
val runningFoldSum = numbers.runningFold(10) { sum, item -> sum + item }
println(runningReduceSum) // [0, 1, 3, 6, 10, 15]
println(runningFoldSum) // [10, 10, 11, 13, 16, 20, 25]
如果你需要在操作參數中使用索引,請使用runningFoldIndexed()或runningReduceIndexed()。
【Collections寫入操作】
可變集合支持更改集合內容的操作,例如添加或移除元素。本頁將描述所有可變集合實現可用的寫操作。關於列表和映射的特定操作,請分別參見列表特定操作和映射特定操作。
添加元素
要向列表或集合添加單個元素,使用add()函數。指定的對象會附加到集合的末尾。
val numbers = mutableListOf(1, 2, 3, 4)
numbers.add(5)
println(numbers) // [1, 2, 3, 4, 5]
addAll()將參數對象的每個元素添加到列表或集合。參數可以是Iterable、Sequence或Array。接收者和參數的類型可以不同,例如,可以將集合中的所有項目添加到列表中。
當在列表上調用時,addAll()按參數中的順序添加新元素。你也可以在調用addAll()時指定元素位置作為第一個參數。參數集合的第一個元素將插入到此位置。參數集合的其他元素將跟隨它,將接收者元素移到末尾。
val numbers = mutableListOf(1, 2, 5, 6)
numbers.addAll(arrayOf(7, 8))
println(numbers) // [1, 2, 5, 6, 7, 8]
numbers.addAll(2, setOf(3, 4))
println(numbers) // [1, 2, 3, 4, 5, 6, 7, 8]
你還可以使用原地版本的加號操作符plusAssign (+=)添加元素。當應用於可變集合時,+=將第二個操作數(元素或另一個集合)附加到集合的末尾。
val numbers = mutableListOf("one", "two")
numbers += "three"
println(numbers) // [one, two, three]
numbers += listOf("four", "five")
println(numbers) // [one, two, three, four, five]
移除元素
要從可變集合中移除元素,使用remove()函數。remove()接受元素值並移除此值的第一個出現。
val numbers = mutableListOf(1, 2, 3, 4, 3)
numbers.remove(3) // 移除第一個`3`
println(numbers) // [1, 2, 4, 3]
numbers.remove(5) // 不移除任何東西
println(numbers) // [1, 2, 4, 3]
要一次移除多個元素,有以下函數:
removeAll()移除參數集合中的所有元素。或者,你可以將它與謂詞作為參數一起調用;在這種情況下,該函數會移除謂詞為true的所有元素。retainAll()是removeAll()的反向操作:它移除除參數集合之外的所有元素。當與謂詞一起使用時,它僅保留匹配謂詞的元素。clear()移除列表中的所有元素,並使其變空。
val numbers = mutableListOf(1, 2, 3, 4)
println(numbers) // [1, 2, 3, 4]
numbers.retainAll { it >= 3 }
println(numbers) // [3, 4]
numbers.clear()
println(numbers) // []
val numbersSet = mutableSetOf("one", "two", "three", "four")
numbersSet.removeAll(setOf("one", "two"))
println(numbersSet) // [three, four]
另一種從集合中移除元素的方法是使用減號操作符minusAssign (-=)——原地版本的minus。第二個參數可以是元素類型的單個實例或另一個集合。當右側是單個元素時,-=移除它的第一次出現。反之,如果它是一個集合,則會移除其元素的所有出現。例如,如果列表包含重複的元素,它們會一次性移除。第二個操作數可以包含集合中不存在的元素。這些元素不會影響操作的執行。
val numbers = mutableListOf("one", "two", "three", "three", "four")
numbers -= "three"
println(numbers) // [one, two, three, four]
numbers -= listOf("four", "five")
//numbers -= listOf("four") // 與上面相同
println(numbers) // [one, two, three]
更新元素
列表和映射還提供了用於更新元素的操作。它們在列表特定操作和映射特定操作中描述。對於集合,更新沒有意義,因為它實際上是移除一個元素並添加另一個元素。
這些操作使你能夠靈活地管理可變集合的內容,添加、移除和更新元素以滿足應用程序的需求。
【List特定操作】
列表是Kotlin中最受歡迎的內建集合類型。對列表元素的索引訪問提供了一套強大的操作。
按索引檢索元素
列表支持所有常見的元素檢索操作:elementAt()、first()、last()等。在列表中特定的是對元素的索引訪問,因此最簡單的讀取元素方式是通過索引檢索。這可以通過帶有索引作為參數的get()函數或簡寫的[index]語法來完成。
如果列表大小小於指定的索引,會拋出異常。有兩個其他函數可以幫助你避免這些異常:
getOrElse()允許你提供計算默認值的函數,以便在索引不存在時返回該值。getOrNull()返回null作為默認值。
val numbers = listOf(1, 2, 3, 4)
println(numbers.get(0)) // 1
println(numbers[0]) // 1
//numbers.get(5) // exception!
println(numbers.getOrNull(5)) // null
println(numbers.getOrElse(5) { it }) // 5
檢索列表部分
除了檢索集合部分的常見操作外,列表還提供了subList()函數,該函數返回指定元素範圍的視圖作為列表。因此,如果原始集合的元素發生變化,它也會在先前創建的子列表中變化,反之亦然。
val numbers = (0..13).toList()
println(numbers.subList(3, 6)) // [3, 4, 5]
查找元素位置
線性搜索
在任何列表中,你可以使用indexOf()和lastIndexOf()函數查找元素的位置。它們返回列表中等於給定參數的元素的第一個和最後一個位置。如果沒有這樣的元素,這兩個函數返回-1。
val numbers = listOf(1, 2, 3, 4, 2, 5)
println(numbers.indexOf(2)) // 1
println(numbers.lastIndexOf(2)) // 4
還有一對函數,它們接受謂詞並搜索匹配的元素:
indexOfFirst()返回匹配謂詞的第一個元素的索引,如果沒有這樣的元素則返回-1。indexOfLast()返回匹配謂詞的最後一個元素的索引,如果沒有這樣的元素則返回-1。
val numbers = mutableListOf(1, 2, 3, 4)
println(numbers.indexOfFirst { it > 2}) // 2
println(numbers.indexOfLast { it % 2 == 1}) // 2
有序列表中的二分搜索
還有一種在列表中搜索元素的方法——二分搜索。它比其他內建搜索函數快得多,但要求列表按某個順序升序排序:自然順序或函數參數中提供的其他順序。否則,結果是未定義的。
要在排序列表中搜索元素,調用binarySearch()函數並傳遞值作為參數。如果存在這樣的元素,該函數返回其索引;否則,它返回(-insertionPoint - 1),其中insertionPoint是應插入此元素以保持列表排序的索引。如果有多個具有給定值的元素,搜索可以返回其中任何一個的索引。
你還可以指定一個索引範圍進行搜索:在這種情況下,該函數僅在提供的兩個索引之間搜索。
val numbers = mutableListOf("one", "two", "three", "four")
numbers.sort()
println(numbers) // [four, one, three, two]
println(numbers.binarySearch("two")) // 3
println(numbers.binarySearch("z")) // -5
println(numbers.binarySearch("two", 0, 2)) // -3
使用Comparator的二分搜索
當列表元素不可比較時,你應該提供一個Comparator來使用二分搜索。列表必須根據此Comparator按升序排序。讓我們看一個例子:
val productList = listOf(
Product("WebStorm", 49.0),
Product("AppCode", 99.0),
Product("DotTrace", 129.0),
Product("ReSharper", 149.0))
println(productList.binarySearch(Product("AppCode", 99.0), compareBy<Product> { it.price }.thenBy { it.name }))
這裡有一個Product實例的列表,這些實例不可比較,還有一個定義順序的Comparator:如果p1的價格小於p2的價格,則p1在p2之前。因此,擁有按此順序升序排列的列表,我們使用binarySearch()來查找指定Product的索引。
當列表使用不同於自然順序的順序時,自定義比較器也很方便,例如,對字符串元素使用不區分大小寫的順序。
val colors = listOf("Blue", "green", "ORANGE", "Red", "yellow")
println(colors.binarySearch("RED", String.CASE_INSENSITIVE_ORDER)) // 3
使用比較函數的二分搜索
使用比較函數進行二分搜索可以讓你在不提供顯式搜索值的情況下查找元素。相反,它接受一個將元素映射為Int值的比較函數,並搜索該函數返回零的元素。列表必須按所提供函數的升序排序;換句話說,從一個列表元素到下一個列表元素,比較返回值必須遞增。
data class Product(val name: String, val price: Double)
fun priceComparison(product: Product, price: Double) = sign(product.price - price).toInt()
fun main() {
val productList = listOf(
Product("WebStorm", 49.0),
Product("AppCode", 99.0),
Product("DotTrace", 129.0),
Product("ReSharper", 149.0))
println(productList.binarySearch { priceComparison(it, 99.0) }) // 1
}
比較器和比較函數的二分搜索也可以在列表範圍內執行。
List寫入操作
除了在集合寫操作中描述的集合修改操作外,可變列表還支持特定的寫操作。這些操作使用索引訪問元素,以擴展列表的修改功能。
添加
要將元素添加到列表的特定位置,使用add()和addAll()並提供元素插入位置作為附加參數。所有位於該位置之後的元素將右移。
val numbers = mutableListOf("one", "five", "six")
numbers.add(1, "two")
numbers.addAll(2, listOf("three", "four"))
println(numbers) // [one, two, three, four, five, six]
更新
列表還提供了替換給定位置的元素的函數——set()及其操作符形式[]。set()不會改變其他元素的索引。
val numbers = mutableListOf("one", "five", "three")
numbers[1] = "two"
println(numbers) // [one, two, three]
fill()簡單地將所有集合元素替換為指定值。
val numbers = mutableListOf(1, 2, 3, 4)
numbers.fill(3)
println(numbers) // [3, 3, 3, 3]
移除
要從列表中移除特定位置的元素,使用removeAt()函數並提供位置作為參數。被移除元素之後的所有元素索引將減少一。
val numbers = mutableListOf(1, 2, 3, 4, 3)
numbers.removeAt(1)
println(numbers) // [1, 3, 4, 3]
排序
在集合排序中,我們描述了按特定順序檢索集合元素的操作。對於可變列表,標準庫提供了類似的擴展函數,這些函數執行相同的排序操作。當你將這樣的操作應用於列表實例時,它會改變該實例中元素的順序。
原地排序函數的名稱與適用於只讀列表的函數名稱相似,但沒有ed/d後
綴:
- 所有排序函數的名稱中用
sort*代替sorted*:sort()、sortDescending()、sortBy()等。 shuffle()代替shuffled()。reverse()代替reversed()。
調用asReversed()於可變列表時,返回的另一個可變列表是原列表的反轉視圖。該視圖中的變更會反映在原始列表中。以下示例顯示了可變列表的排序函數:
val numbers = mutableListOf("one", "two", "three", "four")
numbers.sort()
println("Sort into ascending: $numbers") // [four, one, three, two]
numbers.sortDescending()
println("Sort into descending: $numbers") // [two, three, one, four]
numbers.sortBy { it.length }
println("Sort into ascending by length: $numbers") // [one, two, four, three]
numbers.sortByDescending { it.last() }
println("Sort into descending by the last letter: $numbers") // [four, two, one, three]
numbers.sortWith(compareBy<String> { it.length }.thenBy { it })
println("Sort by Comparator: $numbers") // [one, two, four, three]
numbers.shuffle()
println("Shuffle: $numbers") // [three, one, two, four]
numbers.reverse()
println("Reverse: $numbers") // [four, two, one, three]
這些操作使你能夠靈活地管理和修改列表中的元素,以滿足各種需求。
【Set特定操作】
Kotlin集合包中包含了一些常見操作的擴展函數,如查找交集、合併或從另一個集合中減去集合。
合併集合
要將兩個集合合併為一個集合,使用union()函數。它可以以中綴形式使用,即a union b。注意,對於有序集合,操作數的順序很重要。在結果集合中,第一個操作數的元素排在第二個操作數的元素之前:
val numbers = setOf("one", "two", "three")
// 按順序輸出
println(numbers union setOf("four", "five"))
// [one, two, three, four, five]
println(setOf("four", "five") union numbers)
// [four, five, one, two, three]
查找交集(intersect)和差集(subtract)
要查找兩個集合之間的交集(即同時存在於兩個集合中的元素),使用intersect()函數。要查找不在另一個集合中的集合元素,使用subtract()函數。這兩個函數也可以以中綴形式調用,例如a intersect b:
val numbers = setOf("one", "two", "three")
// 相同輸出
println(numbers intersect setOf("two", "one"))
// [one, two]
println(numbers subtract setOf("three", "four"))
// [one, two]
println(numbers subtract setOf("four", "three"))
// [one, two]
查找對稱差
要查找存在於兩個集合中的任一集合但不在其交集中存在的元素(即對稱差),你可以使用union()函數。對於這種操作,計算兩個集合之間的差異並合併結果:
val numbers = setOf("one", "two", "three")
val numbers2 = setOf("three", "four")
// 合併差異
println((numbers - numbers2) union (numbers2 - numbers))
// [one, two, four]
List 的集合操作
你也可以將union()、intersect()和subtract()函數應用於列表。在這個結果中,所有的重複元素都會合併為一個,且無法進行索引訪問:
val list1 = listOf(1, 1, 2, 3, 5, 8, -1)
val list2 = listOf(1, 1, 2, 2, 3, 5)
// 兩個列表相交的結果是一個集合
println(list1 intersect list2)
// [1, 2, 3, 5]
// 相同元素合併為一個
println(list1 union list2)
// [1, 2, 3, 5, 8, -1]
data class Person(var name:String,var age:Int)
fun main() {
val list1 = listOf(Person("A",11),Person("B",12),Person("C",13))
val list2 = listOf(Person("B",14),Person("C",13))
println(list1 intersect list2)
// [Person(name=C, age=13)]
println(list1 union list2)
// [Person(name=A, age=11), Person(name=B, age=12), Person(name=C, age=13), Person(name=B, age=14)]
}這些操作使你能夠靈活地管理和操作set,以滿足不同的需求。
【Map 特定操作】
在 Map 中,鍵和值的類型是用戶定義的。基於鍵的訪問使得 Map 特定的處理功能變得可能,從通過鍵獲取值到分別過濾鍵和值。在本頁中,我們將介紹標準庫中的 Map 處理函數。
檢索鍵和值
要從 Map 中檢索值,必須提供鍵作為 get() 函數的參數。也支持簡寫的 [key] 語法。如果找不到給定的鍵,則返回 null。還有一個 getValue() 函數,其行為略有不同:如果在 Map 中找不到鍵,則會拋出異常。此外,還有兩個選項來處理鍵的缺失:
getOrElse()的工作方式與列表相同:不存在鍵的值從給定的 lambda 函數返回。getOrDefault()在找不到鍵時返回指定的默認值。
val numbersMap = mapOf("one" to 1, "two" to 2, "three" to 3)
println(numbersMap.get("one")) // 1
println(numbersMap["one"]) // 1
println(numbersMap.getOrDefault("four", 10)) // 10
println(numbersMap["five"]) // null
//numbersMap.getValue("six") // exception!
要對 Map 的所有鍵或所有值執行操作,可以分別從 keys 和 values 屬性中檢索它們。keys 是一組所有 Map 鍵,values 是所有 Map 值的集合。
val numbersMap = mapOf("one" to 1, "two" to 2, "three" to 3)
println(numbersMap.keys) // [one, two, three]
println(numbersMap.values) // [1, 2, 3]
過濾
- filterKeys
- filterValues
你可以使用 filter() 函數來過濾 Map,與其他集合一樣。當對 Map 調用 filter() 時,將一個帶有 Pair 作為參數的謂詞(predicate)傳遞給它。這使得你可以在過濾謂詞中同時使用鍵和值。
val numbersMap = mapOf("key1" to 1, "key2" to 2, "key3" to 3, "key11" to 11)
val filteredMap = numbersMap.filter { (key, value) -> key.endsWith("1") && value > 10}
println(filteredMap) // {key11=11}
還有兩種特定的過濾 Map 的方法:按鍵和按值。對於每種方法,都有一個函數:filterKeys() 和 filterValues()。這兩個函數都返回一個新的 Map,其中包含匹配特定條件的 entries。filterKeys() 的謂詞只檢查元素的鍵,filterValues() 的謂詞只檢查值。
val numbersMap = mapOf("key1" to 1, "key2" to 2, "key3" to 3, "key11" to 11)
val filteredKeysMap = numbersMap.filterKeys { it.endsWith("1") }
val filteredValuesMap = numbersMap.filterValues { it < 10 }
println(filteredKeysMap) // {key1=1, key11=11}
println(filteredValuesMap) // {key1=1, key2=2, key3=3}
加號和減號操作符
由於基於鍵訪問元素,加號 (+) 和減號 (-) 操作符在 Map 中的工作方式與其他集合不同。加號返回一個包含其兩個操作數元素的 Map:左側的 Map 和右側的 Pair 或另一個 Map。當右側操作數包含鍵存在於左側 Map 中的 entries 時,結果 Map 包含來自右側的 entries。
val numbersMap = mapOf("one" to 1, "two" to 2, "three" to 3)
println(numbersMap + Pair("four", 4)) // {one=1, two=2, three=3, four=4}
println(numbersMap + Pair("one", 10)) // {one=10, two=2, three=3}
println(numbersMap + mapOf("five" to 5, "one" to 11)) // {one=11, two=2, three=3, five=5}
減號從左側 Map 中的 entries 創建一個 Map,除了右側操作數中的鍵。所以,右側操作數可以是單個鍵或鍵的集合:列表、集合等。
val numbersMap = mapOf("one" to 1, "two" to 2, "three" to 3)
println(numbersMap - "one") // {two=2, three=3}
println(numbersMap - listOf("two", "four")) // {one=1, three=3}
有關在可變 Map 上使用加號賦值 (+=) 和減號賦值 (-=) 操作符的詳細信息,請參見下面的 Map 寫操作。
Map 寫操作
可變 Map(Mutable maps) 提供 Map 特定的寫操作。這些操作允許你使用基於鍵的訪問來更改 Map 內容。
有些規則定義了 Map 上的寫操作:
- 值可以更新。反之,鍵永遠不變:一旦添加 entry,其鍵是固定的。
- 對於每個鍵,總是有一個與之關聯的單個值。你可以添加和移除整個 entry。
以下是標準庫中可變 Map 上可用的寫操作函數的描述。
添加和更新 entry
要向可變 Map 添加新的鍵值對,使用 put()。當將新 entry 放入 LinkedHashMap(默認 Map 實現)時,它會被添加,使其在迭代 Map 時出現在最後。在排序 Map 中,新元素的位置由其鍵的順序定義。
val numbersMap = mutableMapOf("one" to 1, "two" to 2)
numbersMap.put("three", 3)
println(numbersMap) // {one=1, two=2, three=3}
要一次添加多個 entry,使用 putAll()。其參數可以是 Map 或一組 Pair:Iterable、Sequence 或 Array。
val numbersMap = mutableMapOf("one" to 1, "two" to 2, "three" to 3)
numbersMap.putAll(setOf("four" to 4, "five" to 5))
println(numbersMap) // {one=1, two=2, three=3, four=4, five=5}
put() 和 putAll() 都會覆蓋已存在鍵的值。因此,你可以使用它們來更新 Map entries 的值。
val numbersMap = mutableMapOf("one" to 1, "two" to 2)
val previousValue = numbersMap.put("one", 11)
println("value associated with 'one', before: $previousValue, after: ${numbersMap["one"]}")
println(numbersMap) // {one=11, two=2}
你也可以使用簡寫操作符形式向 Map 添加新 entry。有兩種方式:
plusAssign (+=)操作符。[]操作符的set()別名。
val numbersMap = mutableMapOf("one" to 1, "two" to 2)
numbersMap["three"] = 3 // 調用 numbersMap.put("three", 3)
numbersMap += mapOf("four" to 4, "five" to 5)
println(numbersMap) // {one=1, two=2, three=3, four=4, five=5}
當鍵存在於 Map 中時,操作符會覆蓋相應 entry 的值。
移除 entry
要從可變 Map 中移除 entry,使用 remove() 函數。調用 remove() 時,可以傳遞鍵或整個鍵值對。如果同時指定了鍵和值,則只有當值與第二個參數匹配時,該鍵的元素才會被移除。
val numbersMap = mutableMapOf("one" to 1, "two" to 2, "three" to 3)
numbersMap.remove("one")
println(numbersMap) // {two=2, three=3}
numbersMap.remove("three", 4) // 不移除任何東西
println(numbersMap) // {two=2, three=3}
你也可以根據鍵或值從可變 Map 中移除 entries。要做到這一點,調用 remove() 在 Map 的 `
keys或values中提供鍵或值。如果調用values,remove()` 只會移除第一個與給定值匹配的 entry。
val numbersMap = mutableMapOf("one" to 1, "two" to 2, "three" to 3, "threeAgain" to 3)
numbersMap.keys.remove("one")
println(numbersMap) // {two=2, three=3, threeAgain=3}
numbersMap.values.remove(3)
println(numbersMap) // {two=2, threeAgain=3}
minusAssign (-=) 操作符同樣適用於可變 Map。
val numbersMap = mutableMapOf("one" to 1, "two" to 2, "three" to 3)
numbersMap -= "two"
println(numbersMap) // {one=1, three=3}
numbersMap -= "five" // 不移除任何東西
println(numbersMap) // {one=1, three=3}【其他】List 如何轉為 Set
在 Kotlin 中,可以使用多種方法將 List 轉換為 Set。Set 是一種不允許重複元素的集合,因此轉換過程中會去除重複元素。以下是一些常用的方法:
1. 使用 toSet 函數
toSet 函數是一個簡便的方法,直接將 List 轉換為 Set。
範例:
val list = listOf(1, 2, 2, 3, 4, 4, 5)
val set = list.toSet()
println(set) // [1, 2, 3, 4, 5]
2. 使用 setOf 函數
setOf 函數可以用於創建一個 Set,接受可變參數的元素列表。可以將 List 展開後作為參數傳遞給 setOf。
範例:
val list = listOf(1, 2, 2, 3, 4, 4, 5)
val set = setOf(*list.toTypedArray())
println(set) // [1, 2, 3, 4, 5]
3. 使用 HashSet 構造函數
可以使用 HashSet 的構造函數來創建一個 Set,並將 List 作為參數傳遞給它。
範例:
val list = listOf(1, 2, 2, 3, 4, 4, 5)
val set = HashSet(list)
println(set) // [1, 2, 3, 4, 5]
4. 使用 asSequence 並轉換為 Set
如果想要在轉換過程中應用一些其他操作,可以使用 asSequence,然後再轉換為 Set。
範例:
val list = listOf(1, 2, 2, 3, 4, 4, 5)
val set = list.asSequence().toSet()
println(set) // [1, 2, 3, 4, 5]
【其他】比較 groupBy, groupingBy 和 partition
在 Kotlin 中,groupBy、groupingBy 和 partition 是用來處理集合的方法,這些方法可以幫助我們更有效地對數據進行分組和劃分。以下是這些方法的詳細說明:
1. groupBy
groupBy 方法將集合中的元素根據指定的鍵進行分組(分成多組),並返回一個 Map,其中鍵是根據元素計算出來的,值是對應於該鍵的元素列表。
語法:
fun <T, K> Iterable<T>.groupBy(
keySelector: (T) -> K
): Map<K, List<T>>
範例:
data class Person(val name: String, val age: Int)
val people = listOf(
Person("Alice", 25),
Person("Bob", 30),
Person("Charlie", 25),
Person("David", 30)
)
val groupedByAge = people.groupBy { it.age }
println(groupedByAge)
// Output: {25=[Person(name=Alice, age=25), Person(name=Charlie, age=25)], 30=[Person(name=Bob, age=30), Person(name=David, age=30)]}
2. groupingBy
在 Kotlin 中,groupingBy 是一個很有用的擴展函數,用於將一個集合的元素根據某個鍵(key)進行分組。這個函數返回一個 Grouping 物件,這個物件提供了各種操作來對分組結果進行進一步處理,比如計數、聚合等。
以下是一個使用 groupingBy 的簡單範例:
Grouping 物件提供了一些函數來對分組結果進行進一步的操作:
-
eachCount(): 計算每個分組中的元素個數,返回一個Map<K, Int>,鍵是分組鍵,值是該組的元素個數。 -
fold(initialValue, operation): 針對每一組應用operation函數,並以initialValue作為初始值進行累積操作。 -
reduce(operation): 針對每一組應用operation函數進行累積操作。 -
aggregate(initializer, operation): 與fold類似,但提供更靈活的操作方式,可以根據需要初始化和累積。
語法:
fun <T, K> Iterable<T>.groupingBy(
keySelector: (T) -> K
): Grouping<T, K>
eachCount 範例:
val words = listOf("one", "two", "three", "four", "five", "six")
val grouping = words.groupingBy { it.length }
val countByLength = grouping.eachCount()
println(countByLength)
// Output: {3=2, 4=3, 5=1}
fold 範例:
val fruits = listOf("apple", "banana", "apricot", "blueberry", "avocado")
val lengthSumByInitial = fruits.groupingBy { it.first() }
.fold(0) { acc, e -> acc + e.length }
println(lengthSumByInitial) // {a=17, b=15}
在這個範例中,我們將 fruits 列表中的字串根據第一個字母分組,然後對每個組的字串長度進行累加。
reduce 範例:
val numbers = listOf(1, 2, 3, 4, 5, 6)
val maxByRemainder = numbers.groupingBy { it % 3 }
.reduce { _, a, b -> if (a > b) a else b }
println(maxByRemainder) // {1=4, 2=5, 0=6}
在這個範例中,numbers 列表根據元素除以 3 的餘數進行分組,並在每組中選出最大的數字。
groupingBy 是 Kotlin 集合操作中一個強大而靈活的工具,適用於需要按鍵分組並進行後續處理的情況。透過這個函數,我們可以輕鬆地對集合中的元素進行複雜的分組和聚合操作。
3. partition
partition 方法將集合分成兩個列表,第一個列表包含符合給定條件的元素,第二個列表包含不符合條件的元素。
語法:
fun <T> Iterable<T>.partition(
predicate: (T) -> Boolean
): Pair<List<T>, List<T>>
範例:
val numbers = listOf(1, 2, 3, 4, 5, 6)
val (even, odd) = numbers.partition { it % 2 == 0 }
println(even) // Output: [2, 4, 6]
println(odd) // Output: [1, 3, 5]
總結
groupBy:用於將集合分組成一個Map,鍵是分組的依據,值是分組後的列表。groupingBy:返回一個Grouping物件,允許進一步的分組操作。partition:將集合分為兩部分,一部分符合條件,另一部分不符合條件。
【其他】常見命名
xxxWith(): 傳入物件做某些事
xxxBy{}: 傳入lambda做某件事
xxx/xxxed: ed回傳新物件,沒有ed 直接修改原物件
val list = mutableListOf("bb", "c", "aaa")
println(list) // [bb, c, aaa]
println(list.sortedWith(compareBy { it.length })) // [c, bb, aaa]
println(list.sortedBy{it.length}) // [c, bb, aaa]
list.sorted()
println(list) // [bb, c, aaa]
list.sort()
println(list) // [aaa, bb, c]xxxTo():寫入物件
val numbers = listOf("one", "two", "three", "four", "five")
val tmpMap = mutableListOf<String>("aa")
val tmpMap2 = mutableListOf<String>("bb")
println(numbers.mapTo(tmpMap){it})
// [aa, one, two, three, four, five]
println(numbers.filterTo(tmpMap2){it.length > 3})
// [bb, three, four, five]【Kotlin】集合 Iterable/Collection/List/Set/Map
出處 : https://blog.csdn.net/vitaviva/article/details/107587134

建立集合
不可變更集合 immutable
import java.util.*
import java.text.SimpleDateFormat
/**
* You can edit, run, and share this code.
* play.kotlinlang.org
*/
fun main() {
val list = listOf(1,2,3, null)
// 不為 null List
val notNullList = listOfNotNull(null,1,2,3,null)
val emptyList = emptyList<Int>()
val map = mapOf("foo" to "FOO", "bar" to "BAR", "bar" to "BB")
val set = setOf(4,5,6,6)
println(list) // [1, 2, 3, null]
println(notNullList) // [1, 2, 3]
println(emptyList) // []
println(map) // {foo=FOO, bar=BB}
println(set) // [4, 5, 6]
}
可變更集合 mutable
import java.util.*
import java.text.SimpleDateFormat
/**
* You can edit, run, and share this code.
* play.kotlinlang.org
*/
fun main() {
val list = mutableListOf(1,2,3,3)
val map = mutableMapOf("foo" to "FOO", "bar" to "BAR", "bar" to "BB")
val set = mutableSetOf(1,2,3,3)
println(list) // [1, 2, 3, 3]
println(map) // {foo=FOO, bar=BB}
println(set) // [1, 2, 3]
}
addAll(), list 相加
import java.util.*
import java.text.SimpleDateFormat
fun main() {
val list1 = mutableListOf(1,2,3,4)
val list2 = mutableListOf(5,6,7,8)
println(list1.addAll(list2)) // true (注意當下有返回值)
println(list1) // [1, 2, 3, 4, 5, 6, 7, 8
}
remove(), list 刪除
import java.util.*
import java.text.SimpleDateFormat
fun main() {
val numberList = mutableListOf(1,2,3)
numberList.remove(2)
println(numberList) // [1, 3]
}
索引
import java.util.*
import java.text.SimpleDateFormat
fun main() {
val list = listOf(1,2,3)
val indices: IntRange = list.indices
println(indices)
for(i in list.indices){
println(list[i])
}
/*
0..2
1
2
3
*/
println(list.first()) // 1
println(list.last()) // 3
println(list.lastIndex) // 2 = ( size - 1 )
println(list.size) // 3
}Stream 與 kotlin 比較
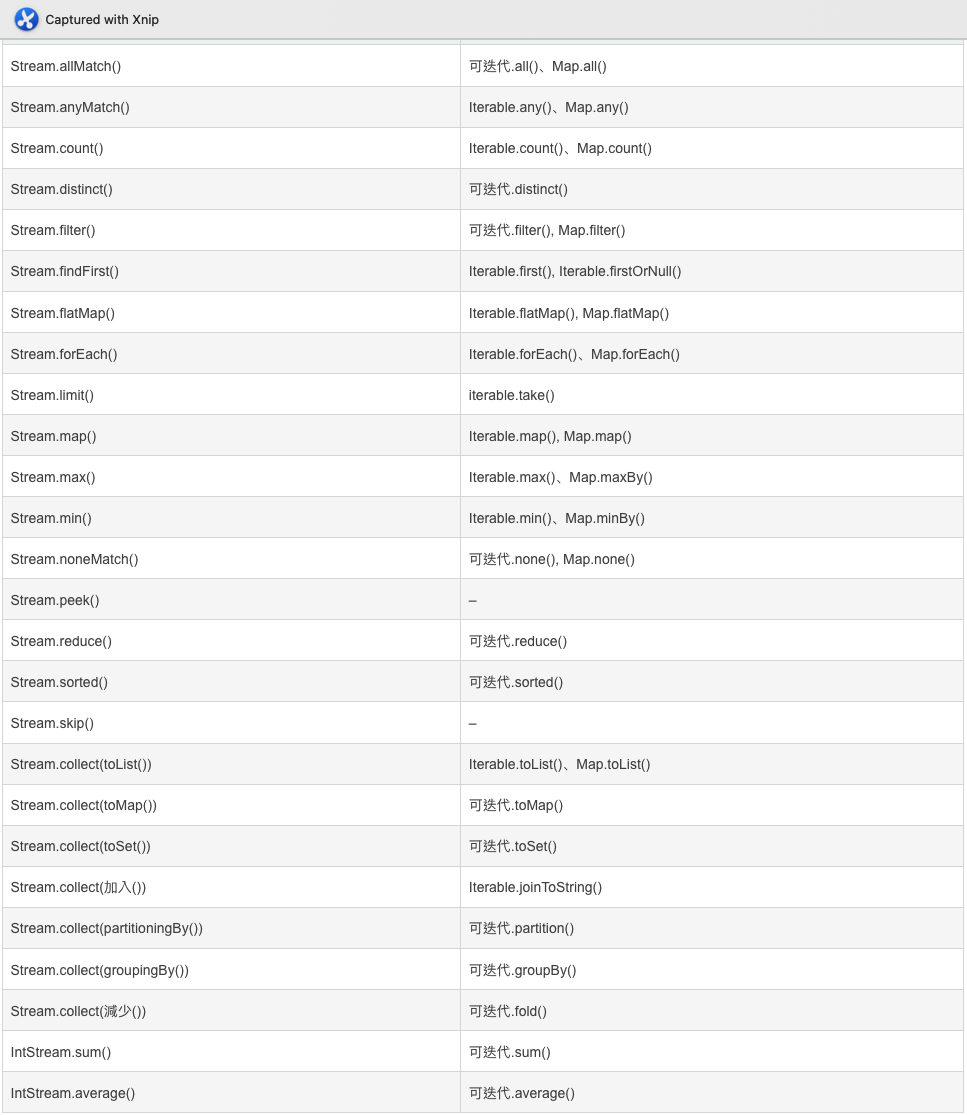
List 相關
list.map{}
import java.util.*
import java.text.SimpleDateFormat
fun main() {
val nameList = listOf("Sam","John",null,"Mary")
val resultList = nameList.map{ "name:" + it }
println(resultList) // [name:Sam, name:John, name:null, name:Mary]
// 過濾null
val resultList2 = nameList.mapNotNull{ it }
println(resultList2) // [Sam, John, Mary]
}
list 保留或排除(removeAll(), retainAll())
import java.util.*
import java.text.SimpleDateFormat
fun main() {
val peopleList = mutableListOf(People("sam",18),People("John",23),People("Mary",30))
// 移除 age > 25
peopleList.removeAll{ it.age > 25 } // [People(name=sam, age=18), People(name=John, age=23)]
println(peopleList)
// 保留 name == sam
val peopleList2 = mutableListOf(People("sam",18),People("John",23),People("Mary",30))
peopleList2.retainAll{ it.name == "sam" } // [People(name=sam, age=18)]
println(peopleList2)
}
list 轉 map
import java.util.*
import java.text.SimpleDateFormat
fun main() {
val peopleList = listOf(People("Sam",12),People("Mary",18), People("Sam",13))
// 指定 key : value
val map = peopleList.associate { it.name to it }
// 指定 key , value => 固定為物件
val map2 = peopleList.associateBy { "name:" + it.name }
println(map) // {Sam=People(name=Sam, age=13), Mary=People(name=Mary, age=18)}
println(map2) // {name:Sam=People(name=Sam, age=13), name:Mary=People(name=Mary, age=18)}
}
data class People(
val name:String,
val age: Int
)isEmpty()
import java.util.*
import java.text.SimpleDateFormat
fun main() {
val list1 = listOf(1,2,3,4)
val list2 = emptyList<Int>()
var list3:List<Int>? = null
println(list1.isEmpty()) // flase
println(list2.isEmpty()) // true
println(list3?.isEmpty()) // null
println(list1.orEmpty()) // [1, 2, 3, 4]
println(list2.orEmpty()) // []
println(list3?.orEmpty()) // null
}
take(), takeLast() 取出list 數量
import java.util.*
import java.text.SimpleDateFormat
fun main() {
val numberList = mutableListOf(1,2,3,4,5,6)
// 從前面取兩個
println(numberList.take(2)) // [1, 2]
// 從後面取兩個
println(numberList.takeLast(2)) // [5, 6]
val noneList :List<Int>? = emptyList()
println(noneList?.take(1)) // []
val nullList :List<Int>? = null
println(nullList?.take(1)) // null
}getOrElse() ,getOrNull()
import java.util.*
import java.text.SimpleDateFormat
fun main() {
val list = listOf(1,2,3,4)
println(list.getOrElse(1,{9})) // 1
println(list.getOrElse(5,{9})) // 9
println(list.getOrNull(1)) // 2
println(list.getOrNull(5)) // null
}
Map 相關
containsKey(), 包含 key
import java.util.*
import java.text.SimpleDateFormat
fun main() {
val numberMap = mapOf("one" to 1,"two" to 2)
println(numberMap.containsKey("one")) // true
val worldMap = mapOf("one" to "ONE","two" to "TWO")
println(worldMap.containsValue("one")) // false
println(worldMap.containsValue("ONE")) // true
}
filter{}, filterNot{}, 過濾
filterKeys{}, filterValues{}
import java.util.*
import java.text.SimpleDateFormat
fun main() {
val worldMap = mapOf("one" to "ONE","two" to "TWO", "three" to "THREE")
println(worldMap.filter {it.key.contains("t")}) // {two=TWO, three=THREE}
println(worldMap.filterNot {it.key.contains("t")}) // {one=ONE}
println(worldMap.filterKeys {key -> key.contains("o")}) // {one=ONE, two=TWO}
println(worldMap.filterValues {value -> value.contains("T")}) // {two=TWO, three=THREE}
}
forEach{}
import java.util.*
import java.text.SimpleDateFormat
fun main() {
val map = mapOf("one" to "ONE","two" to "TWO", "three" to "THREE")
for( (key, value) in map ){
println("key:${key}, value:${value}")
}
// key=one, value=ONE
// key=two, value=TWO
// packagekey=three, value=THREE
map.forEach{
println("key:${it.key},value:${it.value}")
}
// key=one, value=ONE
// key=two, value=TWO
// packagekey=three, value=THREE
}
getOrElse()
isEmpty(), isNotEmpty()
import java.util.*
import java.text.SimpleDateFormat
fun main() {
val map = mapOf("one" to "ONE","two" to "TWO", "three" to "THREE")
println(map.getOrElse("one",{"Default"})) // ONE
println(map.getOrElse("four",{"Default"})) // Default
val map2 = mapOf<String,String>()
val map3 :MutableMap<String,String>? = null
println(map.isEmpty()) // false
println(map.isNotEmpty()) // true
println(map.orEmpty()) // {one=ONE, two=TWO, three=THREE}
println(map2.isEmpty()) // true
println(map2.isNotEmpty()) // false
println(map2.orEmpty()) // {}
println(map3?.isEmpty()) // null
println(map3?.isNotEmpty()) // null
println(map3?.orEmpty()) // null
}
count(), 數量, 有條件的數量
import java.util.*
import java.text.SimpleDateFormat
fun main() {
val worldMap = mapOf("one" to "ONE","two" to "TWO", "three" to "THREE")
println(worldMap.count()) // 3
println(worldMap.count{ it.key.contains("t")}) // 2
}
【Kotlin】Sequence
Sequence
在 Kotlin 中,Sequence 是一種延遲計算(lazy evaluation)的集合類型,用於處理大量或潛在無限數據的情況。Sequence 的主要特點是每次需要元素時才會進行計算,這有助於優化性能並節省內存。以下是 Sequence 的主要特點及用法:
特點
- 延遲計算:只有在需要元素時才會計算,這與立即計算(eager evaluation)不同。
- 中間操作和終端操作:中間操作(如 map、filter)是延遲計算的,終端操作(如 toList、sum)會觸發整個計算過程。
- 無限序列:可以處理無限長度的序列,只要終端操作不需要遍歷整個序列即可。
用法
創建 Sequence
可以從現有集合或使用生成函數來創建 Sequence。
val sequence = sequenceOf(1, 2, 3, 4, 5)
從集合創建:
val list = listOf(1, 2, 3, 4, 5)
val sequenceFromList = list.asSequence()
使用生成函數創建:
val generatedSequence = generateSequence(1) { it + 1 }
中間操作
中間操作是延遲計算的,只有在終端操作觸發時才會計算。
val sequence = sequenceOf(1, 2, 3, 4, 5)
.map { it * 2 }
.filter { it > 5 }
上面的 map 和 filter 操作都不會立即執行。
終端操作
終端操作會觸發整個計算過程,並返回一個結果。
val result = sequence.toList() // [6, 8, 10]
常見的終端操作有 toList()、sum()、first()、count() 等。
範例
fun main() {
val sequence = generateSequence(1) { it + 1 }
.map { it * 2 }
.filter { it % 3 == 0 }
// 取前五個符合條件的數字
val result = sequence.take(5).toList()
println(result) // [6, 12, 18, 24, 30]
}
在這個範例中,我們生成一個從 1 開始的無限序列,然後對每個數字乘以 2,再篩選出能被 3 整除的數字。最後使用 take(5) 取出前五個符合條件的數字並轉換成列表。
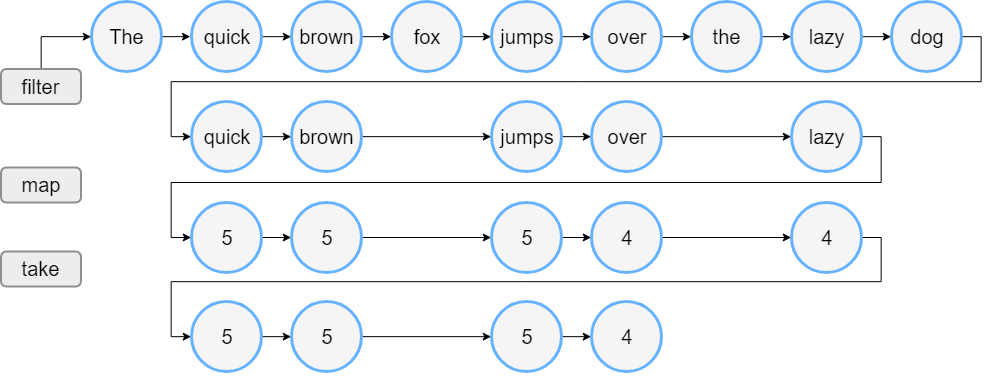
Sequence 在需要處理大量數據或無限數據流時特別有用,因為它可以有效地管理計算資源並避免不必要的計算。
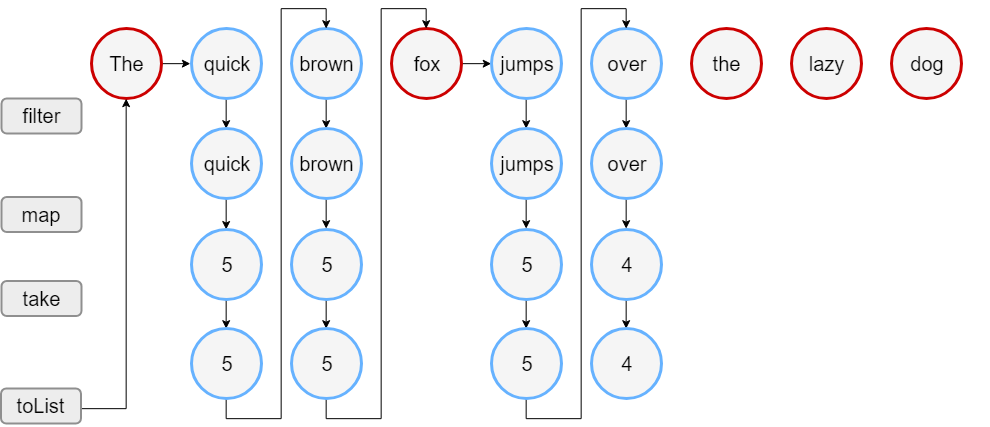
【Kotlin】Gson 使用指南
Gson 使用指南
- 概覽
- Gson 的目標
- Gson 的效能和擴展性
- Gson 使用者
- 使用 Gson
- 在 Gradle/Android 中使用 Gson
- 在 Maven 中使用 Gson
- 基本類型範例
- 物件範例
- 物件的細節
- 巢狀類別(包括內部類別)
- 陣列範例
- 集合範例
- 集合的限制
- Map 範例
- 序列化和反序列化泛型類型
- 序列化和反序列化包含任意類型物件的集合
- 內建的序列化器和反序列化器
- 自定義序列化和反序列化
- 撰寫序列化器
- 撰寫反序列化器
- 撰寫實例創建器
- Parameterized 類型的 InstanceCreator
- JSON 輸出格式的壓縮與漂亮印出
- Null 物件支援
- 版本支援
- 從序列化和反序列化中排除欄位
- Java 修飾符排除
- Gson 的
@Expose - 使用者定義的排除策略
- JSON 欄位命名支援
- 在自定義序列化器和反序列化器之間共享狀態
- 串流
- 設計 Gson 時遇到的問題
- Gson 的未來增強
概覽
Gson 是一個 Java 函式庫,可以用來將 Java 物件轉換成其 JSON 表示形式,也可以用來將 JSON 字串轉換成等效的 Java 物件。
Gson 可以處理任意的 Java 物件,包括您無法取得原始碼的既有物件。
Gson 的目標
- 提供簡單易用的機制,例如
toString()和構造器(工廠方法),以在 Java 和 JSON 之間進行轉換。 - 允許既有的不可修改的物件轉換為 JSON,或從 JSON 轉換回來。
- 允許物件的自定義表示形式。
- 支援任意複雜的物件。
- 產生簡潔且可讀的 JSON 輸出。
Gson 的效能和擴展性
以下是我們在一台桌面電腦(雙 Opteron 處理器,8GB RAM,64 位元 Ubuntu 系統)上進行多項測試時取得的一些效能指標。您可以使用類別 PerformanceTest 來重新執行這些測試。
- 字串:反序列化超過 25MB 的字串沒有任何問題(參見
PerformanceTest中的disabled_testStringDeserializationPerformance方法) - 大型集合:
- 序列化了一個包含 140 萬個物件的集合(參見
PerformanceTest中的disabled_testLargeCollectionSerialization方法) - 反序列化了一個包含 87,000 個物件的集合(參見
PerformanceTest中的disabled_testLargeCollectionDeserialization方法)
- 序列化了一個包含 140 萬個物件的集合(參見
- Gson 1.4 將位元組陣列和集合的反序列化限制從 80KB 提升到超過 11MB。
注意:要執行這些測試,請刪除 disabled_ 前綴。我們使用這個前綴來防止每次運行 JUnit 測試時都執行這些測試。
Gson 使用者
Gson 最初是為了在 Google 內部使用而創建的,現在它在 Google 的許多專案中都有使用。它現在也被許多公共專案和公司使用。
使用 Gson
主要使用的類別是 Gson,您只需通過呼叫 new Gson() 來創建它。此外,還有一個類別 GsonBuilder,可用於創建具有各種設定(例如版本控制等)的 Gson 實例。
在調用 JSON 操作時,Gson 實例不會維護任何狀態。因此,您可以自由地重複使用相同的物件進行多次 JSON 序列化和反序列化操作。
在 Gradle/Android 中使用 Gson
dependencies {
implementation 'com.google.code.gson:gson:2.11.0'
}
在 Maven 中使用 Gson
要在 Maven2/3 中使用 Gson,您可以通過添加以下依賴項來使用 Maven 中央庫中提供的 Gson 版本:
<dependencies>
<!-- Gson: Java to JSON conversion -->
<dependency>
<groupId>com.google.code.gson</groupId>
<artifactId>gson</artifactId>
<version>2.11.0</version>
<scope>compile</scope>
</dependency>
</dependencies>
這樣您的 Maven 專案就可以使用 Gson 了。
基本類型範例
// 序列化
val gson = Gson()
gson.toJson(1) // ==> 1
gson.toJson("abcd") // ==> "abcd"
gson.toJson(10L) // ==> 10
val values = intArrayOf(1)
gson.toJson(values) // ==> [1]
// 反序列化
val i = gson.fromJson("1", Int::class.java)
val intObj = gson.fromJson("1", Int::class.javaObjectType)
val longObj = gson.fromJson("1", Long::class.javaObjectType)
val boolObj = gson.fromJson("false", Boolean::class.javaObjectType)
val str = gson.fromJson("\"abc\"", String::class.java)
val strArray = gson.fromJson("[\"abc\"]", Array<String>::class.java)
物件範例
class BagOfPrimitives {
private val value1 = 1
private val value2 = "abc"
private val value3 = 3 // 被標記為 transient 但不需要標記
// 無參數構造器,Kotlin 默認會有
}
// 序列化
val obj = BagOfPrimitives()
val gson = Gson()
val json = gson.toJson(obj)
// ==> {"value1":1,"value2":"abc"}
注意,您無法序列化具有循環引用的物件,因為這會導致無限遞歸。
// 反序列化
val obj2 = gson.fromJson(json, BagOfPrimitives::class.java)
// ==> obj2 和 obj 一樣
物件的細節
- 使用 private 欄位是完全可以的(並且建議這樣做)。
- 不需要使用任何註解來指示欄位是否應
該包含在序列化和反序列化中。當前類別中的所有欄位(以及所有超類別中的欄位)默認都會被包含。
- 如果欄位被標記為 transient,(默認情況下)它將被忽略,不包含在 JSON 序列化或反序列化中。
- 這個實現正確地處理 null 值。
- 在序列化時,null 欄位會從輸出中省略。
- 在反序列化時,JSON 中缺少的條目會導致將對應的物件欄位設置為其默認值:對於物件類型為 null,對於數值類型為零,對於布林值為 false。
- 如果欄位是 synthetic 的,它將被忽略,不包含在 JSON 序列化或反序列化中。
- 內部類別中對應於外部類別的欄位將被忽略,不包含在序列化或反序列化中。
- 匿名和本地類別將被排除。它們將作為 JSON
null被序列化,而在反序列化時,它們的 JSON 值將被忽略,返回null。要啟用序列化和反序列化,請將這些類別轉換為static的嵌套類別。
巢狀類別(包括內部類別)
Gson 可以輕鬆地序列化靜態巢狀類別。
Gson 也可以反序列化靜態巢狀類別。然而,Gson 無法自動反序列化 純內部類別,因為它們的無參數構造器還需要一個參照包含物件的引用,而在反序列化時這個引用並不存在。您可以通過將內部類別設為靜態類別,或為其提供一個自定義的 InstanceCreator 來解決這個問題。以下是範例:
class A {
var a: String? = null
inner class B {
var b: String? = null
constructor() {
// 無參數構造器
}
}
}
注意:上述類別 B 無法(默認情況下)用 Gson 進行序列化。
Gson 無法將 {"b":"abc"} 反序列化為 B 的實例,因為 B 類別是內部類別。如果它被定義為靜態類別 B,那麼 Gson 就能夠反序列化該字串。另一個解決方案是為 B 撰寫自定義的實例創建器。
class InstanceCreatorForB(private val a: A) : InstanceCreator<A.B> {
override fun createInstance(type: Type): A.B {
return a.B()
}
}
上述方法是可行的,但並不推薦使用。
陣列範例
val gson = Gson()
val ints = intArrayOf(1, 2, 3, 4, 5)
val strings = arrayOf("abc", "def", "ghi")
// 序列化
gson.toJson(ints) // ==> [1,2,3,4,5]
gson.toJson(strings) // ==> ["abc", "def", "ghi"]
// 反序列化
val ints2 = gson.fromJson("[1,2,3,4,5]", IntArray::class.java)
// ==> ints2 將和 ints 相同
我們還支援多維陣列,具有任意複雜的元素類型。
集合範例
val gson = Gson()
val ints: Collection<Int> = listOf(1, 2, 3, 4, 5)
// 序列化
val json = gson.toJson(ints) // ==> [1,2,3,4,5]
// 反序列化
val collectionType = object : TypeToken<Collection<Int>>() {}.type
val ints2: Collection<Int> = gson.fromJson(json, collectionType)
// ==> ints2 和 ints 相同
這種方法比較麻煩:請注意我們如何定義集合的類型。 遺憾的是,在 Java 中無法避免這個問題。
集合的限制
Gson 可以序列化任意物件的集合,但無法從中反序列化,因為無法讓使用者指示結果物件的類型。相反,在反序列化時,集合必須是特定的泛型類型。 這是合理的,在遵循良好的 Java 編碼實踐時,這很少會是個問題。
Map 範例
Gson 預設將任何 java.util.Map 實作序列化為 JSON 物件。由於 JSON 物件僅支援字串作為成員名稱,Gson 通過呼叫 toString() 將 Map 的鍵轉換為字串,並對於 null 鍵使用 "null":
val gson = Gson()
val stringMap = linkedMapOf("key" to "value", null to "null-entry")
// 序列化
val json = gson.toJson(stringMap) // ==> {"key":"value","null":"null-entry"}
val intMap = linkedMapOf(2 to 4, 3 to 6)
// 序列化
val json2 = gson.toJson(intMap) // ==> {"2":4,"3":6}
在反序列化時,Gson 使用為 Map 鍵類型註冊的 TypeAdapter 的 read 方法。與上面顯示的集合範例類似,反序列化時必須使用 TypeToken 來告訴 Gson Map 鍵和值的類型:
val gson = Gson()
val mapType = object : TypeToken<Map<String, String>>() {}.type
val json = "{\"key\": \"value\"}"
// 反序列化
val stringMap: Map<String, String> = gson.fromJson(json, mapType)
// ==> stringMap 是 {key=value}
Gson 還支援使用複雜類型作為 Map 鍵。這個功能可以通過 GsonBuilder.enableComplexMapKeySerialization()) 啟用。如果啟用,Gson 使用為 Map 鍵類型註冊的 TypeAdapter 的 write 方法來序列化鍵,而不是使用 toString()。當任何鍵被適配器序列化為 JSON 陣列或 JSON 物件時,Gson 將整個 Map 序列化為 JSON 陣列,由鍵值對(編碼為 JSON 陣列)組成。否則,如果沒有鍵被序列化為 JSON 陣列或 JSON 物件,Gson 將使用 JSON 物件來編碼 Map:
data class PersonName(val firstName: String, val lastName: String)
val gson = GsonBuilder().enableComplexMapKeySerialization().create()
val complexMap = linkedMapOf(PersonName("John", "Doe") to 30, PersonName("Jane", "Doe") to 35)
// 序列化;複雜的 Map 被序列化為一個 JSON 陣列,包含鍵值對(作為 JSON 陣列)
val json = gson.toJson(complexMap)
// ==> [[{"firstName":"John","lastName":"Doe"},30],[{"firstName":"Jane","lastName":"Doe"},35]]
val stringMap = linkedMapOf("key" to "value")
// 序列化;非複雜 Map 被序列化為一個常規 JSON 物件
val json2 = gson.toJson(stringMap) // ==> {"key":"value"}
重要提示: 因為 Gson 默認使用 toString() 來序列化 Map 鍵,這可能會導致鍵的編碼不正確或在序列化和反序列化之間產生不匹配,例如當 toString() 沒有正確實作時。可以使用 enableComplexMapKeySerialization() 作為解決方法,確保 TypeAdapter 註冊在 Map 鍵類型中被用於反序列化和序列化。如上例所示,當沒有鍵被適配器序列化為 JSON 陣列或 JSON 物件時,Map 將被序列化為常規 JSON 物件,這是期望的結果。
注意,當反序列化枚舉類型作為 Map 鍵時,如果 Gson 無法找到與相應 name() 值(或 @SerializedName 註解)匹配的枚舉常數,它會退回到通過 toString() 值查找枚
舉常數。這是為了解決上述問題,但僅適用於枚舉常數。
序列化和反序列化泛型類型
當您呼叫 toJson(obj) 時,Gson 呼叫 obj.getClass() 來獲取要序列化的欄位資訊。同樣,您通常可以在 fromJson(json, MyClass.class) 方法中傳入 MyClass.class 物件。這對於非泛型類型的物件來說效果很好。然而,如果物件是泛型類型,那麼由於 Java 類型擦除,泛型類型資訊就會丟失。以下是說明這一點的範例:
class Foo<T>(var value: T)
val gson = Gson()
val foo = Foo(Bar())
gson.toJson(foo) // 可能無法正確序列化 foo.value
gson.fromJson<Foo<Bar>>(json, foo::class.java) // 無法將 foo.value 反序列化為 Bar
上述代碼無法將 value 解釋為 Bar 類型,因為 Gson 調用 foo::class.java 來獲取其類別資訊,但此方法返回原始類別,Foo::class.java。這意味著 Gson 無法知道這是一個 Foo<Bar> 類型的物件,而不僅僅是普通的 Foo。
您可以通過為您的泛型類型指定正確的參數化類型來解決這個問題。您可以使用 TypeToken 類別來實現這一點。
val fooType = object : TypeToken<Foo<Bar>>() {}.type
gson.toJson(foo, fooType)
gson.fromJson<Foo<Bar>>(json, fooType)
用於獲取 fooType 的慣用方法實際上定義了一個匿名的本地內部類別,包含一個 getType() 方法,該方法返回完整的參數化類型。
序列化和反序列化包含任意類型物件的集合
有時候您會處理包含混合類型的 JSON 陣列。例如: ['hello',5,{name:'GREETINGS',source:'guest'}]
等效的 Collection 包含以下內容:
val collection = mutableListOf<Any>("hello", 5, Event("GREETINGS", "guest"))
其中 Event 類別定義如下:
data class Event(val name: String, val source: String)
您可以使用 Gson 序列化這個集合而不需要做任何特殊處理:toJson(collection) 會輸出所需的結果。
然而,使用 fromJson(json, Collection::class.java) 進行反序列化是不會成功的,因為 Gson 無法知道如何將輸入映射到類型。Gson 要求您在 fromJson() 中提供集合類型的泛型版本。因此,您有三個選擇:
-
使用 Gson 的解析 API(低階串流解析器或 DOM 解析器 JsonParser)來解析陣列元素,然後對每個陣列元素使用
Gson.fromJson()。這是首選方法。這裡有一個範例 展示了如何做到這一點。 -
為
Collection::class.java註冊一個型別適配器,該適配器檢查每個陣列成員並將它們映射到適當的物件。這種方法的缺點是它會搞亂 Gson 中其他集合類型的反序列化。 -
為
MyCollectionMemberType註冊一個型別適配器,並使用fromJson()與Collection<MyCollectionMemberType>。
此方法僅在陣列作為頂層元素出現時適用,或者您可以更改保存集合的欄位類型為 Collection<MyCollectionMemberType>。
內建的序列化器和反序列化器
Gson 內建了常用類別的序列化器和反序列化器,這些類別的默認表示方式可能不合適,例如:
java.net.URL以匹配"https://github.com/google/gson/"這樣的字串java.net.URI以匹配"/google/gson/"這樣的字串
更多資訊,請參見內部類別 TypeAdapters。
您也可以在此頁面找到一些常用類別(如 JodaTime)的原始碼。
自定義序列化和反序列化
有時候默認的表示方式不是您想要的。這種情況通常發生在處理庫類別(例如 DateTime 等)時。 Gson 允許您註冊自己的自定義序列化器和反序列化器。這是通過定義兩個部分來完成的:
- JSON 序列化器:需要為物件定義自定義序列化
-
JSON 反序列化器:需要為類型定義自定義反序列化
-
實例創建器:如果有無參數構造器可用或註冊了一個反序列化器,則不需要
val gsonBuilder = GsonBuilder()
gsonBuilder.registerTypeAdapter(MyType2::class.java, MyTypeAdapter())
gsonBuilder.registerTypeAdapter(MyType::class.java, MySerializer())
gsonBuilder.registerTypeAdapter(MyType::class.java, MyDeserializer())
gsonBuilder.registerTypeAdapter(MyType::class.java, MyInstanceCreator())
registerTypeAdapter 呼叫檢查:
- 如果型別適配器實作了這些介面中的多個,則會為所有這些介面註冊該適配器。
- 如果型別適配器適用於 Object 類別或 JsonElement 或其任何子類別,則會拋出 IllegalArgumentException,因為不支援覆蓋這些類型的內建適配器。
撰寫序列化器
以下是一個撰寫 JodaTime DateTime 類別自定義序列化器的範例。
private class DateTimeSerializer : JsonSerializer<DateTime> {
override fun serialize(src: DateTime?, typeOfSrc: Type, context: JsonSerializationContext): JsonElement {
return JsonPrimitive(src.toString())
}
}
Gson 在序列化期間遇到 DateTime 物件時會呼叫 serialize()。
撰寫反序列化器
以下是一個撰寫 JodaTime DateTime 類別自定義反序列化器的範例。
private class DateTimeDeserializer : JsonDeserializer<DateTime> {
override fun deserialize(json: JsonElement, typeOfT: Type, context: JsonDeserializationContext): DateTime {
return DateTime(json.asJsonPrimitive.asString)
}
}
Gson 在需要將 JSON 字串片段反序列化為 DateTime 物件時會呼叫 deserialize。
關於序列化器和反序列化器的細節
通常您希望為所有對應於原始類型的泛型類型註冊一個處理程序
- 例如,假設您有一個
Id類別,用於 ID 的表示/轉換(即內部 vs. 外部表示)。 Id<T>類型對所有泛型類型具有相同的序列化- 實質上是寫出 ID 值
- 反序列化非常相似,但不完全相同
- 需要呼叫
new Id(Class<T>, String),它返回一個Id<T>的實例
- 需要呼叫
Gson 支援為此註冊一個處理程序。您還可以為特定泛型類型(例如需要特殊處理的 Id<RequiresSpecialHandling>)註冊一個特定的處理程序。 toJson() 和 fromJson() 的 Type 參數包含泛型類型資訊,幫助您為所有對應的泛型類型撰寫單個處理程序。
撰寫實例創建器
在反序列化物件時,Gson 需要創建類別的預設實例。 行為良好的類別(用於序列化和反序列化的)應該有一個無參數構造器。
- 無論是 public 還是 private 都無所謂
通常,當您處理的庫類別沒有定義無參數構造器時,需要實例創建器。
實例創建器範例
private class MoneyInstanceCreator : InstanceCreator<Money> {
override fun createInstance(type: Type): Money {
return Money("1000000", CurrencyCode.USD)
}
}
Type 可能是相應泛型類型的。
- 非常有用,可以呼叫需要特定泛型類型資訊的構造器
- 例如,如果
Id類別存儲了創建 ID 的類別
Parameterized 類型的 InstanceCreator
有時候您要實例化的類型是參數化類型。一般來說,這不是問題,因為實際的實例是原始類型。以下是一個範例:
class MyList<T> : ArrayList<T>()
class MyListInstanceCreator : InstanceCreator<MyList<*>> {
override fun createInstance(type: Type): MyList<*> {
// 不需要使用參數化列表,因為實際實例無論如何都將具有原始類型。
return MyList<Any?>()
}
}
然而,有時候您確實需要根據實際的參數化類型創建實例。在這種情況下,您可以使用傳遞給 createInstance 方法的類型參數。以下是一個範例:
class Id<T>(private val classOfId: Class<T>, private val value: Long)
class IdInstanceCreator : InstanceCreator<Id<*>> {
override fun createInstance(type: Type): Id<*> {
val typeParameters = (type as ParameterizedType).actualTypeArguments
val idType = typeParameters[0] as Class<*> // Id 只有一個參數化類型 T
return Id(idType, 0L)
}
}
在上述範例中,如果不傳入參數化類型的實際類型,就無法創建 Id 類別的實例。我們通過使用傳遞的參數 type 解決了這個問題。在這個例子中,type 物件是 Id<Foo> 的 Java 參數化類型表示,其中實際的實例應綁定為 Id<Foo>。由於 Id 類別只有一個參數化類型參數 T,我們使用 getActualTypeArgument() 返回的類型數組的第零個元素,它在這種情況下將持有 Foo.class。
JSON 輸出格式的壓縮與漂亮印出
Gson 提供的預設 JSON 輸出格式是一種緊湊的 JSON 格式。這意味著在輸出 JSON 結構中不會有任何空白。因此,在 JSON 輸出中,欄位名稱與其值、物件欄位以及陣列中的物件之間不會有空白。另外,"null" 欄位將在輸出中被忽略(注意:在物件集合/陣列中,null 值仍然會被包括)。請參見 Null 物件支援 部分,了解如何配置 Gson 以輸出所有 null 值。
如果您想使用漂亮印出功能,必須使用 GsonBuilder 來配置您的 Gson 實例。JsonFormatter 並未通過我們的公開 API 曝露,因此用戶端無法配置 JSON 輸出的默認打印設定/邊距。目前,我們僅提供一個默認的 JsonPrintFormatter,該格式器具有 80 字元的默認行長、2 字元的縮排和 4 字元的右邊距。
以下範例顯示了如何配置 Gson 實例以使用默認的 JsonPrintFormatter 而非 JsonCompactFormatter:
val gson = GsonBuilder().setPrettyPrinting().create()
val jsonOutput = gson.toJson(someObject)
Null 物件支援
Gson 實作的預設行為是忽略 null 物件欄位。這允許更緊湊的輸出格式;然而,當 JSON 格式轉換回其 Java 形式時,用戶端必須為這些欄位定義一個默認值。
以下是如何配置 Gson 實例以輸出 null 的範例:
val gson = GsonBuilder().serializeNulls().create()
注意:使用 Gson 序列化 null 時,它會向 JsonElement 結構添加一個 JsonNull 元素。因此,這個物件可以在自定義序列化/反序列化中使用。
以下是一個範例:
data class Foo(val s: String? = null, val i: Int = 5)
val gson = GsonBuilder().serializeNulls().create()
val foo = Foo()
var json = gson.toJson(foo)
println(json)
json = gson.toJson(null)
println(json)
輸出是:
{"s":null,"i":5}
null
版本支援
可以使用 @Since 註解來維護同一物件的多個版本。此註解可以用於類別、欄位,未來版本中也可用於方法。為了利用此功能,您必須配置您的 Gson 實例以忽略任何高於某個版本號的欄位/物件。如果在 Gson 實例上未設定版本,則它將序列化和反序列化所有欄位和類別,而不考慮版本。
data class VersionedClass(
@Since(1.1) val newerField: String = "newer",
@Since(1.0) val newField: String = "new",
val field: String = "old"
)
val versionedObject = VersionedClass()
var gson = GsonBuilder().setVersion(1.0).create()
var jsonOutput = gson.toJson(versionedObject)
println(jsonOutput)
println()
gson = Gson()
jsonOutput = gson.toJson(versionedObject)
println(jsonOutput)
輸出是:
{"newField":"new","field":"old"}
{"newerField":"newer","newField":"new","field":"old"}
從序列化和反序列化中排除欄位
Gson 支援多種機制來排除頂層類別、欄位和欄位類型。下面是可插入的機制,允許排除欄位和類別。如果下列機制無法滿足您的需求,您還可以使用自定義序列化器和反序列化器。
Java 修飾符排除
默認情況下,如果您將欄位標記為 transient,則該欄位將被排除。同樣,如果欄位標記為 static,則默認情況下也會被排除。如果您想包括某些 transient 欄位,可以按以下方式進行操作:
import java.lang.reflect.Modifier
val gson = GsonBuilder()
.excludeFieldsWithModifiers(Modifier.STATIC)
.create()
注意:您可以向 excludeFieldsWithModifiers 方法提供任意數量的 Modifier 常數。例如:
val gson = GsonBuilder()
.excludeFieldsWithModifiers(Modifier.STATIC, Modifier.TRANSIENT, Modifier.VOLATILE)
.create()
Gson 的 @Expose
此功能提供了一種方法,您可以標記物件的某些欄位,以排除它們不被考慮進行序列化和反序列化為 JSON。要使用此註解,您必須通過使用 new GsonBuilder().excludeFieldsWithoutExposeAnnotation().create() 創建 Gson。創建的 Gson 實例將排除類別中未標記 @Expose 註解的所有欄位。
使用者定義的排除策略
如果上述排除欄位和類別類型的機制對您不起作用,則可以撰寫自己的排除策略並將其插入到 Gson 中。詳細資訊請參見 ExclusionStrategy JavaDoc。
以下範例展示了如何排除具有特定 @Foo 註解的欄位,並排除類別 String 的頂層類型(或聲明的欄位類型)。
@Retention(AnnotationRetention.RUNTIME)
@Target(AnnotationTarget.FIELD)
annotation class Foo
data class SampleObjectForTest(
@Foo val annotatedField:
Int = 5,
val stringField: String = "someDefaultValue",
val longField: Long = 1234L
)
class MyExclusionStrategy(private val typeToSkip: Class<*>) : ExclusionStrategy {
override fun shouldSkipClass(clazz: Class<*>): Boolean {
return clazz == typeToSkip
}
override fun shouldSkipField(f: FieldAttributes): Boolean {
return f.getAnnotation(Foo::class.java) != null
}
}
fun main() {
val gson = GsonBuilder()
.setExclusionStrategies(MyExclusionStrategy(String::class.java))
.serializeNulls()
.create()
val src = SampleObjectForTest()
val json = gson.toJson(src)
println(json)
}
輸出是:
{"longField":1234}
JSON 欄位命名支援
Gson 支援一些預定義的欄位命名策略,用於將標準 Java 欄位名稱(即,以小寫字母開頭的駝峰式命名,例如 sampleFieldNameInJava)轉換為 JSON 欄位名稱(例如,sample_field_name_in_java 或 SampleFieldNameInJava)。有關預定義命名策略的資訊,請參見 FieldNamingPolicy 類別。
它還有基於註解的策略,允許客戶端根據每個欄位定義自定義名稱。請注意,基於註解的策略具有欄位名稱驗證功能,如果提供的欄位名稱無效,將引發「執行時」異常。
以下是如何使用 Gson 命名策略功能的範例:
data class SomeObject(
@SerializedName("custom_naming") val someField: String,
val someOtherField: String
)
val someObject = SomeObject("first", "second")
val gson = GsonBuilder().setFieldNamingPolicy(FieldNamingPolicy.UPPER_CAMEL_CASE).create()
val jsonRepresentation = gson.toJson(someObject)
println(jsonRepresentation)
輸出是:
{"custom_naming":"first","SomeOtherField":"second"}
如果您需要自定義命名策略(請參見此討論),您可以使用 @SerializedName 註解。
在自定義序列化器和反序列化器之間共享狀態
有時候您需要在自定義序列化器/反序列化器之間共享狀態(請參見此討論)。您可以使用以下三種策略來實現:
- 將共享狀態存儲在靜態欄位中
- 將序列化器/反序列化器聲明為父類型的內部類別,並使用父類型的實例欄位來存儲共享狀態
- 使用 Java
ThreadLocal
1 和 2 都不是線程安全的選項,但 3 是。
串流
除了 Gson 的物件模型和數據綁定外,您還可以使用 Gson 來讀取和寫入串流。您還可以結合串流和物件模型訪問,以獲得兩種方法的最佳效果。
設計 Gson 時遇到的問題
請參見 Gson 設計文檔,了解我們在設計 Gson 時面臨的問題討論。它還包括 Gson 與其他可用於 JSON 轉換的 Java 函式庫的比較。
Gson 的未來增強
欲了解最新的增強提議列表,或如果您想建議新功能,請參見項目網站下的 Issues 部分。
/*
* Copyright (C) 2008 Google Inc.
*
* Licensed under the Apache License, Version 2.0 (the "License");
* you may not use this file except in compliance with the License.
* You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
package com.google.gson.metrics;
import static com.google.common.truth.Truth.assertThat;
import com.google.gson.Gson;
import com.google.gson.JsonParseException;
import com.google.gson.annotations.Expose;
import com.google.gson.reflect.TypeToken;
import java.io.StringWriter;
import java.lang.reflect.Type;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import org.junit.Before;
import org.junit.Ignore;
import org.junit.Test;
/**
* Tests to measure performance for Gson. All tests in this file will be disabled in code. To run
* them remove the {@code @Ignore} annotation from the tests.
*
* @author Inderjeet Singh
* @author Joel Leitch
*/
@SuppressWarnings("SystemOut") // allow System.out because test is for manual execution anyway
public class PerformanceTest {
private static final int COLLECTION_SIZE = 5000;
private static final int NUM_ITERATIONS = 100;
private Gson gson;
@Before
public void setUp() throws Exception {
gson = new Gson();
}
@Test
public void testDummy() {
// This is here to prevent Junit for complaining when we disable all tests.
}
@Test
@Ignore
public void testStringDeserialization() {
StringBuilder sb = new StringBuilder(8096);
sb.append("Error Yippie");
while (true) {
try {
String stackTrace = sb.toString();
sb.append(stackTrace);
String json = "{\"message\":\"Error message.\"," + "\"stackTrace\":\"" + stackTrace + "\"}";
parseLongJson(json);
System.out.println("Gson could handle a string of size: " + stackTrace.length());
} catch (JsonParseException expected) {
break;
}
}
}
private void parseLongJson(String json) throws JsonParseException {
ExceptionHolder target = gson.fromJson(json, ExceptionHolder.class);
assertThat(target.message).contains("Error");
assertThat(target.stackTrace).contains("Yippie");
}
private static class ExceptionHolder {
public final String message;
public final String stackTrace;
// For use by Gson
@SuppressWarnings("unused")
private ExceptionHolder() {
this("", "");
}
public ExceptionHolder(String message, String stackTrace) {
this.message = message;
this.stackTrace = stackTrace;
}
}
@SuppressWarnings("unused")
private static class CollectionEntry {
final String name;
final String value;
// For use by Gson
private CollectionEntry() {
this(null, null);
}
CollectionEntry(String name, String value) {
this.name = name;
this.value = value;
}
}
/** Created in response to http://code.google.com/p/google-gson/issues/detail?id=96 */
@Test
@Ignore
public void testLargeCollectionSerialization() {
int count = 1400000;
List<CollectionEntry> list = new ArrayList<>(count);
for (int i = 0; i < count; ++i) {
list.add(new CollectionEntry("name" + i, "value" + i));
}
String unused = gson.toJson(list);
}
/** Created in response to http://code.google.com/p/google-gson/issues/detail?id=96 */
@Test
@Ignore
public void testLargeCollectionDeserialization() {
StringBuilder sb = new StringBuilder();
int count = 87000;
boolean first = true;
sb.append('[');
for (int i = 0; i < count; ++i) {
if (first) {
first = false;
} else {
sb.append(',');
}
sb.append("{name:'name").append(i).append("',value:'value").append(i).append("'}");
}
sb.append(']');
String json = sb.toString();
Type collectionType = new TypeToken<ArrayList<CollectionEntry>>() {}.getType();
List<CollectionEntry> list = gson.fromJson(json, collectionType);
assertThat(list).hasSize(count);
}
/** Created in response to http://code.google.com/p/google-gson/issues/detail?id=96 */
// Last I tested, Gson was able to serialize upto 14MB byte array
@Test
@Ignore
public void testByteArraySerialization() {
for (int size = 4145152; true; size += 1036288) {
byte[] ba = new byte[size];
for (int i = 0; i < size; ++i) {
ba[i] = 0x05;
}
String unused = gson.toJson(ba);
System.out.printf("Gson could serialize a byte array of size: %d\n", size);
}
}
/** Created in response to http://code.google.com/p/google-gson/issues/detail?id=96 */
// Last I tested, Gson was able to deserialize a byte array of 11MB
@Test
@Ignore
public void testByteArrayDeserialization() {
for (int numElements = 10639296; true; numElements += 16384) {
StringBuilder sb = new StringBuilder(numElements * 2);
sb.append("[");
boolean first = true;
for (int i = 0; i < numElements; ++i) {
if (first) {
first = false;
} else {
sb.append(",");
}
sb.append("5");
}
sb.append("]");
String json = sb.toString();
byte[] ba = gson.fromJson(json, byte[].class);
System.out.printf("Gson could deserialize a byte array of size: %d\n", ba.length);
}
}
// The tests to measure serialization and deserialization performance of Gson
// Based on the discussion at
// http://groups.google.com/group/google-gson/browse_thread/thread/7a50b17a390dfaeb
// Test results: 10/19/2009
// Serialize classes avg time: 60 ms
// Deserialized classes avg time: 70 ms
// Serialize exposed classes avg time: 159 ms
// Deserialized exposed classes avg time: 173 ms
@Test
@Ignore
public void testSerializeClasses() {
ClassWithList c = new ClassWithList("str");
for (int i = 0; i < COLLECTION_SIZE; ++i) {
c.list.add(new ClassWithField("element-" + i));
}
StringWriter w = new StringWriter();
long t1 = System.currentTimeMillis();
for (int i = 0; i < NUM_ITERATIONS; ++i) {
gson.toJson(c, w);
}
long t2 = System.currentTimeMillis();
long avg = (t2 - t1) / NUM_ITERATIONS;
System.out.printf("Serialize classes avg time: %d ms\n", avg);
}
@Test
@Ignore
public void testDeserializeClasses() {
String json = buildJsonForClassWithList();
ClassWithList[] target = new ClassWithList[NUM_ITERATIONS];
long t1 = System.currentTimeMillis();
for (int i = 0; i < NUM_ITERATIONS; ++i) {
target[i] = gson.fromJson(json, ClassWithList.class);
}
long t2 = System.currentTimeMillis();
long avg = (t2 - t1) / NUM_ITERATIONS;
System.out.printf("Deserialize classes avg time: %d ms\n", avg);
}
@Test
@Ignore
public void testLargeObjectSerializationAndDeserialization() {
Map<String, Long> largeObject = new HashMap<>();
for (long l = 0; l < 100000; l++) {
largeObject.put("field" + l, l);
}
long t1 = System.currentTimeMillis();
String json = gson.toJson(largeObject);
long t2 = System.currentTimeMillis();
System.out.printf("Large object serialized in: %d ms\n", (t2 - t1));
t1 = System.currentTimeMillis();
Map<String, Long> unused = gson.fromJson(json, new TypeToken<Map<String, Long>>() {}.getType());
t2 = System.currentTimeMillis();
System.out.printf("Large object deserialized in: %d ms\n", (t2 - t1));
}
@Test
@Ignore
public void testSerializeExposedClasses() {
ClassWithListOfObjects c1 = new ClassWithListOfObjects("str");
for (int i1 = 0; i1 < COLLECTION_SIZE; ++i1) {
c1.list.add(new ClassWithExposedField("element-" + i1));
}
ClassWithListOfObjects c = c1;
StringWriter w = new StringWriter();
long t1 = System.currentTimeMillis();
for (int i = 0; i < NUM_ITERATIONS; ++i) {
gson.toJson(c, w);
}
long t2 = System.currentTimeMillis();
long avg = (t2 - t1) / NUM_ITERATIONS;
System.out.printf("Serialize exposed classes avg time: %d ms\n", avg);
}
@Test
@Ignore
public void testDeserializeExposedClasses() {
String json = buildJsonForClassWithList();
ClassWithListOfObjects[] target = new ClassWithListOfObjects[NUM_ITERATIONS];
long t1 = System.currentTimeMillis();
for (int i = 0; i < NUM_ITERATIONS; ++i) {
target[i] = gson.fromJson(json, ClassWithListOfObjects.class);
}
long t2 = System.currentTimeMillis();
long avg = (t2 - t1) / NUM_ITERATIONS;
System.out.printf("Deserialize exposed classes avg time: %d ms\n", avg);
}
@Test
@Ignore
public void testLargeGsonMapRoundTrip() throws Exception {
Map<Long, Long> original = new HashMap<>();
for (long i = 0; i < 1000000; i++) {
original.put(i, i + 1);
}
Gson gson = new Gson();
String json = gson.toJson(original);
Type longToLong = new TypeToken<Map<Long, Long>>() {}.getType();
Map<Long, Long> unused = gson.fromJson(json, longToLong);
}
private static String buildJsonForClassWithList() {
StringBuilder sb = new StringBuilder("{");
sb.append("field:").append("'str',");
sb.append("list:[");
boolean first = true;
for (int i = 0; i < COLLECTION_SIZE; ++i) {
if (first) {
first = false;
} else {
sb.append(',');
}
sb.append("{field:'element-" + i + "'}");
}
sb.append(']');
sb.append('}');
String json = sb.toString();
return json;
}
@SuppressWarnings("unused")
private static final class ClassWithList {
final String field;
final List<ClassWithField> list = new ArrayList<>(COLLECTION_SIZE);
ClassWithList() {
this(null);
}
ClassWithList(String field) {
this.field = field;
}
}
@SuppressWarnings("unused")
private static final class ClassWithField {
final String field;
ClassWithField() {
this("");
}
public ClassWithField(String field) {
this.field = field;
}
}
@SuppressWarnings("unused")
private static final class ClassWithListOfObjects {
@Expose final String field;
@Expose final List<ClassWithExposedField> list = new ArrayList<>(COLLECTION_SIZE);
ClassWithListOfObjects() {
this(null);
}
ClassWithListOfObjects(String field) {
this.field = field;
}
}
@SuppressWarnings("unused")
private static final class ClassWithExposedField {
@Expose final String field;
ClassWithExposedField() {
this("");
}
ClassWithExposedField(String field) {
this.field = field;
}
}
}【Kotlin】Serialization Chapter 5. JSON Features
JSON 特性
這是 Kotlin 序列化指南的第五章。本章將介紹 Json 類別中可用的 JSON 序列化功能。
目錄
- JSON 配置
- 美化打印(Pretty Printing)
- 寬鬆解析(Lenient Parsing)
- 忽略未知鍵(Ignoring Unknown Keys)
- 替代的 JSON 名稱(Alternative Json Names)
- 編碼預設值(Encoding Defaults)
- 明確的
null(Explicit Nulls) - 強制輸入值(Coercing Input Values)
- 允許結構化的映射鍵(Allowing Structured Map Keys)
- 允許特殊的浮點值(Allowing Special Floating-Point Values)
- 用於多型性的類別區分符(Class Discriminator for Polymorphism)
- 類別區分符輸出模式(Class Discriminator Output Mode)
- 以不區分大小寫的方式解碼枚舉(Decoding Enums in a Case-Insensitive Manner)
- 全域命名策略(Global Naming Strategy)
- Base64
- JSON 元素
- 解析為 JSON 元素
- JSON 元素的類型
- JSON 元素建構器
- 解碼 JSON 元素
- 編碼字面值 JSON 內容(實驗性功能)
- 序列化大型十進制數字
- 使用
JsonUnquotedLiteral創建字面值不帶引號的null是被禁止的 - JSON 轉換
- 陣列包裝
- 陣列拆包
- 操作預設值
- 基於內容的多型性反序列化
- 底層實作(實驗性功能)
- 維護自定義的 JSON 屬性
JSON 配置
默認的 Json 實作對無效的輸入非常嚴格。它強制執行 Kotlin 的類型安全性,並限制可以序列化的 Kotlin 值,以確保生成的 JSON 表示是標準的。通過創建自定義的 JSON 格式實例,可以支持許多非標準的 JSON 功能。
要使用自定義 JSON 格式配置,可以從現有的 Json 實例(例如默認的 Json 對象)中使用 Json() 建構函數來創建自己的 Json 類別實例。在括號中通過 JsonBuilder DSL 指定參數值。生成的 Json 格式實例是不可變且線程安全的;可以簡單地將其存儲在頂層屬性中。
出於性能原因,建議你存儲和重複使用自定義的格式實例,因為格式實作可能會快取有關其序列化的類別的特定於格式的附加資訊。
本章介紹了 Json 支持的配置功能。
美化打印
默認情況下,Json 輸出是一行。你可以通過設置 prettyPrint 屬性為 true 來配置它以美化打印輸出(即添加縮排和換行以提高可讀性):
val format = Json { prettyPrint = true }
@Serializable
data class Project(val name: String, val language: String)
fun main() {
val data = Project("kotlinx.serialization", "Kotlin")
println(format.encodeToString(data))
}
這會給出如下優美的結果:
{
"name": "kotlinx.serialization",
"language": "Kotlin"
}
寬鬆解析
默認情況下,Json 解析器強制執行各種 JSON 限制,以盡可能符合規範(參見 RFC-4627)。特別是,鍵和字串文字必須加引號。這些限制可以通過設置 isLenient 屬性為 true 來放寬。當 isLenient = true 時,你可以解析格式相當自由的資料:
val format = Json { isLenient = true }
enum class Status { SUPPORTED }
@Serializable
data class Project(val name: String, val status: Status, val votes: Int)
fun main() {
val data = format.decodeFromString<Project>("""
{
name : kotlinx.serialization,
status : SUPPORTED,
votes : "9000"
}
""")
println(data)
}
即使源 JSON 的所有鍵、字串和枚舉值未加引號,而整數被加引號,仍然可以獲取對象:
Project(name=kotlinx.serialization, status=SUPPORTED, votes=9000)
忽略未知鍵
JSON 格式通常用於讀取第三方服務的輸出或其他動態環境中,在這些環境中,在 API 演進過程中可能會添加新屬性。默認情況下,反序列化期間遇到的未知鍵會產生錯誤。你可以通過設置 ignoreUnknownKeys 屬性為 true 來避免這種情況並僅忽略這些鍵:
val format = Json { ignoreUnknownKeys = true }
@Serializable
data class Project(val name: String)
fun main() {
val data = format.decodeFromString<Project>("""
{"name":"kotlinx.serialization","language":"Kotlin"}
""")
println(data)
}
即使 Project 類別沒有 language 屬性,它也會解碼對象:
Project(name=kotlinx.serialization)
替代的 JSON 名稱
當 JSON 字段因為模式版本更改而重新命名時,這並不罕見。你可以使用 @SerialName 註解來更改 JSON 字段的名稱,但這種重命名會阻止使用舊名稱解碼資料。為了支持一個 Kotlin 屬性具有多個 JSON 名稱,可以使用 @JsonNames 註解:
@Serializable
data class Project(@JsonNames("title") val name: String)
fun main() {
val project = Json.decodeFromString<Project>("""{"name":"kotlinx.serialization"}""")
println(project)
val oldProject = Json.decodeFromString<Project>("""{"title":"kotlinx.coroutines"}""")
println(oldProject)
}
如你所見,name 和 title JSON 字段都對應於 name 屬性:
Project(name=kotlinx.serialization)
Project(name=kotlinx.coroutines)
@JsonNames 註解的支持由 JsonBuilder.useAlternativeNames 標誌控制。與大多數配置標誌不同,這個是默認啟用的,不需要特別關注,除非你想進行一些微調。
編碼預設值
屬性的預設值默認不會被編碼,因為它們在解碼過程中缺失字段時會被賦值。詳情和範例參見 Defaults are not encoded 一節。這對於具有 null 預設值的可空屬性尤其有用,避免了編寫對應的 null 值。可以通過將 encodeDefaults 屬性設置為 true 來更改預設行為:
val format = Json { encodeDefaults = true }
@Serializable
class Project(
val name: String,
val language: String = "Kotlin",
val website: String? = null
)
fun main() {
val data = Project("kotlinx.serialization")
println(format.encodeToString(data))
}
這會生成以下輸出,編碼了所有屬性值,包括預設值:
{"name":"kotlinx.serialization","language":"Kotlin","website":null}
明確的 null
默認情況下,所有 null 值都被編碼為 JSON 字串,但在某些情況下,你可能希望省略它們。null 值的編碼可以通過 explicitNulls 屬性進行控制。
如果你將屬性設置為 false,即使屬性沒有預設 null 值,null 值的字段也不會編碼到 JSON 中。當解碼此類 JSON 時,對於沒有預設值的可空屬性,缺少屬性值會被視為 null。
val format = Json { explicitNulls = false }
@Serializable
data class Project(
val name: String,
val language: String,
val version: String? = "1.2.2",
val website: String?,
val description: String? = null
)
fun main() {
val data = Project("kotlinx.serialization", "Kotlin", null, null, null)
val json = format.encodeToString(data)
println(json)
println(format.decodeFromString<Project>(json))
}
如你所見,version、website 和 description 字段在第一行的輸出 JSON 中並不存在。解碼後,沒有預設值的可空屬性 website 獲得了 null 值,而可空屬性 version 和 description 則使用了其預設值:
{"name":"kotlinx.serialization","language":"Kotlin"}
Project(name=kotlinx.serialization, language=Kotlin, version=1.2.2, website=null, description=null)
注意,version 在編碼前是 null,而在解碼後變為 1.2.2。如果 explicitNulls 設置為 false,則這種屬性(可空但有非 null 預設值)的編碼/解碼變得不對稱。
如果想讓解碼器將某些無效的輸入資料視為缺少字段來增強此標誌的功能,請參閱 coerceInputValues 下面的詳細信息。
explicitNulls 默認為 true,因為這是不同版本庫中的默認行為。
強制輸入值
來自第三方的 JSON 格式可以演變,有時會改變字段類型。這可能會在解碼過程中導致異常,因為實際值與預期值不匹配。默認的 Json 實作對輸入類型非常嚴格,如在 Type safety is enforced 部分中所展示的。你可以通過 coerceInputValues 屬性來放寬此限制。
此屬性僅影響解碼。它將一小部分無效的輸入值視為相應屬性缺失。當前支持的無效值清單包括:
- 對於不可空類型的
null輸入 - 枚舉的未知值
如果缺少值,則會用預設屬性值(如果存在)替換,或者如果 explicitNulls 標誌設置為 false 且屬性為可空,則替換為 null(對於枚舉)。
此清單可能在未來擴展,因此配置此屬性的 Json 實例將對輸入中的無效值更加寬容,並用預設值或 null 進行替換。
參見 Type safety is enforced 部分的範例:
val format = Json { coerceInputValues = true }
@Serializable
data class Project(val name: String, val language: String = "Kotlin")
fun main() {
val data = format.decodeFromString<Project>("""
{"name":"kotlinx.serialization","language":null}
""")
println(data)
}
language 屬性的無效 null 值被強制轉換為預設值:
Project(name=kotlinx.serialization, language=Kotlin)
以下範例展示了如何與 explicitNulls 旗標一起使用以強制無效的枚舉值:
enum class Color { BLACK, WHITE }
@Serializable
data class Brush(val foreground: Color = Color.BLACK, val background: Color?)
val json = Json {
coerceInputValues = true
explicitNulls = false
}
fun main() {
val brush = json.decodeFromString<Brush>("""{"foreground":"pink", "background":"purple"}""")
println(brush)
}
即使我們沒有 Color.pink 和 Color.purple 顏色,decodeFromString 函數仍成功返回:
Brush(foreground=BLACK, background=null)
foreground 屬性獲得了其預設值,而 background 屬性由於 explicitNulls = false 設置而獲得了 null。
允許結構化的映射鍵
JSON 格式本質上不支持具有結構化鍵的映射(Map)的概念。JSON 對象中的鍵是字串,並且默認只能用於表示基本類型或枚舉。你可以通過設置 allowStructuredMapKeys 屬性來啟用對結構化鍵的非標準支持。
以下是如何序列化具有使用者定義類別鍵的映射:
val format = Json { allowStructuredMapKeys = true }
@Serializable
data class Project(val name: String)
fun main() {
val map = mapOf(
Project("kotlinx.serialization") to "Serialization",
Project("kotlinx.coroutines") to "Coroutines"
)
println(format.encodeToString(map))
}
使用結構化鍵的映射被表示為 JSON 陣列,並包含以下項目:[key1, value1, key2, value2,...]。
[{"name":"kotlinx.serialization"},"Serialization",{"name":"kotlinx.coroutines"},"Coroutines"]
允許特殊的浮點值
默認情況下,由於 JSON 規範禁止,特殊的浮點值如 Double.NaN 和無限大在 JSON 中不受支持。你可以通過 allowSpecialFloatingPointValues 屬性來啟用它們的編碼:
val format = Json { allowSpecialFloatingPointValues = true }
@Serializable
class Data(
val value: Double
)
fun main() {
val data = Data(Double.NaN)
println(format.encodeToString(data))
}
此範例生成以下非標準 JSON 輸出,但這在 JVM 世界中是一種廣泛使用的編碼方式:
{"value":NaN}
用於多型性的類別區分符
當你有多型性資料時,可以在 classDiscriminator 屬性中指定一個鍵名稱來指定類型:
val format = Json { classDiscriminator = "#class" }
@Serializable
sealed class Project {
abstract val name: String
}
@Serializable
@SerialName("owned")
class OwnedProject(override val name: String, val owner: String) : Project()
fun main() {
val data: Project = OwnedProject("kotlinx.coroutines", "kotlin")
println(format.encodeToString(data))
}
結合明確指定的類別 SerialName,你可以完全控制生成的 JSON 對象:
{"#class":"owned","name":"kotlinx.coroutines","owner":"kotlin"}
還可以為不同的繼承層次結構指定不同的類別區分符。可以在基礎可序列化類別上直接使用 @JsonClassDiscriminator 註解,而不是 Json 實例屬性:
@Serializable
@JsonClassDiscriminator("message_type")
sealed class Base
此註解是可繼承的,因此 Base 的所有子類別都將具有相同的區分符:
@Serializable // Class discriminator is inherited from Base
sealed class ErrorClass: Base()
要了解有關可繼承序列化註解的更多資訊,請參見 InheritableSerialInfo 的文檔。
請注意,無法在 Base 子類中明確指定不同的類別區分符。只有交集為空的繼承層次結構才能具有不同的區分符。
註解中指定的區分符優先於 Json 配置中的區分符:
val format = Json { classDiscriminator = "#class" }
fun main() {
val data = Message(BaseMessage("not found"), GenericError(404))
println(format.encodeToString(data))
}
如你所見,使用了 Base 類別的區分符:
{"message":{"message_type":"my.app.BaseMessage","message":"not found"},"error":{"message_type":"my.app.GenericError","error_code":404}}
類別區分符輸出模式
類別區分符為序列化和反序列化多型性類別層次結構提供了資訊。如上所示,它默認僅添加於多型性類別。當你希望為各種第三方 API 編碼更多或更少的輸出類型資訊時,可以通過 JsonBuilder.classDiscriminatorMode 屬性來控制類別區分符的添加。
例如,ClassDiscriminatorMode.NONE 不會添加類別區分符,這適用於接收方不關心 Kotlin 類型的情況:
val format = Json { classDiscriminatorMode = ClassDiscriminatorMode.NONE }
@Serializable
sealed class Project {
abstract val name: String
}
@Serializable
class OwnedProject(override val name: String, val owner: String) : Project()
fun main() {
val data: Project = OwnedProject("kotlinx.coroutines", "kotlin")
println(format.encodeToString(data))
}
請注意,無法使用 kotlinx.serialization
將此輸出反序列化回去。
{"name":"kotlinx.coroutines","owner":"kotlin"}
另外兩個可用的值是 ClassDiscriminatorMode.POLYMORPHIC(默認行為)和 ClassDiscriminatorMode.ALL_JSON_OBJECTS(盡可能地添加區分符)。有關詳細信息,請參閱其文檔。
以不區分大小寫的方式解碼枚舉
Kotlin 的命名策略建議使用大寫下劃線分隔名稱或駝峰式名稱來命名枚舉值。Json 默認使用確切的 Kotlin 枚舉值名稱進行解碼。但是,有時候第三方 JSON 中的這些值是小寫的或混合大小寫的。在這種情況下,可以使用 JsonBuilder.decodeEnumsCaseInsensitive 屬性以不區分大小寫的方式解碼枚舉值:
val format = Json { decodeEnumsCaseInsensitive = true }
enum class Cases { VALUE_A, @JsonNames("Alternative") VALUE_B }
@Serializable
data class CasesList(val cases: List<Cases>)
fun main() {
println(format.decodeFromString<CasesList>("""{"cases":["value_A", "alternative"]}"""))
}
這會影響序列名稱以及使用 JsonNames 註解指定的替代名稱,因此這兩個值都會成功解碼:
CasesList(cases=[VALUE_A, VALUE_B])
此屬性不會以任何方式影響編碼。
全域命名策略
如果 JSON 輸入中的屬性名稱與 Kotlin 不同,建議使用 @SerialName 註解顯式指定每個屬性的名稱。但是,有些情況下需要將轉換應用於每個序列名稱,例如從其他框架遷移或遺留代碼庫。在這些情況下,可以為 Json 實例指定 namingStrategy。kotlinx.serialization 提供了一種現成的策略實作,即 JsonNamingStrategy.SnakeCase:
@Serializable
data class Project(val projectName: String, val projectOwner: String)
val format = Json { namingStrategy = JsonNamingStrategy.SnakeCase }
fun main() {
val project = format.decodeFromString<Project>("""{"project_name":"kotlinx.coroutines", "project_owner":"Kotlin"}""")
println(format.encodeToString(project.copy(projectName = "kotlinx.serialization")))
}
如你所見,序列化和反序列化都如同所有序列名稱都從駝峰式轉換為蛇形:
{"project_name":"kotlinx.serialization","project_owner":"Kotlin"}
在處理 JsonNamingStrategy 時需要注意一些限制:
由於 kotlinx.serialization 框架的性質,命名策略轉換應用於所有屬性,不論其序列名稱是取自屬性名稱還是通過 @SerialName 註解提供。實際上,這意味著無法通過顯式指定序列名稱來避免轉換。要能夠反序列化未轉換的名稱,可以使用 JsonNames 註解。
轉換後的名稱與其他(轉換後的)屬性序列名稱或使用 JsonNames 指定的任何替代名稱發生衝突將導致反序列化異常。
全域命名策略非常隱晦:僅從類別定義無法確定其在序列化形式中的名稱。因此,命名策略對於 IDE 中的 Find Usages/Rename 操作、grep 全文搜索等操作來說不友好。對於它們而言,原始名稱和轉換後的名稱是兩個不同的東西;更改一個而不更改另一個可能會以多種意想不到的方式引入錯誤,並導致更大的代碼維護成本。
因此,在考慮向應用程序中添加全域命名策略之前,應仔細權衡利弊。
Base64
要編碼和解碼 Base64 格式,我們需要手動編寫一個序列化器。在這裡,我們將使用 Kotlin 的默認 Base64 編碼器實作。請注意,某些序列化器默認使用不同的 RFC 進行 Base64 編碼。例如,Jackson 默認使用 Base64 Mime 的變體。在 kotlinx.serialization 中可以使用 Base64.Mime 編碼器來實現相同的結果。Kotlin 的 Base64 文檔列出了其他可用的編碼器。
import kotlinx.serialization.encoding.Encoder
import kotlinx.serialization.encoding.Decoder
import kotlinx.serialization.descriptors.*
import kotlin.io.encoding.*
@OptIn(ExperimentalEncodingApi::class)
object ByteArrayAsBase64Serializer : KSerializer<ByteArray> {
private val base64 = Base64.Default
override val descriptor: SerialDescriptor
get() = PrimitiveSerialDescriptor(
"ByteArrayAsBase64Serializer",
PrimitiveKind.STRING
)
override fun serialize(encoder: Encoder, value: ByteArray) {
val base64Encoded = base64.encode(value)
encoder.encodeString(base64Encoded)
}
override fun deserialize(decoder: Decoder): ByteArray {
val base64Decoded = decoder.decodeString()
return base64.decode(base64Decoded)
}
}
有關如何創建自己的自定義序列化器的詳細信息,請參見 custom serializers。
然後我們可以像這樣使用它:
@Serializable
data class Value(
@Serializable(with = ByteArrayAsBase64Serializer::class)
val base64Input: ByteArray
) {
override fun equals(other: Any?): Boolean {
if (this === other) return true
if (javaClass != other?.javaClass) return false
other as Value
return base64Input.contentEquals(other.base64Input)
}
override fun hashCode(): Int {
return base64Input.contentHashCode()
}
}
fun main() {
val string = "foo string"
val value = Value(string.toByteArray())
val encoded = Json.encodeToString(value)
println(encoded)
val decoded = Json.decodeFromString<Value>(encoded)
println(decoded.base64Input.decodeToString())
}
{"base64Input":"Zm9vIHN0cmluZw=="}
foo string
注意,我們編寫的序列化器並不依賴於 Json 格式,因此它可以在任何格式中使用。
對於在許多地方使用此序列化器的專案,可以通過使用 typealias 全域性地指定序列化器,以避免每次都指定序列化器。例如:
typealias Base64ByteArray = @Serializable(ByteArrayAsBase64Serializer::class) ByteArray
JSON 元素
除了字串與 JSON 對象之間的直接轉換外,Kotlin 序列化還提供了允許其他方式處理 JSON 的 API。例如,你可能需要在解析之前調整資料,或處理不容易適合 Kotlin 序列化的類型安全世界的非結構化資料。
此部分庫中的主要概念是 JsonElement。繼續閱讀以了解你可以用它做什麼。
解析為 JSON 元素
可以使用 Json.parseToJsonElement 函數將字串解析為 JsonElement 實例。這不叫解碼也不叫反序列化,因為在此過程中不會發生這些操作。它只是解析 JSON 並形成表示它的對象:
fun main() {
val element = Json.parseToJsonElement("""
{"name":"kotlinx.serialization","language":"Kotlin"}
""")
println(element)
}
{"name":"kotlinx.serialization","language":"Kotlin"}
JSON 元素的類型
JsonElement 類別有三個直接子類型,與 JSON 語法密切相關:
-
JsonPrimitive代表基本 JSON 元素,例如字串、數字、布林值和null。每個基本元素都有一個簡單的字串內容。還有一個JsonPrimitive()構造函數,重載以接受各種基本 Kotlin 類型並將它們轉換為JsonPrimitive。 -
JsonArray代表 JSON [...] 陣列。它是 Kotlin 列表,包含JsonElement項目。 -
JsonObject代表 JSON {...} 對象。它是從字串鍵到JsonElement值的 Kotlin 映射。
JsonElement 類別有擴展函數,將其轉換為相應的子類型:jsonPrimitive、jsonArray、jsonObject。JsonPrimitive 類別依次提供轉換為 Kotlin 基本類型的轉換器:int、intOrNull、long、longOrNull,以及其他類型的類似轉換
器。你可以使用它們來處理已知結構的 JSON:
fun main() {
val element = Json.parseToJsonElement("""
{
"name": "kotlinx.serialization",
"forks": [{"votes": 42}, {"votes": 9000}, {}]
}
""")
val sum = element
.jsonObject["forks"]!!
.jsonArray.sumOf { it.jsonObject["votes"]?.jsonPrimitive?.int ?: 0 }
println(sum)
}
上面的範例會對 forks 陣列中所有對象的 votes 進行求和,忽略沒有 votes 的對象:
9042
請注意,如果資料的結構與預期不同,執行將會失敗。
JSON 元素建構器
你可以使用相應的建構器函數 buildJsonArray 和 buildJsonObject 構建 JsonElement 子類型的實例。它們提供了一種 DSL 來定義生成的 JSON 結構。這類似於 Kotlin 標準庫集合建構器,但具有 JSON 特定的便利功能,例如更多類型特定的重載和內部建構器函數。以下範例顯示了所有關鍵功能:
fun main() {
val element = buildJsonObject {
put("name", "kotlinx.serialization")
putJsonObject("owner") {
put("name", "kotlin")
}
putJsonArray("forks") {
addJsonObject {
put("votes", 42)
}
addJsonObject {
put("votes", 9000)
}
}
}
println(element)
}
{"name":"kotlinx.serialization","owner":{"name":"kotlin"},"forks":[{"votes":42},{"votes":9000}]}
解碼 JSON 元素
JsonElement 類別的實例可以使用 Json.decodeFromJsonElement 函數解碼為可序列化對象:
@Serializable
data class Project(val name: String, val language: String)
fun main() {
val element = buildJsonObject {
put("name", "kotlinx.serialization")
put("language", "Kotlin")
}
val data = Json.decodeFromJsonElement<Project>(element)
println(data)
}
結果完全符合預期:
Project(name=kotlinx.serialization, language=Kotlin)
編碼字面值 JSON 內容(實驗性功能)
此功能是實驗性的,需要選擇加入 Kotlinx Serialization API。
在某些情況下,可能需要編碼任意未加引號的值。這可以通過 JsonUnquotedLiteral 實現。
序列化大型十進制數字
JSON 規範對數字的大小或精度沒有限制,但是無法使用 JsonPrimitive() 序列化任意大小或精度的數字。
如果使用 Double,則數字的精度受到限制,這意味著大數字會被截斷。在使用 Kotlin/JVM 時,可以改用 BigDecimal,但 JsonPrimitive() 將值編碼為字串,而不是數字。
import java.math.BigDecimal
val format = Json { prettyPrint = true }
fun main() {
val pi = BigDecimal("3.141592653589793238462643383279")
val piJsonDouble = JsonPrimitive(pi.toDouble())
val piJsonString = JsonPrimitive(pi.toString())
val piObject = buildJsonObject {
put("pi_double", piJsonDouble)
put("pi_string", piJsonString)
}
println(format.encodeToString(piObject))
}
儘管 pi 被定義為具有 30 位小數的數字,但生成的 JSON 並未反映這一點。Double 值被截斷為 15 位小數,而 String 被包裹在引號中,這不是 JSON 數字。
{
"pi_double": 3.141592653589793,
"pi_string": "3.141592653589793238462643383279"
}
為了避免精度損失,可以使用 JsonUnquotedLiteral 編碼 pi 的字串值。
import java.math.BigDecimal
val format = Json { prettyPrint = true }
fun main() {
val pi = BigDecimal("3.141592653589793238462643383279")
// 使用 JsonUnquotedLiteral 編碼原始 JSON 內容
val piJsonLiteral = JsonUnquotedLiteral(pi.toString())
val piJsonDouble = JsonPrimitive(pi.toDouble())
val piJsonString = JsonPrimitive(pi.toString())
val piObject = buildJsonObject {
put("pi_literal", piJsonLiteral)
put("pi_double", piJsonDouble)
put("pi_string", piJsonString)
}
println(format.encodeToString(piObject))
}
pi_literal 現在準確地匹配定義的值。
{
"pi_literal": 3.141592653589793238462643383279,
"pi_double": 3.141592653589793,
"pi_string": "3.141592653589793238462643383279"
}
要將 pi 解碼回 BigDecimal,可以使用 JsonPrimitive 的字串內容。
(此演示使用 JsonPrimitive 為了簡便。要獲得更可重用的處理序列化的方法,請參見 Json Transformations 下面的部分。)
import java.math.BigDecimal
fun main() {
val piObjectJson = """
{
"pi_literal": 3.141592653589793238462643383279
}
""".trimIndent()
val piObject: JsonObject = Json.decodeFromString(piObjectJson)
val piJsonLiteral = piObject["pi_literal"]!!.jsonPrimitive.content
val pi = BigDecimal(piJsonLiteral)
println(pi)
}
3.141592653589793238462643383279
使用 JsonUnquotedLiteral 創建字面值不帶引號的 null 是被禁止的
為了避免創建不一致的狀態,編碼等於 "null" 的字串是被禁止的。請改用 JsonNull 或 JsonPrimitive。
fun main() {
// 注意:使用 JsonUnquotedLiteral 創建 null 將導致異常!
JsonUnquotedLiteral("null")
}
Exception in thread "main" kotlinx.serialization.json.internal.JsonEncodingException: Creating a literal unquoted value of 'null' is forbidden. If you want to create JSON null literal, use JsonNull object, otherwise, use JsonPrimitive
JSON 轉換
要影響序列化後的 JSON 輸出的形狀和內容,或適應反序列化的輸入,可以編寫自定義序列化器。但是,特別是對於相對較小且簡單的任務來說,仔細遵循 Encoder 和 Decoder 調用約定可能很不方便。為此,Kotlin 序列化提供了 API,可以將實作自定義序列化器的負擔減輕為操作 JSON 元素樹的問題。
我們建議你熟悉 Serializers 章節:其中解釋了如何將自定義序列化器綁定到類別。
轉換功能由 JsonTransformingSerializer 抽象類別提供,它實作了 KSerializer。此類別不直接與 Encoder 或 Decoder 交互,而是要求你通過 transformSerialize 和 transformDeserialize 方法為表示為 JsonElement 類別的 JSON 樹提供轉換。我們來看看範例。
陣列包裝
第一個範例是為列表實作 JSON 陣列包裝。
考慮一個 REST API,它返回一個 User 對象的 JSON 陣列,如果結果中只有一個元素,則返回單個對象(未包裝到陣列中)。
在資料模型中,使用 @Serializable 註解指定 users: List<User> 屬性使用自定義序列化器。
@Serializable
data class Project(
val name: String,
@Serializable(with = UserListSerializer::class)
val users: List<User>
)
@Serializable
data class User(val name: String)
由於此範例僅涵蓋反序列化情況,因此你可以實作 UserListSerializer 並僅重寫 transformDeserialize 函數。JsonTransformingSerializer 構造函數將原始序列化器作為參數(此方法在 Constructing collection serializers 部分中顯示):
object UserListSerializer : JsonTransforming
Serializer<List<User>>(ListSerializer(User.serializer())) {
// 如果響應不是一個陣列,那麼它是一個應該被包裝到陣列中的單個對象
override fun transformDeserialize(element: JsonElement): JsonElement =
if (element !is JsonArray) JsonArray(listOf(element)) else element
}
現在你可以用 JSON 陣列或單個 JSON 對象作為輸入來測試代碼。
fun main() {
println(Json.decodeFromString<Project>("""
{"name":"kotlinx.serialization","users":{"name":"kotlin"}}
"""))
println(Json.decodeFromString<Project>("""
{"name":"kotlinx.serialization","users":[{"name":"kotlin"},{"name":"jetbrains"}]}
"""))
}
輸出顯示了兩種情況都正確地反序列化為 Kotlin 列表。
Project(name=kotlinx.serialization, users=[User(name=kotlin)])
Project(name=kotlinx.serialization, users=[User(name=kotlin), User(name=jetbrains)])
陣列拆包
你還可以實作 transformSerialize 函數,在序列化期間將單個元素列表拆包為單個 JSON 對象:
override fun transformSerialize(element: JsonElement): JsonElement {
require(element is JsonArray) // 此序列化器僅用於列表
return element.singleOrNull() ?: element
}
現在,如果你從 Kotlin 序列化單個元素列表對象:
fun main() {
val data = Project("kotlinx.serialization", listOf(User("kotlin")))
println(Json.encodeToString(data))
}
你最終會得到一個單個 JSON 對象,而不是一個包含一個元素的陣列:
{"name":"kotlinx.serialization","users":{"name":"kotlin"}}
操作預設值
另一種有用的轉換是從輸出 JSON 中省略特定值,例如,如果它被用作缺少時的預設值或出於其他原因。
假設你由於某些原因無法為 Project 資料模型中的 language 屬性指定預設值,但你需要在它等於 Kotlin 時將其從 JSON 中省略(我們都同意 Kotlin 應該是預設值)。你可以通過基於 Project 類別的 Plugin 生成的序列化器來編寫特別的 ProjectSerializer。
@Serializable
class Project(val name: String, val language: String)
object ProjectSerializer : JsonTransformingSerializer<Project>(Project.serializer()) {
override fun transformSerialize(element: JsonElement): JsonElement =
// 過濾掉鍵為 "language" 且值為 "Kotlin" 的頂層鍵值對
JsonObject(element.jsonObject.filterNot {
(k, v) -> k == "language" && v.jsonPrimitive.content == "Kotlin"
})
}
在下面的範例中,我們在頂層序列化 Project 類別,因此我們如 Passing a serializer manually 部分中所示,顯式將上述 ProjectSerializer 傳遞給 Json.encodeToString 函數:
fun main() {
val data = Project("kotlinx.serialization", "Kotlin")
println(Json.encodeToString(data)) // 使用插件生成的序列化器
println(Json.encodeToString(ProjectSerializer, data)) // 使用自定義序列化器
}
查看自定義序列化器的效果:
{"name":"kotlinx.serialization","language":"Kotlin"}
{"name":"kotlinx.serialization"}
基於內容的多型性反序列化
通常,多型性序列化需要在輸入的 JSON 對象中有一個專用的 "type" 鍵(也稱為類別區分符)來確定應該使用的實際序列化器來反序列化 Kotlin 類別。
但是,有時候輸入中可能沒有類型屬性。在這種情況下,你需要通過 JSON 的形狀來猜測實際類型,例如通過某個特定鍵的存在。
JsonContentPolymorphicSerializer 提供了此類策略的骨架實作。要使用它,請重寫其 selectDeserializer 方法。我們先從以下類別繼承層次結構開始。
請注意,這不必像在 Sealed classes 部分中推薦的那樣是密封的,因為我們不打算利用自動選擇相應子類別的插件生成代碼,而是打算手動實作此代碼。
@Serializable
abstract class Project {
abstract val name: String
}
@Serializable
data class BasicProject(override val name: String): Project()
@Serializable
data class OwnedProject(override val name: String, val owner: String) : Project()
你可以通過 JSON 對象中是否存在 owner 鍵來區分 BasicProject 和 OwnedProject 子類。
object ProjectSerializer : JsonContentPolymorphicSerializer<Project>(Project::class) {
override fun selectDeserializer(element: JsonElement) = when {
"owner" in element.jsonObject -> OwnedProject.serializer()
else -> BasicProject.serializer()
}
}
當你使用此序列化器來序列化資料時,會在運行時為實際類型選擇已註冊的或預設的序列化器:
fun main() {
val data = listOf(
OwnedProject("kotlinx.serialization", "kotlin"),
BasicProject("example")
)
val string = Json.encodeToString(ListSerializer(ProjectSerializer), data)
println(string)
println(Json.decodeFromString(ListSerializer(ProjectSerializer), string))
}
在 JSON 輸出中不會添加類別區分符:
[{"name":"kotlinx.serialization","owner":"kotlin"},{"name":"example"}]
[OwnedProject(name=kotlinx.serialization, owner=kotlin), BasicProject(name=example)]
底層實作(實驗性功能)
儘管上述抽象序列化器可以涵蓋大多數情況,但可以僅使用 KSerializer 類別手動實作類似的機制。如果修改 transformSerialize/transformDeserialize/selectDeserializer 抽象方法還不夠,那麼可以更改 serialize/deserialize 方法。
以下是一些有關使用 Json 的自定義序列化器的有用信息:
- 如果當前格式是
Json,則可以將Encoder和Decoder分別轉換為JsonEncoder和JsonDecoder。 JsonDecoder有decodeJsonElement方法,而JsonEncoder有encodeJsonElement方法,這些方法基本上將元素從流中的當前位置檢索或插入元素。JsonDecoder和JsonEncoder都有json屬性,它返回當前使用的Json實例及其所有設置。Json有encodeToJsonElement和decodeFromJsonElement方法。
有了這些,就可以實作兩階段轉換 Decoder -> JsonElement -> value 或 value -> JsonElement -> Encoder。例如,你可以為以下 Response 類別實作完全自定義的序列化器,這樣它的 Ok 子類可以直接表示,而 Error 子類則通過帶有錯誤訊息的對象表示:
@Serializable(with = ResponseSerializer::class)
sealed class Response<out T> {
data class Ok<out T>(val data: T) : Response<T>()
data class Error(val message: String) : Response<Nothing>()
}
class ResponseSerializer<T>(private val dataSerializer: KSerializer<T>) : KSerializer<Response<T>> {
override val descriptor: SerialDescriptor = buildSerialDescriptor("Response", PolymorphicKind.SEALED) {
element("Ok", dataSerializer.descriptor)
element("Error", buildClassSerialDescriptor("Error") {
element<String>("message")
})
}
override fun deserialize(decoder: Decoder): Response<T> {
// Decoder -> JsonDecoder
require(decoder is JsonDecoder) // 此類別只能由 JSON 解碼
// JsonDecoder -> JsonElement
val element = decoder.decodeJsonElement()
// JsonElement -> value
if (element is JsonObject && "error" in element)
return Response.Error(element["error"]!!.jsonPrimitive.content)
return Response.Ok(decoder.json.decodeFromJsonElement(dataSerializer, element))
}
override fun serialize(encoder: Encoder, value: Response<T>) {
// Encoder -> JsonEncoder
require(encoder is JsonEncoder) // 此類別只能由 JSON 編碼
// value -> JsonElement
val element = when (value) {
is Response.Ok -> encoder.json.encodeToJsonElement(dataSerializer, value.data)
is
Response.Error -> buildJsonObject { put("error", value.message) }
}
// JsonElement -> JsonEncoder
encoder.encodeJsonElement(element)
}
}
有了這個可序列化的 Response 實作,你可以為其資料使用任何可序列化的有效載荷,並序列化或反序列化相應的響應:
@Serializable
data class Project(val name: String)
fun main() {
val responses = listOf(
Response.Ok(Project("kotlinx.serialization")),
Response.Error("Not found")
)
val string = Json.encodeToString(responses)
println(string)
println(Json.decodeFromString<List<Response<Project>>>(string))
}
這樣可以精細地控制 Response 類別在 JSON 輸出中的表示形式:
[{"name":"kotlinx.serialization"},{"error":"Not found"}]
[Ok(data=Project(name=kotlinx.serialization)), Error(message=Not found)]
維護自定義的 JSON 屬性
一個很好的自定義 JSON 特定序列化器範例是一個解包所有未知 JSON 屬性到 JsonObject 類別的專用字段中的反序列化器。
讓我們添加 UnknownProject – 一個具有 name 屬性和任意細節的類別,將它們展平到相同的對象中:
data class UnknownProject(val name: String, val details: JsonObject)
但是,默認的插件生成的序列化器要求 details 是一個單獨的 JSON 對象,而這不是我們想要的。
為了緩解這個問題,編寫一個自己的序列化器,它使用事實來處理 JSON 格式:
object UnknownProjectSerializer : KSerializer<UnknownProject> {
override val descriptor: SerialDescriptor = buildClassSerialDescriptor("UnknownProject") {
element<String>("name")
element<JsonElement>("details")
}
override fun deserialize(decoder: Decoder): UnknownProject {
// 轉換為特定於 JSON 的介面
val jsonInput = decoder as? JsonDecoder ?: error("Can be deserialized only by JSON")
// 將整個內容讀取為 JSON
val json = jsonInput.decodeJsonElement().jsonObject
// 提取並移除名稱屬性
val name = json.getValue("name").jsonPrimitive.content
val details = json.toMutableMap()
details.remove("name")
return UnknownProject(name, JsonObject(details))
}
override fun serialize(encoder: Encoder, value: UnknownProject) {
error("Serialization is not supported")
}
}
現在可以用來讀取展平的 JSON 詳細資料作為 UnknownProject:
fun main() {
println(Json.decodeFromString(UnknownProjectSerializer, """{"type":"unknown","name":"example","maintainer":"Unknown","license":"Apache 2.0"}"""))
}
UnknownProject(name=example, details={"type":"unknown","maintainer":"Unknown","license":"Apache 2.0"})
下一章將涵蓋替代和自定義格式(實驗性功能)。
【kotlin】Serialization
Basic
要將物件樹轉換成字串或位元組序列,必須經過兩個相互交織的過程。
第一步是序列化——將物件轉換成其組成的基本值的序列。這個過程對所有資料格式來說都是
共通的,結果取決於被序列化的物件。序列化的過程由序列化器控制。
第二步稱為編碼——這是將相應的基本值序列轉換成輸出格式表示的過程。編碼器控制這個過程。當區分不那麼重要時,編碼和序列化這兩個術語可以互換使用。
+---------+ 序列化 +------------+ 編碼 +---------------+ | 物件 | ------------> | 基本值 | ---------> | 輸出格式 | +---------+ +------------+ +---------------+
+---------+ Serialization +------------+ Encoding +---------------+
| Objects | --------------> | Primitives | ---------> | Output format |
+---------+ +------------+ +---------------+反向過程從解析輸入格式並解碼基本值開始,隨後將得到的流反序列化為物件。我們稍後會詳細探討這個過程。
現在,我們從 JSON 編碼開始。
JSON 編碼
將資料轉換成特定格式的整個過程稱為編碼。對於 JSON,我們使用 Json.encodeToString 擴展函數來編碼資料。它在底層將傳遞給它的物件序列化並編碼為 JSON 字串。
讓我們從描述專案的一個類別開始,並嘗試獲得其 JSON 表示。
class Project(val name: String, val language: String)
fun main() {
val data = Project("kotlinx.serialization", "Kotlin")
println(Json.encodeToString(data))
}
執行這段程式碼時,我們會得到一個例外。
Exception in thread "main" kotlinx.serialization.SerializationException: Serializer for class 'Project' is not found.
Please ensure that class is marked as '@Serializable' and that the serialization compiler plugin is applied.
可序列化的類別必須顯式標記。Kotlin Serialization 不使用反射,因此您無法意外反序列化不應該可序列化的類別。我們通過添加 @Serializable 註解來修正它。
@Serializable
class Project(val name: String, val language: String)
fun main() {
val data = Project("kotlinx.serialization", "Kotlin")
println(Json.encodeToString(data))
}
這樣,我們將會得到相應的 JSON 輸出。
{"name":"kotlinx.serialization","language":"Kotlin"}
JSON 解碼
反向過程稱為解碼。要將 JSON 字串解碼為物件,我們將使用 Json.decodeFromString 擴展函數。為了指定我們想要獲得的結果類型,我們將類型參數提供給這個函數。
如我們稍後所見,序列化可以處理不同種類的類別。這裡我們將 Project 類別標記為 data class,這不是因為它是必需的,而是因為我們想要打印其內容以驗證它是如何解碼的。
@Serializable
data class Project(val name: String, val language: String)
fun main() {
val data = Json.decodeFromString<Project>("""
{"name":"kotlinx.serialization","language":"Kotlin"}
""")
println(data)
}
執行這段程式碼後,我們會得到物件:
Project(name=kotlinx.serialization, language=Kotlin)
可序列化的類別
這部分將更詳細地說明如何處理不同的 @Serializable 類別。
序列化備援屬性
只有具有備援欄位的類別屬性會被序列化,因此沒有備援欄位的 getter/setter 屬性和委託屬性將不會被序列化,如以下範例所示。
@Serializable
class Project(
var name: String // name 是具有備援欄位的屬性——會被序列化
) {
var stars: Int = 0 // 具有備援欄位的屬性——會被序列化
val path: String // 僅有 getter,沒有備援欄位——不會被序列化
get() = "kotlin/$name"
var id by ::name // 委託屬性——不會被序列化
}
fun main() {
val data = Project("kotlinx.serialization").apply { stars = 9000 }
println(Json.encodeToString(data))
}
我們可以清楚地看到,只有 name 和 stars 屬性出現在 JSON 輸出中。
{"name":"kotlinx.serialization","stars":9000}
建構子屬性要求
如果我們想要定義一個 Project 類別,並讓它接受一個路徑字串,然後將其分解為相應的屬性,我們可能會傾向於寫出如下代碼。
@Serializable
class Project(path: String) {
val owner: String = path.substringBefore('/')
val name: String = path.substringAfter('/')
}
這個類別無法編譯,因為 @Serializable 註解要求類別主要建構子的所有參數必須是屬性。一個簡單的解決方案是定義一個具有屬性的私有主要建構子,並將我們想要的建構子變成次要建構子。
@Serializable
class Project private constructor(val owner: String, val name: String) {
constructor(path: String) : this(
owner = path.substringBefore('/'),
name = path.substringAfter('/')
)
val path: String
get() = "$owner/$name"
}
序列化在具有私有主要建構子的情況下仍然能夠正常工作,並且仍然只會序列化備援欄位。
fun main() {
println(Json.encodeToString(Project("kotlin/kotlinx.serialization")))
}
這個範例會產生預期的輸出。
{"owner":"kotlin","name":"kotlinx.serialization"}
資料驗證
當你希望在將值存儲到屬性之前進行驗證時,可能會想在主要建構子參數中引入一個沒有屬性的參數。為了使其可序列化,你應該將其替換為主要建構子中的屬性,並將驗證移至 init { ... } 區塊。
@Serializable
class Project(val name: String) {
init {
require(name.isNotEmpty()) { "name 不能為空" }
}
}
反序列化過程與 Kotlin 中的常規建構子一樣,會調用所有的 init 區塊,確保你無法通過反序列化獲得一個無效的類別。讓我們試試看。
fun main() {
val data = Json.decodeFromString<Project>("""
{"name":""}
""")
println(data)
}
執行這段程式碼會產生一個例外:
Exception in thread "main" java.lang.IllegalArgumentException: name 不能為空
選擇性屬性
只有當輸入中存在所有屬性時,物件才能被反序列化。例如,執行以下程式碼。
@Serializable
data class Project(val name: String, val language: String)
fun main() {
val data = Json.decodeFromString<Project>("""
{"name":"kotlinx.serialization"}
""")
println(data)
}
這會產生一個例外:
Exception in thread "main" kotlinx.serialization.MissingFieldException: Field 'language' is required for type with serial name 'example.exampleClasses04.Project', but it was missing at path: $
這個問題可以通過為屬性添加一個默認值來解決,這會自動使其在序列化中成為選擇性屬性。
@Serializable
data class Project(val name: String, val language: String = "Kotlin")
fun main() {
val data = Json.decodeFromString<Project>("""
{"name":"kotlinx.serialization"}
""")
println(data)
}
這會產生以下輸出,其中 language 屬性使用默認值。
Project(name=kotlinx.serialization, language=Kotlin)
選擇性屬性初始化呼叫
當選擇性屬性存在於輸入中時,對應屬性的初始化器
甚至不會被調用。這是一個為了性能而設計的特性,所以要小心不要依賴於初始化器中的副作用。考慮以下範例。
fun computeLanguage(): String {
println("計算中")
return "Kotlin"
}
@Serializable
data class Project(val name: String, val language: String = computeLanguage())
fun main() {
val data = Json.decodeFromString<Project>("""
{"name":"kotlinx.serialization","language":"Kotlin"}
""")
println(data)
}
由於輸入中指定了 language 屬性,因此我們不會看到 "計算中" 的字串被打印出來。
Project(name=kotlinx.serialization, language=Kotlin)
必須的屬性
具有默認值的屬性可以通過 @Required 註解在序列格式中設置為必須的。我們將上一個範例的 language 屬性標記為 @Required。
@Serializable
data class Project(val name: String, @Required val language: String = "Kotlin")
fun main() {
val data = Json.decodeFromString<Project>("""
{"name":"kotlinx.serialization"}
""")
println(data)
}
我們會得到以下例外。
Exception in thread "main" kotlinx.serialization.MissingFieldException: Field 'language' is required for type with serial name 'example.exampleClasses07.Project', but it was missing at path: $
暫態屬性
屬性可以通過 @Transient 註解排除在序列化之外(不要將其與 kotlin.jvm.Transient 混淆)。暫態屬性必須有一個默認值。
@Serializable
data class Project(val name: String, @Transient val language: String = "Kotlin")
fun main() {
val data = Json.decodeFromString<Project>("""
{"name":"kotlinx.serialization","language":"Kotlin"}
""")
println(data)
}
即使在序列格式中明確指定了它的值,即使指定的值與默認值相等,也會產生以下例外。
Exception in thread "main" kotlinx.serialization.json.internal.JsonDecodingException: Unexpected JSON token at offset 42: Encountered an unknown key 'language' at path: $.name
Use 'ignoreUnknownKeys = true' in 'Json {}' builder to ignore unknown keys.
忽略未知鍵功能在 "忽略未知鍵" 一節中解釋。
默認值不會被編碼
默認情況下,默認值不會在 JSON 中編碼。這種行為的動機是,在大多數現實生活場景中,這種配置減少了視覺雜訊,並節省了序列化的資料量。
@Serializable
data class Project(val name: String, val language: String = "Kotlin")
fun main() {
val data = Project("kotlinx.serialization")
println(Json.encodeToString(data))
}
這會產生以下輸出,因為 language 屬性的值等於默認值,所以它不會出現在 JSON 中。
{"name":"kotlinx.serialization"}
查看 JSON 的 "編碼默認值" 一節了解如何配置此行為。此外,這種行為可以在不考慮格式設置的情況下進行控制。為此,可以使用 EncodeDefault 註解:
@Serializable
data class Project(
val name: String,
@EncodeDefault val language: String = "Kotlin"
)
這個註解指示框架無論值或格式設置如何,都要始終序列化屬性。還可以使用 EncodeDefault.Mode 參數將其調整為相反的行為:
@Serializable
data class User(
val name: String,
@EncodeDefault(EncodeDefault.Mode.NEVER) val projects: List<Project> = emptyList()
)
fun main() {
val userA = User("Alice", listOf(Project("kotlinx.serialization")))
val userB = User("Bob")
println(Json.encodeToString(userA))
println(Json.encodeToString(userB))
}
如您所見,language 屬性被保留,而 projects 被忽略:
{"name":"Alice","projects":[{"name":"kotlinx.serialization","language":"Kotlin"}]}
{"name":"Bob"}
可空屬性
Kotlin Serialization 原生支持可空屬性。
@Serializable
class Project(val name: String, val renamedTo: String? = null)
fun main() {
val data = Project("kotlinx.serialization")
println(Json.encodeToString(data))
}
由於默認值不會被編碼,因此此範例不會在 JSON 中編碼 null。
{"name":"kotlinx.serialization"}
強制型別安全
Kotlin Serialization 強制執行 Kotlin 編程語言的型別安全。特別是,讓我們嘗試將 JSON 對象中的 null 值解碼為非空的 Kotlin 屬性 language。
@Serializable
data class Project(val name: String, val language: String = "Kotlin")
fun main() {
val data = Json.decodeFromString<Project>("""
{"name":"kotlinx.serialization","language":null}
""")
println(data)
}
即使 language 屬性具有默認值,但將 null 值分配給它仍然是一個錯誤。
Exception in thread "main" kotlinx.serialization.json.internal.JsonDecodingException: Unexpected JSON token at offset 52: Expected string literal but 'null' literal was found at path: $.language
Use 'coerceInputValues = true' in 'Json {}' builder to coerce nulls if property has a default value.
在解碼第三方 JSON 時,可能希望將 null 強制為默認值。相應的功能在 "強制輸入值" 一節中解釋。
引用物件
可序列化的類別可以在其可序列化屬性中引用其他類別。引用的類別也必須標記為 @Serializable。
@Serializable
class Project(val name: String, val owner: User)
@Serializable
class User(val name: String)
fun main() {
val owner = User("kotlin")
val data = Project("kotlinx.serialization", owner)
println(Json.encodeToString(data))
}
當編碼為 JSON 時,它會生成一個嵌套的 JSON 物件。
{"name":"kotlinx.serialization","owner":{"name":"kotlin"}}
對於不可序列化的類別引用,可以將其標記為暫態屬性,或者為它們提供自定義序列化器,如 "序列化器" 一章所示。
不壓縮重複引用
Kotlin Serialization 專為編碼和解碼純資料而設計。它不支持重建具有重複物件引用的任意物件圖。例如,讓我們嘗試序列化一個兩次引用同一 owner 實例的物件。
@Serializable
class Project(val name: String, val owner: User, val maintainer: User)
@Serializable
class User(val name: String)
fun main() {
val owner = User("kotlin")
val data = Project("kotlinx.serialization", owner, owner)
println(Json.encodeToString(data))
}
我們會得到兩次編碼的 owner 值。
{"name":"kotlinx.serialization","owner":{"name":"kotlin"},"maintainer":{"name":"kotlin"}}
嘗試序列化循環結構會導致堆疊溢出。你可以使用暫態屬性來排除某些引用的序列化。
泛型類別
Kotlin 中的泛型類別提供了型別多態行為,這在編譯期間由 Kotlin Serialization 強制執行。例如,考慮一個泛型可序列化類別 Box<T>。
@Serializable
class Box<T>(val contents: T)
Box<T> 類別可以與內建型別如 Int 一起使用,也可以與使用者定義的型別如 Project 一起使用。
@Serializable
class Data(
val a: Box<Int>,
val b: Box<Project>
)
fun main() {
val data = Data(Box(42), Box(Project("kotlinx.serialization", "Kotlin")))
println(Json.encodeToString(data))
}
我們在 JSON 中獲得的實際型別取決於為 Box 指定的實際編譯時型別參數。
{"a":{"contents":42},"b":{"contents":{"name":"kotlinx.serialization","language":"K
otlin"}}}
如果實際泛型類型不可序列化,則會產生編譯時錯誤。
序列欄位名稱
在編碼表示中使用的屬性名稱(例如我們的 JSON 示例中的屬性名稱)默認情況下與其在源代碼中的名稱相同。用於序列化的名稱稱為序列名稱,可以使用 @SerialName 註解進行更改。例如,我們可以在源代碼中有一個 language 屬性,並將其序列名稱縮寫。
@Serializable
class Project(val name: String, @SerialName("lang") val language: String)
fun main() {
val data = Project("kotlinx.serialization", "Kotlin")
println(Json.encodeToString(data))
}
現在我們看到在 JSON 輸出中使用了縮寫名稱 lang。
{"name":"kotlinx.serialization","lang":"Kotlin"}
下一章將介紹內建類別。
標準內建類別
這是《Kotlin 序列化指南》的第二章。除了所有的基本類型和字串外,Kotlin 標準函式庫中的一些類別(包括標準集合)的序列化功能也內建在 Kotlin 序列化中。本章將解釋這些功能的詳細內容。
目錄
- 基本類型
- 數字
- 長整數
- 作為字串的長整數
- 列舉類別
- 列舉項目的序列名稱
- 複合類型
Pair和Triple- 列表
- 集合和其他集合類型
- 反序列化集合
- 映射 (
Map) - 單例物件 (
Unit) 和單例物件類別 - 持續時間 (
Duration) Nothing
基本類型
Kotlin 序列化支援以下十種基本類型:Boolean、Byte、Short、Int、Long、Float、Double、Char、String 以及列舉類型。Kotlin 序列化中的其他類型都是由這些基本值組成的複合類型。
數字
所有類型的整數和浮點數 Kotlin 數字都可以序列化。
@Serializable
class Data(
val answer: Int,
val pi: Double
)
fun main() {
val data = Data(42, PI)
println(Json.encodeToString(data))
}
這些數字在 JSON 中會被表示為自然的形式。
{"answer":42,"pi":3.141592653589793}
長整數
長整數 (Long) 也可以被序列化。
@Serializable
class Data(val signature: Long)
fun main() {
val data = Data(0x1CAFE2FEED0BABE0)
println(Json.encodeToString(data))
}
預設情況下,它們會被序列化為 JSON 數字。
{"signature":2067120338512882656}
作為字串的長整數
上面的 JSON 輸出會被 Kotlin/JS 上運行的 Kotlin 序列化正常解碼。然而,如果我們嘗試使用原生的 JavaScript 方法解析這個 JSON,會得到這樣的截斷結果。
JSON.parse("{\"signature\":2067120338512882656}")
// ▶ {signature: 2067120338512882700}
Kotlin 的 Long 類型的完整範圍無法適配 JavaScript 的數字,因此在 JavaScript 中會丟失精度。常見的解決方案是使用 JSON 字串類型來表示具有完整精度的長整數。Kotlin 序列化通過 LongAsStringSerializer 選擇性地支持這種方法,可以使用 @Serializable 註解將其指定給特定的 Long 屬性:
@Serializable
class Data(
@Serializable(with=LongAsStringSerializer::class)
val signature: Long
)
fun main() {
val data = Data(0x1CAFE2FEED0BABE0)
println(Json.encodeToString(data))
}
這個 JSON 可以被 JavaScript 原生解析而不丟失精度。
{"signature":"2067120338512882656"}
關於如何為整個檔案中的所有屬性指定類似 LongAsStringSerializer 的序列化器,可以參考 "為檔案指定序列化器" 這一節。
列舉類別
所有的列舉類別都是可序列化的,無需將它們標記為 @Serializable,如下例所示。
// 列舉類別不需要 @Serializable 註解
enum class Status { SUPPORTED }
@Serializable
class Project(val name: String, val status: Status)
fun main() {
val data = Project("kotlinx.serialization", Status.SUPPORTED)
println(Json.encodeToString(data))
}
在 JSON 中,列舉會被編碼為字串。
{"name":"kotlinx.serialization","status":"SUPPORTED"}
注意:在 Kotlin/JS 和 Kotlin/Native 上,如果你想將列舉類別作為根物件使用(即使用 encodeToString<Status>(Status.SUPPORTED)),需要為列舉類別添加 @Serializable 註解。
列舉項目的序列名稱
列舉項目的序列名稱可以像 "序列欄位名稱" 一節所示一樣,通過 SerialName 註解來自訂。然而,在這種情況下,整個列舉類別必須標記為 @Serializable。
@Serializable // 因為使用了 @SerialName,所以需要此註解
enum class Status { @SerialName("maintained") SUPPORTED }
@Serializable
class Project(val name: String, val status: Status)
fun main() {
val data = Project("kotlinx.serialization", Status.SUPPORTED)
println(Json.encodeToString(data))
}
我們可以看到,在結果 JSON 中使用了指定的序列名稱。
{"name":"kotlinx.serialization","status":"maintained"}
複合類型
Kotlin 序列化支援標準函式庫中的一些複合類型。
Pair 和 Triple
Kotlin 標準函式庫中的簡單資料類別 Pair 和 Triple 是可序列化的。
@Serializable
class Project(val name: String)
fun main() {
val pair = 1 to Project("kotlinx.serialization")
println(Json.encodeToString(pair))
}
{"first":1,"second":{"name":"kotlinx.serialization"}}
並不是所有的 Kotlin 標準函式庫中的類別都是可序列化的,特別是範圍 (Range) 和正則表達式 (Regex) 類別目前不可序列化。未來可能會添加它們的序列化支持。
列表
可以序列化一個可序列化類別的列表。
@Serializable
class Project(val name: String)
fun main() {
val list = listOf(
Project("kotlinx.serialization"),
Project("kotlinx.coroutines")
)
println(Json.encodeToString(list))
}
結果在 JSON 中表示為列表。
[{"name":"kotlinx.serialization"},{"name":"kotlinx.coroutines"}]
集合和其他集合類型
其他集合類型,如集合 (Set),也可以被序列化。
@Serializable
class Project(val name: String)
fun main() {
val set = setOf(
Project("kotlinx.serialization"),
Project("kotlinx.coroutines")
)
println(Json.encodeToString(set))
}
Set 也會像其他所有集合一樣,在 JSON 中表示為列表。
[{"name":"kotlinx.serialization"},{"name":"kotlinx.coroutines"}]
反序列化集合
在反序列化過程中,結果物件的類型由源代碼中指定的靜態類型決定——無論是屬性的類型還是解碼函數的類型參數。以下範例展示了相同的 JSON 整數列表如何被反序列化為兩個不同 Kotlin 類型的屬性。
@Serializable
data class Data(
val a: List<Int>,
val b: Set<Int>
)
fun main() {
val data = Json.decodeFromString<Data>("""
{
"a": [42, 42],
"b": [42, 42]
}
""")
println(data)
}
由於 data.b 屬性是 Set,因此其中的重複值消失了。
Data(a=[42, 42], b=[42])
映射 (Map)
具有基本類型或列舉鍵和任意可序列化值的 Map 可以被序列化。
@Serializable
class Project(val name: String)
fun main() {
val map = mapOf(
1 to Project("kotlinx.serialization"),
2 to Project("kotlinx.coroutines")
)
println(Json.encodeToString(map))
}
Kotlin 的映射在 JSON 中表示為物件。在 JSON 中,物件的鍵總是字串,所以即使在 Kotlin 中它們是數字,也會被編碼為字串,如下所示。
{"1":{"name":"kotlinx.serialization"},"2":{"name":"kotlinx.coroutines"}}
這是 JSON 的
一個特定限制,即鍵不能是複合的。可以通過參考 "允許結構化的映射鍵" 這一節來解決這個限制。
單例物件 (Unit) 和單例物件類別
Kotlin 內建的 Unit 類型也是可序列化的。Unit 是 Kotlin 的一個單例物件,並且與其他 Kotlin 物件一樣處理。
從概念上講,單例物件是一個只有一個實例的類別,這意味著狀態不定義物件,而是物件定義其狀態。在 JSON 中,物件會被序列化為空結構。
@Serializable
object SerializationVersion {
val libraryVersion: String = "1.0.0"
}
fun main() {
println(Json.encodeToString(SerializationVersion))
println(Json.encodeToString(Unit))
}
雖然這在表面上看似無用,但在密封類別序列化中這很有用,這在 "多型性" 章節的 "物件" 部分中進行了解釋。
{}
{}
物件的序列化是格式特定的。其他格式可能會以不同方式表示物件,例如使用它們的全名。
持續時間 (Duration)
自 Kotlin 1.7.20 以來,Duration 類別已經成為可序列化的。
fun main() {
val duration = 1000.toDuration(DurationUnit.SECONDS)
println(Json.encodeToString(duration))
}
Duration 會被序列化為 ISO-8601-2 格式的字串。
"PT16M40S"
Nothing
預設情況下,Nothing 是一個可序列化的類別。然而,由於該類別沒有實例,因此不可能對其值進行編碼或解碼——任何嘗試都會導致異常。
當語法上需要某種類型,但實際上在序列化中不使用時,會使用這個序列化器。例如,在使用參數化多型基類時:
@Serializable
sealed class ParametrizedParent<out R> {
@Serializable
data class ChildWithoutParameter(val value: Int) : ParametrizedParent<Nothing>()
}
fun main() {
println(Json.encodeToString(ParametrizedParent.ChildWithoutParameter(42)))
}
在編碼過程中,Nothing 的序列化器未被使用。
{"value":42}
下一章將介紹序列化器 (Serializers)。
序列化器
這是《Kotlin 序列化指南》的第三章。本章將更詳細地介紹序列化器,並展示如何編寫自定義序列化器。
目錄
- 序列化器介紹
- 插件生成的序列化器
- 插件生成的泛型序列化器
- 內建的基本序列化器
- 構建集合序列化器
- 使用頂級序列化器函數
- 自定義序列化器
- 基本序列化器
- 委派序列化器
- 通過代理實現複合序列化器
- 手寫的複合序列化器
- 順序解碼協議(實驗性)
- 序列化第三方類別
- 手動傳遞序列化器
- 為屬性指定序列化器
- 為特定類型指定序列化器
- 為檔案指定序列化器
- 使用型別別名全局指定序列化器
- 泛型類型的自定義序列化器
- 特定格式的序列化器
- 上下文序列化
- 序列化器模組
- 上下文序列化與泛型類別
- 為其他 Kotlin 類別衍生外部序列化器(實驗性)
- 外部序列化使用屬性
序列化器介紹
像 JSON 這樣的格式控制著物件編碼成特定的輸出位元組,但如何將物件分解為其組成屬性則由序列化器控制。到目前為止,我們已經使用了通過 @Serializable 註解自動生成的序列化器,如 "可序列化的類別" 章節中所解釋的,或使用了在 "內建類別" 章節中展示的內建序列化器。
作為一個激勵性的例子,讓我們來看一下下面這個 Color 類別,它使用一個整數值來存儲其 RGB 位元組。
@Serializable
class Color(val rgb: Int)
fun main() {
val green = Color(0x00ff00)
println(Json.encodeToString(green))
}
預設情況下,這個類別會將其 rgb 屬性序列化為 JSON。
{"rgb":65280}
插件生成的序列化器
每個標記有 @Serializable 註解的類別(如上一個例子中的 Color 類別)都會由 Kotlin 序列化編譯器插件自動生成一個 KSerializer 介面的實例。我們可以使用類別的伴生對象上的 .serializer() 函數來檢索此實例。
我們可以檢查其 descriptor 屬性,它描述了序列化類別的結構。我們會在後續章節中詳細了解這一點。
fun main() {
val colorSerializer: KSerializer<Color> = Color.serializer()
println(colorSerializer.descriptor)
}
輸出:
Color(rgb: kotlin.Int)
當 Color 類別本身被序列化時,或當它被用作其他類別的屬性時,Kotlin 序列化框架會自動檢索並使用此序列化器。
你無法在可序列化類別的伴生對象上自定義自己的 serializer() 函數。
插件生成的泛型序列化器
對於泛型類別,如 "泛型類別" 章節中展示的 Box 類別,自動生成的 .serializer() 函數接受的參數數量與對應類別中的類型參數數量相同。這些參數的類型是 KSerializer,因此在構建泛型類別的序列化器實例時,必須提供實際類型參數的序列化器。
@Serializable
@SerialName("Box")
class Box<T>(val contents: T)
fun main() {
val boxedColorSerializer = Box.serializer(Color.serializer())
println(boxedColorSerializer.descriptor)
}
我們可以看到,已經實例化了一個序列化器來序列化具體的 Box<Color>。
Box(contents: Color)
內建的基本序列化器
內建類別的基本序列化器可以通過 .serializer() 擴展函數來檢索。
fun main() {
val intSerializer: KSerializer<Int> = Int.serializer()
println(intSerializer.descriptor)
}
構建集合序列化器
當需要時,內建集合的序列化器必須通過對應的函數如 ListSerializer()、SetSerializer()、MapSerializer() 等顯式構建。這些類別是泛型的,因此要實例化它們的序列化器,我們必須為其類型參數提供相應的序列化器。例如,我們可以如下生成一個 List<String> 的序列化器。
fun main() {
val stringListSerializer: KSerializer<List<String>> = ListSerializer(String.serializer())
println(stringListSerializer.descriptor)
}
使用頂級序列化器函數
當不確定時,你可以隨時使用頂級泛型 serializer<T>() 函數來檢索源代碼中任意 Kotlin 類型的序列化器。
@Serializable
@SerialName("Color")
class Color(val rgb: Int)
fun main() {
val stringToColorMapSerializer: KSerializer<Map<String, Color>> = serializer()
println(stringToColorMapSerializer.descriptor)
}
自定義序列化器
插件生成的序列化器非常方便,但對於像 Color 這樣的類別,它可能無法生成我們想要的 JSON。讓我們來研究一些替代方案。
基本序列化器
我們想將 Color 類別序列化為一個十六進制字串,其中綠色將被表示為 "00ff00"。為了實現這一點,我們需要編寫一個實現 KSerializer 介面的物件來處理 Color 類別。
object ColorAsStringSerializer : KSerializer<Color> {
override val descriptor: SerialDescriptor = PrimitiveSerialDescriptor("Color", PrimitiveKind.STRING)
override fun serialize(encoder: Encoder, value: Color) {
val string = value.rgb.toString(16).padStart(6, '0')
encoder.encodeString(string)
}
override fun deserialize(decoder: Decoder): Color {
val string = decoder.decodeString()
return Color(string.toInt(16))
}
}
序列化器包含三個必須的部分:
-
serialize函數實現了SerializationStrategy。它接收一個Encoder的實例和一個要序列化的值。它使用Encoder的encodeXxx函數來將值表示為一系列基本類型。在我們的例子中,使用了encodeString。 -
deserialize函數實現了DeserializationStrategy。它接收一個Decoder的實例並返回一個反序列化的值。它使用Decoder的decodeXxx函數來解碼對應的值。在我們的例子中,使用了decodeString。 -
descriptor屬性必須準確描述encodeXxx和decodeXxx函數的作用,以便格式實現能夠提前知道它們將調用哪些編碼/解碼方法。對於基本序列化,必須使用PrimitiveSerialDescriptor函數並為正在序列化的類型提供唯一的名稱。PrimitiveKind描述了實現中使用的特定encodeXxx/decodeXxx方法。
當 descriptor 與編碼/解碼方法不對應時,結果代碼的行為是未定義的,可能會在未來的更新中隨機更改。
下一步是將序列化器綁定到類別。這可以通過在 @Serializable 註解中添加 with 屬性來實現。
@Serializable(with = ColorAsStringSerializer::class)
class Color(val rgb: Int)
現在我們可以像以前一樣序列化 Color 類別了。
fun main() {
val green = Color(0x00ff00)
println(Json.encodeToString(green))
}
我們得到了我們想要的十六進制字串
的序列表示。
"00ff00"
反序列化也很簡單,因為我們實現了 deserialize 方法。
@Serializable(with = ColorAsStringSerializer::class)
class Color(val rgb: Int)
fun main() {
val color = Json.decodeFromString<Color>("\"00ff00\"")
println(color.rgb) // prints 65280
}
它也適用於我們序列化或反序列化具有 Color 屬性的不同類別。
@Serializable(with = ColorAsStringSerializer::class)
data class Color(val rgb: Int)
@Serializable
data class Settings(val background: Color, val foreground: Color)
fun main() {
val data = Settings(Color(0xffffff), Color(0))
val string = Json.encodeToString(data)
println(string)
require(Json.decodeFromString<Settings>(string) == data)
}
兩個 Color 屬性都被序列化為字串。
{"background":"ffffff","foreground":"000000"}
委派序列化器
在前面的例子中,我們將 Color 類別表示為字串。字串被認為是一種基本類型,因此我們使用了 PrimitiveClassDescriptor 和專門的 encodeString 方法。現在讓我們看看如果我們需要將 Color 序列化為另一種非基本類型(例如 IntArray),我們的操作會是什麼。
KSerializer 的實現將在 Color 和 IntArray 之間進行轉換,但實際的序列化邏輯將委派給 IntArraySerializer,使用 encodeSerializableValue 和 decodeSerializableValue。
import kotlinx.serialization.builtins.IntArraySerializer
class ColorIntArraySerializer : KSerializer<Color> {
private val delegateSerializer = IntArraySerializer()
override val descriptor = SerialDescriptor("Color", delegateSerializer.descriptor)
override fun serialize(encoder: Encoder, value: Color) {
val data = intArrayOf(
(value.rgb shr 16) and 0xFF,
(value.rgb shr 8) and 0xFF,
value.rgb and 0xFF
)
encoder.encodeSerializableValue(delegateSerializer, data)
}
override fun deserialize(decoder: Decoder): Color {
val array = decoder.decodeSerializableValue(delegateSerializer)
return Color((array[0] shl 16) or (array[1] shl 8) or array[2])
}
}
注意,這裡我們不能使用預設的 Color.serializer().descriptor,因為依賴於架構的格式可能會認為我們會調用 encodeInt 而不是 encodeSerializableValue。同樣,我們也不能直接使用 IntArraySerializer().descriptor,否則處理整數數組的格式將無法區分值是 IntArray 還是 Color。不用擔心,當序列化實際的底層整數數組時,這個優化仍然會起作用。
我們現在可以使用這個序列化器:
@Serializable(with = ColorIntArraySerializer::class)
class Color(val rgb: Int)
fun main() {
val green = Color(0x00ff00)
println(Json.encodeToString(green))
}
正如您所見,這種數組表示在 JSON 中不是很有用,但在與 ByteArray 和二進制格式一起使用時可能會節省一些空間。
[0,255,0]
通過代理實現複合序列化器
現在我們的挑戰是讓 Color 被序列化,這樣它在 JSON 中被表示為一個具有三個屬性(r、g 和 b)的類別,從而讓 JSON 將其編碼為物件。實現這一目標的最簡單方法是定義一個模擬 Color 序列化形式的代理類別,然後將其用作 Color 的序列化器。我們還可以將這個代理類別的 SerialName 設置為 Color。然後,如果任何格式使用此名稱,代理看起來就像是一個 Color 類別。代理類別可以是私有的,並且可以在其 init 區塊中強制執行所有關於類別序列表示的約束。
@Serializable
@SerialName("Color")
private class ColorSurrogate(val r: Int, val g: Int, val b: Int) {
init {
require(r in 0..255 && g in 0..255 && b in 0..255)
}
}
現在我們可以使用 ColorSurrogate.serializer() 函數來檢索為代理類別自動生成的序列化器。
我們可以像在委派序列化器中那樣使用相同的方法,但這次,我們完全重用了為代理類別自動生成的 SerialDescriptor,因為它應該與原始類別無法區分。
object ColorSerializer : KSerializer<Color> {
override val descriptor: SerialDescriptor = ColorSurrogate.serializer().descriptor
override fun serialize(encoder: Encoder, value: Color) {
val surrogate = ColorSurrogate((value.rgb shr 16) and 0xff, (value.rgb shr 8) and 0xff, value.rgb and 0xff)
encoder.encodeSerializableValue(ColorSurrogate.serializer(), surrogate)
}
override fun deserialize(decoder: Decoder): Color {
val surrogate = decoder.decodeSerializableValue(ColorSurrogate.serializer())
return Color((surrogate.r shl 16) or (surrogate.g shl 8) or surrogate.b)
}
}
我們將 ColorSerializer 序列化器綁定到 Color 類別。
@Serializable(with = ColorSerializer::class)
class Color(val rgb: Int)
現在我們可以享受 Color 類別序列化的結果了。
{"r":0,"g":255,"b":0}
手寫的複合序列化器
有些情況下,代理解決方案並不適用。可能我們想避免額外分配的性能影響,或者我們希望為最終的序列化表示提供一組可配置/動態屬性。在這些情況下,我們需要手動編寫一個模仿生成的序列化器行為的類別序列化器。
object ColorAsObjectSerializer : KSerializer<Color> {
讓我們逐步介紹它。首先,使用 buildClassSerialDescriptor 構建器定義一個 descriptor。在構建器的 DSL 中,element 函數會根據其類型自動檢索對應字段的序列化器。元素的順序很重要。它們從零開始編號。
override val descriptor: SerialDescriptor =
buildClassSerialDescriptor("Color") {
element<Int>("r")
element<Int>("g")
element<Int>("b")
}
這裡的 "element" 是一個通用術語。descriptor 的元素取決於其 SerialKind。類別描述符的元素是其屬性,枚舉描述符的元素是其案例,等等。
接著,我們使用 encodeStructure DSL 編寫 serialize 函數,它在其區塊中提供對 CompositeEncoder 的訪問。Encoder 和 CompositeEncoder 之間的區別在於後者具有對應於前者的 encodeXxx 函數的 encodeXxxElement 函數。它們必須按與 descriptor 中相同的順序調用。
override fun serialize(encoder: Encoder, value: Color) =
encoder.encodeStructure(descriptor) {
encodeIntElement(descriptor, 0, (value.rgb shr 16) and 0xff)
encodeIntElement(descriptor, 1, (value.rgb shr 8) and 0xff)
encodeIntElement(descriptor, 2, value.rgb and 0xff)
}
最複雜的部分是 deserialize 函數。它必須支持像 JSON 這樣可以以任意順序解碼屬性的格式。它以調用 decodeStructure 開始,從而獲得 CompositeDecoder 的訪問權限。在內部,我們編寫了一個循環,該循環反覆調用 decodeElementIndex 來解碼下一個元素的索引,然後使用我們的示例中的 decodeIntElement 解碼相應的元素,最後當遇到 CompositeDecoder.DECODE_DONE 時終止循環。
override fun deserialize(decoder: Decoder): Color =
decoder.decodeStructure(descriptor) {
var r = -1
var g = -1
var b =
-1
while (true) {
when (val index = decodeElementIndex(descriptor)) {
0 -> r = decodeIntElement(descriptor, 0)
1 -> g = decodeIntElement(descriptor, 1)
2 -> b = decodeIntElement(descriptor, 2)
CompositeDecoder.DECODE_DONE -> break
else -> error("Unexpected index: $index")
}
}
require(r in 0..255 && g in 0..255 && b in 0..255)
Color((r shl 16) or (g shl 8) or b)
}
現在,我們將最終的序列化器綁定到 Color 類別並測試其序列化/反序列化。
@Serializable(with = ColorAsObjectSerializer::class)
data class Color(val rgb: Int)
fun main() {
val color = Color(0x00ff00)
val string = Json.encodeToString(color)
println(string)
require(Json.decodeFromString<Color>(string) == color)
}
與之前一樣,我們得到了以具有三個鍵的 JSON 物件表示的 Color 類別:
{"r":0,"g":255,"b":0}
順序解碼協議(實驗性)
前一部分中的 deserialize 函數的實現適用於任何格式。然而,有些格式無論何時都會按順序存儲所有複雜數據,或者有時這樣做(例如,JSON 始終按順序存儲集合)。對於這些格式來說,在循環中調用 decodeElementIndex 的複雜協議並不是必需的,如果 CompositeDecoder.decodeSequentially 函數返回 true,則可以使用更快的實現。插件生成的序列化器實際上在概念上類似於以下代碼。
override fun deserialize(decoder: Decoder): Color =
decoder.decodeStructure(descriptor) {
var r = -1
var g = -1
var b = -1
if (decodeSequentially()) { // sequential decoding protocol
r = decodeIntElement(descriptor, 0)
g = decodeIntElement(descriptor, 1)
b = decodeIntElement(descriptor, 2)
} else while (true) {
when (val index = decodeElementIndex(descriptor)) {
0 -> r = decodeIntElement(descriptor, 0)
1 -> g = decodeIntElement(descriptor, 1)
2 -> b = decodeIntElement(descriptor, 2)
CompositeDecoder.DECODE_DONE -> break
else -> error("Unexpected index: $index")
}
}
require(r in 0..255 && g in 0..255 && b in 0..255)
Color((r shl 16) or (g shl 8) or b)
}
序列化第三方類別
有時應用程式必須處理一個不可序列化的外部類型。我們以 java.util.Date 為例。如前所述,我們從為該類別編寫 KSerializer 的實現開始。我們的目標是將 Date 序列化為一個長整數,表示自 Unix 紀元以來的毫秒數,這與 "基本序列化器" 章節中的方法類似。
在接下來的章節中,任何類型的 Date 序列化器都可以工作。例如,如果我們希望將 Date 序列化為一個物件,我們可以使用 "通過代理實現複合序列化器" 章節中的方法。 如果您需要序列化一個本應可序列化但實際不可序列化的第三方 Kotlin 類別,請參閱 "為另一個 Kotlin 類別衍生外部序列化器(實驗性)"。
object DateAsLongSerializer : KSerializer<Date> {
override val descriptor: SerialDescriptor = PrimitiveSerialDescriptor("Date", PrimitiveKind.LONG)
override fun serialize(encoder: Encoder, value: Date) = encoder.encodeLong(value.time)
override fun deserialize(decoder: Decoder): Date = Date(decoder.decodeLong())
}
我們無法通過 @Serializable 註解將 DateAsLongSerializer 序列化器綁定到 Date 類別,因為我們無法控制 Date 的源代碼。這裡有幾種解決方法。
手動傳遞序列化器
所有的 encodeToXxx 和 decodeFromXxx 函數都有一個帶有第一個序列化器參數的重載版本。當一個不可序列化的類別(如 Date)是正在序列化的頂級類別時,我們可以使用這些重載版本。
fun main() {
val kotlin10ReleaseDate = SimpleDateFormat("yyyy-MM-ddX").parse("2016-02-15+00")
println(Json.encodeToString(DateAsLongSerializer, kotlin10ReleaseDate))
}
輸出:
1455494400000
為屬性指定序列化器
當不可序列化類別(如 Date)的屬性作為可序列化類別的一部分被序列化時,我們必須為其提供序列化器,否則代碼將無法編譯。這可以通過在屬性上使用 @Serializable 註解來實現。
@Serializable
class ProgrammingLanguage(
val name: String,
@Serializable(with = DateAsLongSerializer::class)
val stableReleaseDate: Date
)
fun main() {
val data = ProgrammingLanguage("Kotlin", SimpleDateFormat("yyyy-MM-ddX").parse("2016-02-15+00"))
println(Json.encodeToString(data))
}
stableReleaseDate 屬性將使用我們為其指定的序列化策略進行序列化:
{"name":"Kotlin","stableReleaseDate":1455494400000}
為特定類型指定序列化器
@Serializable 註解也可以直接應用於類型。當需要為像 Date 這樣的類型提供自定義序列化器時,這非常方便。最常見的用例是當你有一個日期列表時:
@Serializable
class ProgrammingLanguage(
val name: String,
val releaseDates: List<@Serializable(DateAsLongSerializer::class) Date>
)
fun main() {
val df = SimpleDateFormat("yyyy-MM-ddX")
val data = ProgrammingLanguage("Kotlin", listOf(df.parse("2023-07-06+00"), df.parse("2023-04-25+00"), df.parse("2022-12-28+00")))
println(Json.encodeToString(data))
}
輸出:
{"name":"Kotlin","releaseDates":[1688601600000,1682380800000,1672185600000]}
為檔案指定序列化器
可以通過在檔案開頭使用檔案級別的 UseSerializers 註解來為整個檔案中的特定類型(如 Date)指定序列化器。
@file:UseSerializers(DateAsLongSerializer::class)
現在可以在可序列化類別中使用 Date 屬性,而不需要額外的註解。
@Serializable
class ProgrammingLanguage(val name: String, val stableReleaseDate: Date)
fun main() {
val data = ProgrammingLanguage("Kotlin", SimpleDateFormat("yyyy-MM-ddX").parse("2016-02-15+00"))
println(Json.encodeToString(data))
}
輸出:
{"name":"Kotlin","stableReleaseDate":1455494400000}
使用型別別名全局指定序列化器
在處理序列化策略時,kotlinx.serialization 傾向於成為始終顯式的框架:通常,應在 @Serializable 註解中明確提到它們。因此,我們不提供任何類型的全局序列化器配置(除非後面提到的上下文序列化器)。
然而,在有大量檔案和類別的專案中,每次指定 @file:UseSerializers 可能太過繁瑣,尤其是對於像 Date 或 Instant 這樣在專案中有固定序列化策略的類別。對於這些情況,可以使用型別別名指定序列化器,因為它們會保留註解,包括與序列化相關的註解:
typealias DateAsLong = @Serializable(DateAsLongSerializer::class) Date
typealias
DateAsText = @Serializable(DateAsSimpleTextSerializer::class) Date
使用這些新的不同類型,可以在沒有額外註解的情況下序列化 Date:
@Serializable
class ProgrammingLanguage(val stableReleaseDate: DateAsText, val lastReleaseTimestamp: DateAsLong)
fun main() {
val format = SimpleDateFormat("yyyy-MM-ddX")
val data = ProgrammingLanguage(format.parse("2016-02-15+00"), format.parse("2022-07-07+00"))
println(Json.encodeToString(data))
}
輸出:
{"stableReleaseDate":"2016-02-15","lastReleaseTimestamp":1657152000000}
泛型類型的自定義序列化器
讓我們看一下泛型 Box<T> 類別的例子。我們計劃為其編寫一個自定義序列化策略,因此將其標記為 @Serializable(with = BoxSerializer::class)。
@Serializable(with = BoxSerializer::class)
data class Box<T>(val contents: T)
為常規類型編寫 KSerializer 的實現就像我們在本章中的 Color 類型例子中所見那樣,作為一個 object 來處理。而對於泛型類別的序列化器,它需要一個構造函數,該構造函數接受與類型具有的泛型參數數量相同的 KSerializer 參數。讓我們編寫一個 Box<T> 序列化器,在序列化過程中擦除自身,並將所有工作委派給其 data 屬性的底層序列化器。
class BoxSerializer<T>(private val dataSerializer: KSerializer<T>) : KSerializer<Box<T>> {
override val descriptor: SerialDescriptor = dataSerializer.descriptor
override fun serialize(encoder: Encoder, value: Box<T>) = dataSerializer.serialize(encoder, value.contents)
override fun deserialize(decoder: Decoder) = Box(dataSerializer.deserialize(decoder))
}
現在我們可以序列化和反序列化 Box<Project>。
@Serializable
data class Project(val name: String)
fun main() {
val box = Box(Project("kotlinx.serialization"))
val string = Json.encodeToString(box)
println(string)
println(Json.decodeFromString<Box<Project>>(string))
}
生成的 JSON 看起來像是直接序列化了 Project 類別。
{"name":"kotlinx.serialization"}
Box(contents=Project(name=kotlinx.serialization))
特定格式的序列化器
上述自定義序列化器對每種格式的工作方式相同。然而,可能存在格式特定的功能,序列化器實現可能希望利用這些功能。
"JSON 轉換" 章節提供了利用 JSON 特定功能的序列化器範例。
格式實現可以有針對某種類型的格式特定表示,如 "替代和自定義格式(實驗性)" 章節中的 "格式特定類型" 所解釋的。
本章接下來將介紹根據上下文調整序列化策略的通用方法。
上下文序列化
之前所有的自定義序列化策略都是靜態的,即在編譯時完全定義。例外情況是 "手動傳遞序列化器" 方法,但它僅適用於頂級物件。你可能需要在執行時更改深層物件樹中的物件的序列化策略,策略的選擇是基於上下文的。例如,你可能希望根據序列化資料的協議版本在 JSON 格式中將 java.util.Date 表示為 ISO 8601 字串或長整數。這就是所謂的上下文序列化,並且它由內建的 ContextualSerializer 類別支持。通常我們不需要顯式使用這個序列化器類別——可以使用 @Contextual 註解作為 @Serializable(with = ContextualSerializer::class) 註解的快捷方式,或者可以像 UseSerializers 註解那樣在檔案級別使用 UseContextualSerialization 註解。讓我們看一個利用前者的範例。
@Serializable
class ProgrammingLanguage(
val name: String,
@Contextual
val stableReleaseDate: Date
)
要實際序列化這個類別,我們必須在調用 encodeToXxx/decodeFromXxx 函數時提供對應的上下文。否則,我們將得到 "Serializer for class 'Date' is not found" 的異常。
序列化器模組
要提供上下文,我們需要定義一個 SerializersModule 實例,該實例描述了在執行時應該使用哪些序列化器來序列化哪些上下文可序列化類別。這可以使用 SerializersModule {} 構建函數完成,該函數提供了 SerializersModuleBuilder DSL 來註冊序列化器。在下面的範例中,我們使用了帶有序列化器的 contextual 函數。對應的類別將通過內聯類型參數自動獲取該序列化器。
private val module = SerializersModule {
contextual(DateAsLongSerializer)
}
接下來,我們使用 Json {} 構建函數和 serializersModule 屬性創建一個帶有這個模組的 JSON 格式實例。
關於自定義 JSON 配置的詳細信息可以在 "JSON 配置" 章節中找到。
val format = Json { serializersModule = module }
現在我們可以使用這個格式序列化我們的資料。
fun main() {
val data = ProgrammingLanguage("Kotlin", SimpleDateFormat("yyyy-MM-ddX").parse("2016-02-15+00"))
println(format.encodeToString(data))
}
輸出:
{"name":"Kotlin","stableReleaseDate":1455494400000}
上下文序列化與泛型類別
在上一節中,我們看到可以在模組中註冊序列化器實例,以便上下文中序列化我們想要的類別。我們還知道泛型類別的序列化器具有構造函數參數——類型參數序列化器。這意味著我們不能為類別使用一個序列化器實例,如果這個類別是泛型的:
val incorrectModule = SerializersModule {
// 只能序列化 Box<Int>,而不能序列化 Box<String> 或其他類型
contextual(BoxSerializer(Int.serializer()))
}
當我們想要上下文序列化泛型類別時,可以在模組中註冊提供者:
val correctModule = SerializersModule {
// args[0] 包含 Int.serializer() 或 String.serializer(),具體取決於使用情況
contextual(Box::class) { args -> BoxSerializer(args[0]) }
}
關於序列化模組的額外細節可以在 "多型性" 章節的 "合併庫序列化模組" 部分中找到。
為其他 Kotlin 類別衍生外部序列化器(實驗性)
如果要序列化的第三方類別是具有僅包含屬性的主要構造函數的 Kotlin 類別(這種類別本可以標記為 @Serializable),那麼您可以使用 Serializer 註解並在物件上設置 forClass 屬性來為其生成一個外部序列化器。
// NOT @Serializable
class Project(val name: String, val language: String)
@Serializer(forClass = Project::class)
object ProjectSerializer
您必須使用本章中解釋的一種方法將此序列化器綁定到類別。我們將按照 "手動傳遞序列化器" 方法進行此示例。
fun main() {
val data = Project("kotlinx.serialization", "Kotlin")
println(Json.encodeToString(ProjectSerializer, data))
}
這將所有的 Project 屬性序列化:
{"name":"kotlinx.serialization","language":"Kotlin"}
外部序列化使用屬性
正如我們之前看到的,常規 @Serializable 註解會創建一個序列化器,以便序列化備援欄位。使用 Serializer(forClass = ...) 的外部序列化無法訪問備援欄位,因此其工作方式不同。它僅
序列化具有 setter 的可訪問屬性或屬於主要構造函數的屬性。以下範例展示了這一點。
// NOT @Serializable, will use external serializer
class Project(
// val in a primary constructor -- serialized
val name: String
) {
var stars: Int = 0 // property with getter & setter -- serialized
val path: String // getter only -- not serialized
get() = "kotlin/$name"
private var locked: Boolean = false // private, not accessible -- not serialized
}
@Serializer(forClass = Project::class)
object ProjectSerializer
fun main() {
val data = Project("kotlinx.serialization").apply { stars = 9000 }
println(Json.encodeToString(ProjectSerializer, data))
}
輸出如下:
{"name":"kotlinx.serialization","stars":9000}
下一章將介紹多型性。
【kotlin】Serialization CH1-CH4
出處: https://github.com/Kotlin/kotlinx.serialization/blob/master/docs/serialization-guide.md
CH1 基本序列化
要將物件樹轉換成字串或位元組序列,必須經過兩個相互交織的過程。
第一步是序列化——將物件轉換成其組成的基本值的序列。這個過程對所有資料格式來說都是
共通的,結果取決於被序列化的物件。序列化的過程由序列化器控制。
第二步稱為編碼——這是將相應的基本值序列轉換成輸出格式表示的過程。編碼器控制這個過程。當區分不那麼重要時,編碼和序列化這兩個術語可以互換使用。
+---------+ 序列化 +------------+ 編碼 +---------------+ | 物件 | ------------> | 基本值 | ---------> | 輸出格式 | +---------+ +------------+ +---------------+
+---------+ Serialization +------------+ Encoding +---------------+
| Objects | --------------> | Primitives | ---------> | Output format |
+---------+ +------------+ +---------------+反向過程從解析輸入格式並解碼基本值開始,隨後將得到的流反序列化為物件。我們稍後會詳細探討這個過程。
現在,我們從 JSON 編碼開始。
JSON 編碼
將資料轉換成特定格式的整個過程稱為編碼。對於 JSON,我們使用 Json.encodeToString 擴展函數來編碼資料。它在底層將傳遞給它的物件序列化並編碼為 JSON 字串。
讓我們從描述專案的一個類別開始,並嘗試獲得其 JSON 表示。
class Project(val name: String, val language: String)
fun main() {
val data = Project("kotlinx.serialization", "Kotlin")
println(Json.encodeToString(data))
}
執行這段程式碼時,我們會得到一個例外。
Exception in thread "main" kotlinx.serialization.SerializationException: Serializer for class 'Project' is not found.
Please ensure that class is marked as '@Serializable' and that the serialization compiler plugin is applied.
可序列化的類別必須顯式標記。Kotlin Serialization 不使用反射,因此您無法意外反序列化不應該可序列化的類別。我們通過添加 @Serializable 註解來修正它。
@Serializable
class Project(val name: String, val language: String)
fun main() {
val data = Project("kotlinx.serialization", "Kotlin")
println(Json.encodeToString(data))
}
這樣,我們將會得到相應的 JSON 輸出。
{"name":"kotlinx.serialization","language":"Kotlin"}
JSON 解碼
反向過程稱為解碼。要將 JSON 字串解碼為物件,我們將使用 Json.decodeFromString 擴展函數。為了指定我們想要獲得的結果類型,我們將類型參數提供給這個函數。
如我們稍後所見,序列化可以處理不同種類的類別。這裡我們將 Project 類別標記為 data class,這不是因為它是必需的,而是因為我們想要打印其內容以驗證它是如何解碼的。
@Serializable
data class Project(val name: String, val language: String)
fun main() {
val data = Json.decodeFromString<Project>("""
{"name":"kotlinx.serialization","language":"Kotlin"}
""")
println(data)
}
執行這段程式碼後,我們會得到物件:
Project(name=kotlinx.serialization, language=Kotlin)
可序列化的類別
這部分將更詳細地說明如何處理不同的 @Serializable 類別。
序列化備援屬性
只有具有備援欄位的類別屬性會被序列化,因此沒有備援欄位的 getter/setter 屬性和委託屬性將不會被序列化,如以下範例所示。
@Serializable
class Project(
var name: String // name 是具有備援欄位的屬性——會被序列化
) {
var stars: Int = 0 // 具有備援欄位的屬性——會被序列化
val path: String // 僅有 getter,沒有備援欄位——不會被序列化
get() = "kotlin/$name"
var id by ::name // 委託屬性——不會被序列化
}
fun main() {
val data = Project("kotlinx.serialization").apply { stars = 9000 }
println(Json.encodeToString(data))
}
我們可以清楚地看到,只有 name 和 stars 屬性出現在 JSON 輸出中。
{"name":"kotlinx.serialization","stars":9000}
建構子屬性要求
如果我們想要定義一個 Project 類別,並讓它接受一個路徑字串,然後將其分解為相應的屬性,我們可能會傾向於寫出如下代碼。
@Serializable
class Project(path: String) {
val owner: String = path.substringBefore('/')
val name: String = path.substringAfter('/')
}
這個類別無法編譯,因為 @Serializable 註解要求類別主要建構子的所有參數必須是屬性。一個簡單的解決方案是定義一個具有屬性的私有主要建構子,並將我們想要的建構子變成次要建構子。
@Serializable
class Project private constructor(val owner: String, val name: String) {
constructor(path: String) : this(
owner = path.substringBefore('/'),
name = path.substringAfter('/')
)
val path: String
get() = "$owner/$name"
}
序列化在具有私有主要建構子的情況下仍然能夠正常工作,並且仍然只會序列化備援欄位。
fun main() {
println(Json.encodeToString(Project("kotlin/kotlinx.serialization")))
}
這個範例會產生預期的輸出。
{"owner":"kotlin","name":"kotlinx.serialization"}
資料驗證
當你希望在將值存儲到屬性之前進行驗證時,可能會想在主要建構子參數中引入一個沒有屬性的參數。為了使其可序列化,你應該將其替換為主要建構子中的屬性,並將驗證移至 init { ... } 區塊。
@Serializable
class Project(val name: String) {
init {
require(name.isNotEmpty()) { "name 不能為空" }
}
}
反序列化過程與 Kotlin 中的常規建構子一樣,會調用所有的 init 區塊,確保你無法通過反序列化獲得一個無效的類別。讓我們試試看。
fun main() {
val data = Json.decodeFromString<Project>("""
{"name":""}
""")
println(data)
}
執行這段程式碼會產生一個例外:
Exception in thread "main" java.lang.IllegalArgumentException: name 不能為空
選擇性屬性
只有當輸入中存在所有屬性時,物件才能被反序列化。例如,執行以下程式碼。
@Serializable
data class Project(val name: String, val language: String)
fun main() {
val data = Json.decodeFromString<Project>("""
{"name":"kotlinx.serialization"}
""")
println(data)
}
這會產生一個例外:
Exception in thread "main" kotlinx.serialization.MissingFieldException: Field 'language' is required for type with serial name 'example.exampleClasses04.Project', but it was missing at path: $
這個問題可以通過為屬性添加一個默認值來解決,這會自動使其在序列化中成為選擇性屬性。
@Serializable
data class Project(val name: String, val language: String = "Kotlin")
fun main() {
val data = Json.decodeFromString<Project>("""
{"name":"kotlinx.serialization"}
""")
println(data)
}
這會產生以下輸出,其中 language 屬性使用默認值。
Project(name=kotlinx.serialization, language=Kotlin)
選擇性屬性初始化呼叫
當選擇性屬性存在於輸入中時,對應屬性的初始化器
甚至不會被調用。這是一個為了性能而設計的特性,所以要小心不要依賴於初始化器中的副作用。考慮以下範例。
fun computeLanguage(): String {
println("計算中")
return "Kotlin"
}
@Serializable
data class Project(val name: String, val language: String = computeLanguage())
fun main() {
val data = Json.decodeFromString<Project>("""
{"name":"kotlinx.serialization","language":"Kotlin"}
""")
println(data)
}
由於輸入中指定了 language 屬性,因此我們不會看到 "計算中" 的字串被打印出來。
Project(name=kotlinx.serialization, language=Kotlin)
必須的屬性
具有默認值的屬性可以通過 @Required 註解在序列格式中設置為必須的。我們將上一個範例的 language 屬性標記為 @Required。
@Serializable
data class Project(val name: String, @Required val language: String = "Kotlin")
fun main() {
val data = Json.decodeFromString<Project>("""
{"name":"kotlinx.serialization"}
""")
println(data)
}
我們會得到以下例外。
Exception in thread "main" kotlinx.serialization.MissingFieldException: Field 'language' is required for type with serial name 'example.exampleClasses07.Project', but it was missing at path: $
暫態屬性
屬性可以通過 @Transient 註解排除在序列化之外(不要將其與 kotlin.jvm.Transient 混淆)。暫態屬性必須有一個默認值。
@Serializable
data class Project(val name: String, @Transient val language: String = "Kotlin")
fun main() {
val data = Json.decodeFromString<Project>("""
{"name":"kotlinx.serialization","language":"Kotlin"}
""")
println(data)
}
即使在序列格式中明確指定了它的值,即使指定的值與默認值相等,也會產生以下例外。
Exception in thread "main" kotlinx.serialization.json.internal.JsonDecodingException: Unexpected JSON token at offset 42: Encountered an unknown key 'language' at path: $.name
Use 'ignoreUnknownKeys = true' in 'Json {}' builder to ignore unknown keys.
忽略未知鍵功能在 "忽略未知鍵" 一節中解釋。
默認值不會被編碼
默認情況下,默認值不會在 JSON 中編碼。這種行為的動機是,在大多數現實生活場景中,這種配置減少了視覺雜訊,並節省了序列化的資料量。
@Serializable
data class Project(val name: String, val language: String = "Kotlin")
fun main() {
val data = Project("kotlinx.serialization")
println(Json.encodeToString(data))
}
這會產生以下輸出,因為 language 屬性的值等於默認值,所以它不會出現在 JSON 中。
{"name":"kotlinx.serialization"}
查看 JSON 的 "編碼默認值" 一節了解如何配置此行為。此外,這種行為可以在不考慮格式設置的情況下進行控制。為此,可以使用 EncodeDefault 註解:
@Serializable
data class Project(
val name: String,
@EncodeDefault val language: String = "Kotlin"
)
這個註解指示框架無論值或格式設置如何,都要始終序列化屬性。還可以使用 EncodeDefault.Mode 參數將其調整為相反的行為:
@Serializable
data class User(
val name: String,
@EncodeDefault(EncodeDefault.Mode.NEVER) val projects: List<Project> = emptyList()
)
fun main() {
val userA = User("Alice", listOf(Project("kotlinx.serialization")))
val userB = User("Bob")
println(Json.encodeToString(userA))
println(Json.encodeToString(userB))
}
如您所見,language 屬性被保留,而 projects 被忽略:
{"name":"Alice","projects":[{"name":"kotlinx.serialization","language":"Kotlin"}]}
{"name":"Bob"}
可空屬性
Kotlin Serialization 原生支持可空屬性。
@Serializable
class Project(val name: String, val renamedTo: String? = null)
fun main() {
val data = Project("kotlinx.serialization")
println(Json.encodeToString(data))
}
由於默認值不會被編碼,因此此範例不會在 JSON 中編碼 null。
{"name":"kotlinx.serialization"}
強制型別安全
Kotlin Serialization 強制執行 Kotlin 編程語言的型別安全。特別是,讓我們嘗試將 JSON 對象中的 null 值解碼為非空的 Kotlin 屬性 language。
@Serializable
data class Project(val name: String, val language: String = "Kotlin")
fun main() {
val data = Json.decodeFromString<Project>("""
{"name":"kotlinx.serialization","language":null}
""")
println(data)
}
即使 language 屬性具有默認值,但將 null 值分配給它仍然是一個錯誤。
Exception in thread "main" kotlinx.serialization.json.internal.JsonDecodingException: Unexpected JSON token at offset 52: Expected string literal but 'null' literal was found at path: $.language
Use 'coerceInputValues = true' in 'Json {}' builder to coerce nulls if property has a default value.
在解碼第三方 JSON 時,可能希望將 null 強制為默認值。相應的功能在 "強制輸入值" 一節中解釋。
引用物件
可序列化的類別可以在其可序列化屬性中引用其他類別。引用的類別也必須標記為 @Serializable。
@Serializable
class Project(val name: String, val owner: User)
@Serializable
class User(val name: String)
fun main() {
val owner = User("kotlin")
val data = Project("kotlinx.serialization", owner)
println(Json.encodeToString(data))
}
當編碼為 JSON 時,它會生成一個嵌套的 JSON 物件。
{"name":"kotlinx.serialization","owner":{"name":"kotlin"}}
對於不可序列化的類別引用,可以將其標記為暫態屬性,或者為它們提供自定義序列化器,如 "序列化器" 一章所示。
不壓縮重複引用
Kotlin Serialization 專為編碼和解碼純資料而設計。它不支持重建具有重複物件引用的任意物件圖。例如,讓我們嘗試序列化一個兩次引用同一 owner 實例的物件。
@Serializable
class Project(val name: String, val owner: User, val maintainer: User)
@Serializable
class User(val name: String)
fun main() {
val owner = User("kotlin")
val data = Project("kotlinx.serialization", owner, owner)
println(Json.encodeToString(data))
}
我們會得到兩次編碼的 owner 值。
{"name":"kotlinx.serialization","owner":{"name":"kotlin"},"maintainer":{"name":"kotlin"}}
嘗試序列化循環結構會導致堆疊溢出。你可以使用暫態屬性來排除某些引用的序列化。
泛型類別
Kotlin 中的泛型類別提供了型別多態行為,這在編譯期間由 Kotlin Serialization 強制執行。例如,考慮一個泛型可序列化類別 Box<T>。
@Serializable
class Box<T>(val contents: T)
Box<T> 類別可以與內建型別如 Int 一起使用,也可以與使用者定義的型別如 Project 一起使用。
@Serializable
class Data(
val a: Box<Int>,
val b: Box<Project>
)
fun main() {
val data = Data(Box(42), Box(Project("kotlinx.serialization", "Kotlin")))
println(Json.encodeToString(data))
}
我們在 JSON 中獲得的實際型別取決於為 Box 指定的實際編譯時型別參數。
{"a":{"contents":42},"b":{"contents":{"name":"kotlinx.serialization","language":"K
otlin"}}}
如果實際泛型類型不可序列化,則會產生編譯時錯誤。
序列欄位名稱
在編碼表示中使用的屬性名稱(例如我們的 JSON 示例中的屬性名稱)默認情況下與其在源代碼中的名稱相同。用於序列化的名稱稱為序列名稱,可以使用 @SerialName 註解進行更改。例如,我們可以在源代碼中有一個 language 屬性,並將其序列名稱縮寫。
@Serializable
class Project(val name: String, @SerialName("lang") val language: String)
fun main() {
val data = Project("kotlinx.serialization", "Kotlin")
println(Json.encodeToString(data))
}
現在我們看到在 JSON 輸出中使用了縮寫名稱 lang。
{"name":"kotlinx.serialization","lang":"Kotlin"}
下一章將介紹內建類別。
CH2 標準內建類別
這是《Kotlin 序列化指南》的第二章。除了所有的基本類型和字串外,Kotlin 標準函式庫中的一些類別(包括標準集合)的序列化功能也內建在 Kotlin 序列化中。本章將解釋這些功能的詳細內容。
目錄
- 基本類型
- 數字
- 長整數
- 作為字串的長整數
- 列舉類別
- 列舉項目的序列名稱
- 複合類型
Pair和Triple- 列表
- 集合和其他集合類型
- 反序列化集合
- 映射 (
Map) - 單例物件 (
Unit) 和單例物件類別 - 持續時間 (
Duration) Nothing
基本類型
Kotlin 序列化支援以下十種基本類型:Boolean、Byte、Short、Int、Long、Float、Double、Char、String 以及列舉類型。Kotlin 序列化中的其他類型都是由這些基本值組成的複合類型。
數字
所有類型的整數和浮點數 Kotlin 數字都可以序列化。
@Serializable
class Data(
val answer: Int,
val pi: Double
)
fun main() {
val data = Data(42, PI)
println(Json.encodeToString(data))
}
這些數字在 JSON 中會被表示為自然的形式。
{"answer":42,"pi":3.141592653589793}
長整數
長整數 (Long) 也可以被序列化。
@Serializable
class Data(val signature: Long)
fun main() {
val data = Data(0x1CAFE2FEED0BABE0)
println(Json.encodeToString(data))
}
預設情況下,它們會被序列化為 JSON 數字。
{"signature":2067120338512882656}
作為字串的長整數
上面的 JSON 輸出會被 Kotlin/JS 上運行的 Kotlin 序列化正常解碼。然而,如果我們嘗試使用原生的 JavaScript 方法解析這個 JSON,會得到這樣的截斷結果。
JSON.parse("{\"signature\":2067120338512882656}")
// ▶ {signature: 2067120338512882700}
Kotlin 的 Long 類型的完整範圍無法適配 JavaScript 的數字,因此在 JavaScript 中會丟失精度。常見的解決方案是使用 JSON 字串類型來表示具有完整精度的長整數。Kotlin 序列化通過 LongAsStringSerializer 選擇性地支持這種方法,可以使用 @Serializable 註解將其指定給特定的 Long 屬性:
@Serializable
class Data(
@Serializable(with=LongAsStringSerializer::class)
val signature: Long
)
fun main() {
val data = Data(0x1CAFE2FEED0BABE0)
println(Json.encodeToString(data))
}
這個 JSON 可以被 JavaScript 原生解析而不丟失精度。
{"signature":"2067120338512882656"}
關於如何為整個檔案中的所有屬性指定類似 LongAsStringSerializer 的序列化器,可以參考 "為檔案指定序列化器" 這一節。
列舉類別
所有的列舉類別都是可序列化的,無需將它們標記為 @Serializable,如下例所示。
// 列舉類別不需要 @Serializable 註解
enum class Status { SUPPORTED }
@Serializable
class Project(val name: String, val status: Status)
fun main() {
val data = Project("kotlinx.serialization", Status.SUPPORTED)
println(Json.encodeToString(data))
}
在 JSON 中,列舉會被編碼為字串。
{"name":"kotlinx.serialization","status":"SUPPORTED"}
注意:在 Kotlin/JS 和 Kotlin/Native 上,如果你想將列舉類別作為根物件使用(即使用 encodeToString<Status>(Status.SUPPORTED)),需要為列舉類別添加 @Serializable 註解。
列舉項目的序列名稱
列舉項目的序列名稱可以像 "序列欄位名稱" 一節所示一樣,通過 SerialName 註解來自訂。然而,在這種情況下,整個列舉類別必須標記為 @Serializable。
@Serializable // 因為使用了 @SerialName,所以需要此註解
enum class Status { @SerialName("maintained") SUPPORTED }
@Serializable
class Project(val name: String, val status: Status)
fun main() {
val data = Project("kotlinx.serialization", Status.SUPPORTED)
println(Json.encodeToString(data))
}
我們可以看到,在結果 JSON 中使用了指定的序列名稱。
{"name":"kotlinx.serialization","status":"maintained"}
複合類型
Kotlin 序列化支援標準函式庫中的一些複合類型。
Pair 和 Triple
Kotlin 標準函式庫中的簡單資料類別 Pair 和 Triple 是可序列化的。
@Serializable
class Project(val name: String)
fun main() {
val pair = 1 to Project("kotlinx.serialization")
println(Json.encodeToString(pair))
}
{"first":1,"second":{"name":"kotlinx.serialization"}}
並不是所有的 Kotlin 標準函式庫中的類別都是可序列化的,特別是範圍 (Range) 和正則表達式 (Regex) 類別目前不可序列化。未來可能會添加它們的序列化支持。
列表
可以序列化一個可序列化類別的列表。
@Serializable
class Project(val name: String)
fun main() {
val list = listOf(
Project("kotlinx.serialization"),
Project("kotlinx.coroutines")
)
println(Json.encodeToString(list))
}
結果在 JSON 中表示為列表。
[{"name":"kotlinx.serialization"},{"name":"kotlinx.coroutines"}]
集合和其他集合類型
其他集合類型,如集合 (Set),也可以被序列化。
@Serializable
class Project(val name: String)
fun main() {
val set = setOf(
Project("kotlinx.serialization"),
Project("kotlinx.coroutines")
)
println(Json.encodeToString(set))
}
Set 也會像其他所有集合一樣,在 JSON 中表示為列表。
[{"name":"kotlinx.serialization"},{"name":"kotlinx.coroutines"}]
反序列化集合
在反序列化過程中,結果物件的類型由源代碼中指定的靜態類型決定——無論是屬性的類型還是解碼函數的類型參數。以下範例展示了相同的 JSON 整數列表如何被反序列化為兩個不同 Kotlin 類型的屬性。
@Serializable
data class Data(
val a: List<Int>,
val b: Set<Int>
)
fun main() {
val data = Json.decodeFromString<Data>("""
{
"a": [42, 42],
"b": [42, 42]
}
""")
println(data)
}
由於 data.b 屬性是 Set,因此其中的重複值消失了。
Data(a=[42, 42], b=[42])
映射 (Map)
具有基本類型或列舉鍵和任意可序列化值的 Map 可以被序列化。
@Serializable
class Project(val name: String)
fun main() {
val map = mapOf(
1 to Project("kotlinx.serialization"),
2 to Project("kotlinx.coroutines")
)
println(Json.encodeToString(map))
}
Kotlin 的映射在 JSON 中表示為物件。在 JSON 中,物件的鍵總是字串,所以即使在 Kotlin 中它們是數字,也會被編碼為字串,如下所示。
{"1":{"name":"kotlinx.serialization"},"2":{"name":"kotlinx.coroutines"}}
這是 JSON 的
一個特定限制,即鍵不能是複合的。可以通過參考 "允許結構化的映射鍵" 這一節來解決這個限制。
單例物件 (Unit) 和單例物件類別
Kotlin 內建的 Unit 類型也是可序列化的。Unit 是 Kotlin 的一個單例物件,並且與其他 Kotlin 物件一樣處理。
從概念上講,單例物件是一個只有一個實例的類別,這意味著狀態不定義物件,而是物件定義其狀態。在 JSON 中,物件會被序列化為空結構。
@Serializable
object SerializationVersion {
val libraryVersion: String = "1.0.0"
}
fun main() {
println(Json.encodeToString(SerializationVersion))
println(Json.encodeToString(Unit))
}
雖然這在表面上看似無用,但在密封類別序列化中這很有用,這在 "多型性" 章節的 "物件" 部分中進行了解釋。
{}
{}
物件的序列化是格式特定的。其他格式可能會以不同方式表示物件,例如使用它們的全名。
持續時間 (Duration)
自 Kotlin 1.7.20 以來,Duration 類別已經成為可序列化的。
fun main() {
val duration = 1000.toDuration(DurationUnit.SECONDS)
println(Json.encodeToString(duration))
}
Duration 會被序列化為 ISO-8601-2 格式的字串。
"PT16M40S"
Nothing
預設情況下,Nothing 是一個可序列化的類別。然而,由於該類別沒有實例,因此不可能對其值進行編碼或解碼——任何嘗試都會導致異常。
當語法上需要某種類型,但實際上在序列化中不使用時,會使用這個序列化器。例如,在使用參數化多型基類時:
@Serializable
sealed class ParametrizedParent<out R> {
@Serializable
data class ChildWithoutParameter(val value: Int) : ParametrizedParent<Nothing>()
}
fun main() {
println(Json.encodeToString(ParametrizedParent.ChildWithoutParameter(42)))
}
在編碼過程中,Nothing 的序列化器未被使用。
{"value":42}
下一章將介紹序列化器 (Serializers)。
CH3 序列化器
這是《Kotlin 序列化指南》的第三章。本章將更詳細地介紹序列化器,並展示如何編寫自定義序列化器。
目錄
- 序列化器介紹
- 插件生成的序列化器
- 插件生成的泛型序列化器
- 內建的基本序列化器
- 構建集合序列化器
- 使用頂級序列化器函數
- 自定義序列化器
- 基本序列化器
- 委派序列化器
- 通過代理實現複合序列化器
- 手寫的複合序列化器
- 順序解碼協議(實驗性)
- 序列化第三方類別
- 手動傳遞序列化器
- 為屬性指定序列化器
- 為特定類型指定序列化器
- 為檔案指定序列化器
- 使用型別別名全局指定序列化器
- 泛型類型的自定義序列化器
- 特定格式的序列化器
- 上下文序列化
- 序列化器模組
- 上下文序列化與泛型類別
- 為其他 Kotlin 類別衍生外部序列化器(實驗性)
- 外部序列化使用屬性
序列化器介紹
像 JSON 這樣的格式控制著物件編碼成特定的輸出位元組,但如何將物件分解為其組成屬性則由序列化器控制。到目前為止,我們已經使用了通過 @Serializable 註解自動生成的序列化器,如 "可序列化的類別" 章節中所解釋的,或使用了在 "內建類別" 章節中展示的內建序列化器。
作為一個激勵性的例子,讓我們來看一下下面這個 Color 類別,它使用一個整數值來存儲其 RGB 位元組。
@Serializable
class Color(val rgb: Int)
fun main() {
val green = Color(0x00ff00)
println(Json.encodeToString(green))
}
預設情況下,這個類別會將其 rgb 屬性序列化為 JSON。
{"rgb":65280}
插件生成的序列化器
每個標記有 @Serializable 註解的類別(如上一個例子中的 Color 類別)都會由 Kotlin 序列化編譯器插件自動生成一個 KSerializer 介面的實例。我們可以使用類別的伴生對象上的 .serializer() 函數來檢索此實例。
我們可以檢查其 descriptor 屬性,它描述了序列化類別的結構。我們會在後續章節中詳細了解這一點。
fun main() {
val colorSerializer: KSerializer<Color> = Color.serializer()
println(colorSerializer.descriptor)
}
輸出:
Color(rgb: kotlin.Int)
當 Color 類別本身被序列化時,或當它被用作其他類別的屬性時,Kotlin 序列化框架會自動檢索並使用此序列化器。
你無法在可序列化類別的伴生對象上自定義自己的 serializer() 函數。
插件生成的泛型序列化器
對於泛型類別,如 "泛型類別" 章節中展示的 Box 類別,自動生成的 .serializer() 函數接受的參數數量與對應類別中的類型參數數量相同。這些參數的類型是 KSerializer,因此在構建泛型類別的序列化器實例時,必須提供實際類型參數的序列化器。
@Serializable
@SerialName("Box")
class Box<T>(val contents: T)
fun main() {
val boxedColorSerializer = Box.serializer(Color.serializer())
println(boxedColorSerializer.descriptor)
}
我們可以看到,已經實例化了一個序列化器來序列化具體的 Box<Color>。
Box(contents: Color)
內建的基本序列化器
內建類別的基本序列化器可以通過 .serializer() 擴展函數來檢索。
fun main() {
val intSerializer: KSerializer<Int> = Int.serializer()
println(intSerializer.descriptor)
}
構建集合序列化器
當需要時,內建集合的序列化器必須通過對應的函數如 ListSerializer()、SetSerializer()、MapSerializer() 等顯式構建。這些類別是泛型的,因此要實例化它們的序列化器,我們必須為其類型參數提供相應的序列化器。例如,我們可以如下生成一個 List<String> 的序列化器。
fun main() {
val stringListSerializer: KSerializer<List<String>> = ListSerializer(String.serializer())
println(stringListSerializer.descriptor)
}
使用頂級序列化器函數
當不確定時,你可以隨時使用頂級泛型 serializer<T>() 函數來檢索源代碼中任意 Kotlin 類型的序列化器。
@Serializable
@SerialName("Color")
class Color(val rgb: Int)
fun main() {
val stringToColorMapSerializer: KSerializer<Map<String, Color>> = serializer()
println(stringToColorMapSerializer.descriptor)
}
自定義序列化器
插件生成的序列化器非常方便,但對於像 Color 這樣的類別,它可能無法生成我們想要的 JSON。讓我們來研究一些替代方案。
基本序列化器
我們想將 Color 類別序列化為一個十六進制字串,其中綠色將被表示為 "00ff00"。為了實現這一點,我們需要編寫一個實現 KSerializer 介面的物件來處理 Color 類別。
object ColorAsStringSerializer : KSerializer<Color> {
override val descriptor: SerialDescriptor = PrimitiveSerialDescriptor("Color", PrimitiveKind.STRING)
override fun serialize(encoder: Encoder, value: Color) {
val string = value.rgb.toString(16).padStart(6, '0')
encoder.encodeString(string)
}
override fun deserialize(decoder: Decoder): Color {
val string = decoder.decodeString()
return Color(string.toInt(16))
}
}
序列化器包含三個必須的部分:
-
serialize函數實現了SerializationStrategy。它接收一個Encoder的實例和一個要序列化的值。它使用Encoder的encodeXxx函數來將值表示為一系列基本類型。在我們的例子中,使用了encodeString。 -
deserialize函數實現了DeserializationStrategy。它接收一個Decoder的實例並返回一個反序列化的值。它使用Decoder的decodeXxx函數來解碼對應的值。在我們的例子中,使用了decodeString。 -
descriptor屬性必須準確描述encodeXxx和decodeXxx函數的作用,以便格式實現能夠提前知道它們將調用哪些編碼/解碼方法。對於基本序列化,必須使用PrimitiveSerialDescriptor函數並為正在序列化的類型提供唯一的名稱。PrimitiveKind描述了實現中使用的特定encodeXxx/decodeXxx方法。
當 descriptor 與編碼/解碼方法不對應時,結果代碼的行為是未定義的,可能會在未來的更新中隨機更改。
下一步是將序列化器綁定到類別。這可以通過在 @Serializable 註解中添加 with 屬性來實現。
@Serializable(with = ColorAsStringSerializer::class)
class Color(val rgb: Int)
現在我們可以像以前一樣序列化 Color 類別了。
fun main() {
val green = Color(0x00ff00)
println(Json.encodeToString(green))
}
我們得到了我們想要的十六進制字串
的序列表示。
"00ff00"
反序列化也很簡單,因為我們實現了 deserialize 方法。
@Serializable(with = ColorAsStringSerializer::class)
class Color(val rgb: Int)
fun main() {
val color = Json.decodeFromString<Color>("\"00ff00\"")
println(color.rgb) // prints 65280
}
它也適用於我們序列化或反序列化具有 Color 屬性的不同類別。
@Serializable(with = ColorAsStringSerializer::class)
data class Color(val rgb: Int)
@Serializable
data class Settings(val background: Color, val foreground: Color)
fun main() {
val data = Settings(Color(0xffffff), Color(0))
val string = Json.encodeToString(data)
println(string)
require(Json.decodeFromString<Settings>(string) == data)
}
兩個 Color 屬性都被序列化為字串。
{"background":"ffffff","foreground":"000000"}
委派序列化器
在前面的例子中,我們將 Color 類別表示為字串。字串被認為是一種基本類型,因此我們使用了 PrimitiveClassDescriptor 和專門的 encodeString 方法。現在讓我們看看如果我們需要將 Color 序列化為另一種非基本類型(例如 IntArray),我們的操作會是什麼。
KSerializer 的實現將在 Color 和 IntArray 之間進行轉換,但實際的序列化邏輯將委派給 IntArraySerializer,使用 encodeSerializableValue 和 decodeSerializableValue。
import kotlinx.serialization.builtins.IntArraySerializer
class ColorIntArraySerializer : KSerializer<Color> {
private val delegateSerializer = IntArraySerializer()
override val descriptor = SerialDescriptor("Color", delegateSerializer.descriptor)
override fun serialize(encoder: Encoder, value: Color) {
val data = intArrayOf(
(value.rgb shr 16) and 0xFF,
(value.rgb shr 8) and 0xFF,
value.rgb and 0xFF
)
encoder.encodeSerializableValue(delegateSerializer, data)
}
override fun deserialize(decoder: Decoder): Color {
val array = decoder.decodeSerializableValue(delegateSerializer)
return Color((array[0] shl 16) or (array[1] shl 8) or array[2])
}
}
注意,這裡我們不能使用預設的 Color.serializer().descriptor,因為依賴於架構的格式可能會認為我們會調用 encodeInt 而不是 encodeSerializableValue。同樣,我們也不能直接使用 IntArraySerializer().descriptor,否則處理整數數組的格式將無法區分值是 IntArray 還是 Color。不用擔心,當序列化實際的底層整數數組時,這個優化仍然會起作用。
我們現在可以使用這個序列化器:
@Serializable(with = ColorIntArraySerializer::class)
class Color(val rgb: Int)
fun main() {
val green = Color(0x00ff00)
println(Json.encodeToString(green))
}
正如您所見,這種數組表示在 JSON 中不是很有用,但在與 ByteArray 和二進制格式一起使用時可能會節省一些空間。
[0,255,0]
通過代理實現複合序列化器
現在我們的挑戰是讓 Color 被序列化,這樣它在 JSON 中被表示為一個具有三個屬性(r、g 和 b)的類別,從而讓 JSON 將其編碼為物件。實現這一目標的最簡單方法是定義一個模擬 Color 序列化形式的代理類別,然後將其用作 Color 的序列化器。我們還可以將這個代理類別的 SerialName 設置為 Color。然後,如果任何格式使用此名稱,代理看起來就像是一個 Color 類別。代理類別可以是私有的,並且可以在其 init 區塊中強制執行所有關於類別序列表示的約束。
@Serializable
@SerialName("Color")
private class ColorSurrogate(val r: Int, val g: Int, val b: Int) {
init {
require(r in 0..255 && g in 0..255 && b in 0..255)
}
}
現在我們可以使用 ColorSurrogate.serializer() 函數來檢索為代理類別自動生成的序列化器。
我們可以像在委派序列化器中那樣使用相同的方法,但這次,我們完全重用了為代理類別自動生成的 SerialDescriptor,因為它應該與原始類別無法區分。
object ColorSerializer : KSerializer<Color> {
override val descriptor: SerialDescriptor = ColorSurrogate.serializer().descriptor
override fun serialize(encoder: Encoder, value: Color) {
val surrogate = ColorSurrogate((value.rgb shr 16) and 0xff, (value.rgb shr 8) and 0xff, value.rgb and 0xff)
encoder.encodeSerializableValue(ColorSurrogate.serializer(), surrogate)
}
override fun deserialize(decoder: Decoder): Color {
val surrogate = decoder.decodeSerializableValue(ColorSurrogate.serializer())
return Color((surrogate.r shl 16) or (surrogate.g shl 8) or surrogate.b)
}
}
我們將 ColorSerializer 序列化器綁定到 Color 類別。
@Serializable(with = ColorSerializer::class)
class Color(val rgb: Int)
現在我們可以享受 Color 類別序列化的結果了。
{"r":0,"g":255,"b":0}
手寫的複合序列化器
有些情況下,代理解決方案並不適用。可能我們想避免額外分配的性能影響,或者我們希望為最終的序列化表示提供一組可配置/動態屬性。在這些情況下,我們需要手動編寫一個模仿生成的序列化器行為的類別序列化器。
object ColorAsObjectSerializer : KSerializer<Color> {
讓我們逐步介紹它。首先,使用 buildClassSerialDescriptor 構建器定義一個 descriptor。在構建器的 DSL 中,element 函數會根據其類型自動檢索對應字段的序列化器。元素的順序很重要。它們從零開始編號。
override val descriptor: SerialDescriptor =
buildClassSerialDescriptor("Color") {
element<Int>("r")
element<Int>("g")
element<Int>("b")
}
這裡的 "element" 是一個通用術語。descriptor 的元素取決於其 SerialKind。類別描述符的元素是其屬性,枚舉描述符的元素是其案例,等等。
接著,我們使用 encodeStructure DSL 編寫 serialize 函數,它在其區塊中提供對 CompositeEncoder 的訪問。Encoder 和 CompositeEncoder 之間的區別在於後者具有對應於前者的 encodeXxx 函數的 encodeXxxElement 函數。它們必須按與 descriptor 中相同的順序調用。
override fun serialize(encoder: Encoder, value: Color) =
encoder.encodeStructure(descriptor) {
encodeIntElement(descriptor, 0, (value.rgb shr 16) and 0xff)
encodeIntElement(descriptor, 1, (value.rgb shr 8) and 0xff)
encodeIntElement(descriptor, 2, value.rgb and 0xff)
}
最複雜的部分是 deserialize 函數。它必須支持像 JSON 這樣可以以任意順序解碼屬性的格式。它以調用 decodeStructure 開始,從而獲得 CompositeDecoder 的訪問權限。在內部,我們編寫了一個循環,該循環反覆調用 decodeElementIndex 來解碼下一個元素的索引,然後使用我們的示例中的 decodeIntElement 解碼相應的元素,最後當遇到 CompositeDecoder.DECODE_DONE 時終止循環。
override fun deserialize(decoder: Decoder): Color =
decoder.decodeStructure(descriptor) {
var r = -1
var g = -1
var b =
-1
while (true) {
when (val index = decodeElementIndex(descriptor)) {
0 -> r = decodeIntElement(descriptor, 0)
1 -> g = decodeIntElement(descriptor, 1)
2 -> b = decodeIntElement(descriptor, 2)
CompositeDecoder.DECODE_DONE -> break
else -> error("Unexpected index: $index")
}
}
require(r in 0..255 && g in 0..255 && b in 0..255)
Color((r shl 16) or (g shl 8) or b)
}
現在,我們將最終的序列化器綁定到 Color 類別並測試其序列化/反序列化。
@Serializable(with = ColorAsObjectSerializer::class)
data class Color(val rgb: Int)
fun main() {
val color = Color(0x00ff00)
val string = Json.encodeToString(color)
println(string)
require(Json.decodeFromString<Color>(string) == color)
}
與之前一樣,我們得到了以具有三個鍵的 JSON 物件表示的 Color 類別:
{"r":0,"g":255,"b":0}
順序解碼協議(實驗性)
前一部分中的 deserialize 函數的實現適用於任何格式。然而,有些格式無論何時都會按順序存儲所有複雜數據,或者有時這樣做(例如,JSON 始終按順序存儲集合)。對於這些格式來說,在循環中調用 decodeElementIndex 的複雜協議並不是必需的,如果 CompositeDecoder.decodeSequentially 函數返回 true,則可以使用更快的實現。插件生成的序列化器實際上在概念上類似於以下代碼。
override fun deserialize(decoder: Decoder): Color =
decoder.decodeStructure(descriptor) {
var r = -1
var g = -1
var b = -1
if (decodeSequentially()) { // sequential decoding protocol
r = decodeIntElement(descriptor, 0)
g = decodeIntElement(descriptor, 1)
b = decodeIntElement(descriptor, 2)
} else while (true) {
when (val index = decodeElementIndex(descriptor)) {
0 -> r = decodeIntElement(descriptor, 0)
1 -> g = decodeIntElement(descriptor, 1)
2 -> b = decodeIntElement(descriptor, 2)
CompositeDecoder.DECODE_DONE -> break
else -> error("Unexpected index: $index")
}
}
require(r in 0..255 && g in 0..255 && b in 0..255)
Color((r shl 16) or (g shl 8) or b)
}
序列化第三方類別
有時應用程式必須處理一個不可序列化的外部類型。我們以 java.util.Date 為例。如前所述,我們從為該類別編寫 KSerializer 的實現開始。我們的目標是將 Date 序列化為一個長整數,表示自 Unix 紀元以來的毫秒數,這與 "基本序列化器" 章節中的方法類似。
在接下來的章節中,任何類型的 Date 序列化器都可以工作。例如,如果我們希望將 Date 序列化為一個物件,我們可以使用 "通過代理實現複合序列化器" 章節中的方法。 如果您需要序列化一個本應可序列化但實際不可序列化的第三方 Kotlin 類別,請參閱 "為另一個 Kotlin 類別衍生外部序列化器(實驗性)"。
object DateAsLongSerializer : KSerializer<Date> {
override val descriptor: SerialDescriptor = PrimitiveSerialDescriptor("Date", PrimitiveKind.LONG)
override fun serialize(encoder: Encoder, value: Date) = encoder.encodeLong(value.time)
override fun deserialize(decoder: Decoder): Date = Date(decoder.decodeLong())
}
我們無法通過 @Serializable 註解將 DateAsLongSerializer 序列化器綁定到 Date 類別,因為我們無法控制 Date 的源代碼。這裡有幾種解決方法。
手動傳遞序列化器
所有的 encodeToXxx 和 decodeFromXxx 函數都有一個帶有第一個序列化器參數的重載版本。當一個不可序列化的類別(如 Date)是正在序列化的頂級類別時,我們可以使用這些重載版本。
fun main() {
val kotlin10ReleaseDate = SimpleDateFormat("yyyy-MM-ddX").parse("2016-02-15+00")
println(Json.encodeToString(DateAsLongSerializer, kotlin10ReleaseDate))
}
輸出:
1455494400000
為屬性指定序列化器
當不可序列化類別(如 Date)的屬性作為可序列化類別的一部分被序列化時,我們必須為其提供序列化器,否則代碼將無法編譯。這可以通過在屬性上使用 @Serializable 註解來實現。
@Serializable
class ProgrammingLanguage(
val name: String,
@Serializable(with = DateAsLongSerializer::class)
val stableReleaseDate: Date
)
fun main() {
val data = ProgrammingLanguage("Kotlin", SimpleDateFormat("yyyy-MM-ddX").parse("2016-02-15+00"))
println(Json.encodeToString(data))
}
stableReleaseDate 屬性將使用我們為其指定的序列化策略進行序列化:
{"name":"Kotlin","stableReleaseDate":1455494400000}
為特定類型指定序列化器
@Serializable 註解也可以直接應用於類型。當需要為像 Date 這樣的類型提供自定義序列化器時,這非常方便。最常見的用例是當你有一個日期列表時:
@Serializable
class ProgrammingLanguage(
val name: String,
val releaseDates: List<@Serializable(DateAsLongSerializer::class) Date>
)
fun main() {
val df = SimpleDateFormat("yyyy-MM-ddX")
val data = ProgrammingLanguage("Kotlin", listOf(df.parse("2023-07-06+00"), df.parse("2023-04-25+00"), df.parse("2022-12-28+00")))
println(Json.encodeToString(data))
}
輸出:
{"name":"Kotlin","releaseDates":[1688601600000,1682380800000,1672185600000]}
為檔案指定序列化器
可以通過在檔案開頭使用檔案級別的 UseSerializers 註解來為整個檔案中的特定類型(如 Date)指定序列化器。
@file:UseSerializers(DateAsLongSerializer::class)
現在可以在可序列化類別中使用 Date 屬性,而不需要額外的註解。
@Serializable
class ProgrammingLanguage(val name: String, val stableReleaseDate: Date)
fun main() {
val data = ProgrammingLanguage("Kotlin", SimpleDateFormat("yyyy-MM-ddX").parse("2016-02-15+00"))
println(Json.encodeToString(data))
}
輸出:
{"name":"Kotlin","stableReleaseDate":1455494400000}
使用型別別名全局指定序列化器
在處理序列化策略時,kotlinx.serialization 傾向於成為始終顯式的框架:通常,應在 @Serializable 註解中明確提到它們。因此,我們不提供任何類型的全局序列化器配置(除非後面提到的上下文序列化器)。
然而,在有大量檔案和類別的專案中,每次指定 @file:UseSerializers 可能太過繁瑣,尤其是對於像 Date 或 Instant 這樣在專案中有固定序列化策略的類別。對於這些情況,可以使用型別別名指定序列化器,因為它們會保留註解,包括與序列化相關的註解:
typealias DateAsLong = @Serializable(DateAsLongSerializer::class) Date
typealias
DateAsText = @Serializable(DateAsSimpleTextSerializer::class) Date
使用這些新的不同類型,可以在沒有額外註解的情況下序列化 Date:
@Serializable
class ProgrammingLanguage(val stableReleaseDate: DateAsText, val lastReleaseTimestamp: DateAsLong)
fun main() {
val format = SimpleDateFormat("yyyy-MM-ddX")
val data = ProgrammingLanguage(format.parse("2016-02-15+00"), format.parse("2022-07-07+00"))
println(Json.encodeToString(data))
}
輸出:
{"stableReleaseDate":"2016-02-15","lastReleaseTimestamp":1657152000000}
泛型類型的自定義序列化器
讓我們看一下泛型 Box<T> 類別的例子。我們計劃為其編寫一個自定義序列化策略,因此將其標記為 @Serializable(with = BoxSerializer::class)。
@Serializable(with = BoxSerializer::class)
data class Box<T>(val contents: T)
為常規類型編寫 KSerializer 的實現就像我們在本章中的 Color 類型例子中所見那樣,作為一個 object 來處理。而對於泛型類別的序列化器,它需要一個構造函數,該構造函數接受與類型具有的泛型參數數量相同的 KSerializer 參數。讓我們編寫一個 Box<T> 序列化器,在序列化過程中擦除自身,並將所有工作委派給其 data 屬性的底層序列化器。
class BoxSerializer<T>(private val dataSerializer: KSerializer<T>) : KSerializer<Box<T>> {
override val descriptor: SerialDescriptor = dataSerializer.descriptor
override fun serialize(encoder: Encoder, value: Box<T>) = dataSerializer.serialize(encoder, value.contents)
override fun deserialize(decoder: Decoder) = Box(dataSerializer.deserialize(decoder))
}
現在我們可以序列化和反序列化 Box<Project>。
@Serializable
data class Project(val name: String)
fun main() {
val box = Box(Project("kotlinx.serialization"))
val string = Json.encodeToString(box)
println(string)
println(Json.decodeFromString<Box<Project>>(string))
}
生成的 JSON 看起來像是直接序列化了 Project 類別。
{"name":"kotlinx.serialization"}
Box(contents=Project(name=kotlinx.serialization))
特定格式的序列化器
上述自定義序列化器對每種格式的工作方式相同。然而,可能存在格式特定的功能,序列化器實現可能希望利用這些功能。
"JSON 轉換" 章節提供了利用 JSON 特定功能的序列化器範例。
格式實現可以有針對某種類型的格式特定表示,如 "替代和自定義格式(實驗性)" 章節中的 "格式特定類型" 所解釋的。
本章接下來將介紹根據上下文調整序列化策略的通用方法。
上下文序列化
之前所有的自定義序列化策略都是靜態的,即在編譯時完全定義。例外情況是 "手動傳遞序列化器" 方法,但它僅適用於頂級物件。你可能需要在執行時更改深層物件樹中的物件的序列化策略,策略的選擇是基於上下文的。例如,你可能希望根據序列化資料的協議版本在 JSON 格式中將 java.util.Date 表示為 ISO 8601 字串或長整數。這就是所謂的上下文序列化,並且它由內建的 ContextualSerializer 類別支持。通常我們不需要顯式使用這個序列化器類別——可以使用 @Contextual 註解作為 @Serializable(with = ContextualSerializer::class) 註解的快捷方式,或者可以像 UseSerializers 註解那樣在檔案級別使用 UseContextualSerialization 註解。讓我們看一個利用前者的範例。
@Serializable
class ProgrammingLanguage(
val name: String,
@Contextual
val stableReleaseDate: Date
)
要實際序列化這個類別,我們必須在調用 encodeToXxx/decodeFromXxx 函數時提供對應的上下文。否則,我們將得到 "Serializer for class 'Date' is not found" 的異常。
序列化器模組
要提供上下文,我們需要定義一個 SerializersModule 實例,該實例描述了在執行時應該使用哪些序列化器來序列化哪些上下文可序列化類別。這可以使用 SerializersModule {} 構建函數完成,該函數提供了 SerializersModuleBuilder DSL 來註冊序列化器。在下面的範例中,我們使用了帶有序列化器的 contextual 函數。對應的類別將通過內聯類型參數自動獲取該序列化器。
private val module = SerializersModule {
contextual(DateAsLongSerializer)
}
接下來,我們使用 Json {} 構建函數和 serializersModule 屬性創建一個帶有這個模組的 JSON 格式實例。
關於自定義 JSON 配置的詳細信息可以在 "JSON 配置" 章節中找到。
val format = Json { serializersModule = module }
現在我們可以使用這個格式序列化我們的資料。
fun main() {
val data = ProgrammingLanguage("Kotlin", SimpleDateFormat("yyyy-MM-ddX").parse("2016-02-15+00"))
println(format.encodeToString(data))
}
輸出:
{"name":"Kotlin","stableReleaseDate":1455494400000}
上下文序列化與泛型類別
在上一節中,我們看到可以在模組中註冊序列化器實例,以便上下文中序列化我們想要的類別。我們還知道泛型類別的序列化器具有構造函數參數——類型參數序列化器。這意味著我們不能為類別使用一個序列化器實例,如果這個類別是泛型的:
val incorrectModule = SerializersModule {
// 只能序列化 Box<Int>,而不能序列化 Box<String> 或其他類型
contextual(BoxSerializer(Int.serializer()))
}
當我們想要上下文序列化泛型類別時,可以在模組中註冊提供者:
val correctModule = SerializersModule {
// args[0] 包含 Int.serializer() 或 String.serializer(),具體取決於使用情況
contextual(Box::class) { args -> BoxSerializer(args[0]) }
}
關於序列化模組的額外細節可以在 "多型性" 章節的 "合併庫序列化模組" 部分中找到。
為其他 Kotlin 類別衍生外部序列化器(實驗性)
如果要序列化的第三方類別是具有僅包含屬性的主要構造函數的 Kotlin 類別(這種類別本可以標記為 @Serializable),那麼您可以使用 Serializer 註解並在物件上設置 forClass 屬性來為其生成一個外部序列化器。
// NOT @Serializable
class Project(val name: String, val language: String)
@Serializer(forClass = Project::class)
object ProjectSerializer
您必須使用本章中解釋的一種方法將此序列化器綁定到類別。我們將按照 "手動傳遞序列化器" 方法進行此示例。
fun main() {
val data = Project("kotlinx.serialization", "Kotlin")
println(Json.encodeToString(ProjectSerializer, data))
}
這將所有的 Project 屬性序列化:
{"name":"kotlinx.serialization","language":"Kotlin"}
外部序列化使用屬性
正如我們之前看到的,常規 @Serializable 註解會創建一個序列化器,以便序列化備援欄位。使用 Serializer(forClass = ...) 的外部序列化無法訪問備援欄位,因此其工作方式不同。它僅
序列化具有 setter 的可訪問屬性或屬於主要構造函數的屬性。以下範例展示了這一點。
// NOT @Serializable, will use external serializer
class Project(
// val in a primary constructor -- serialized
val name: String
) {
var stars: Int = 0 // property with getter & setter -- serialized
val path: String // getter only -- not serialized
get() = "kotlin/$name"
private var locked: Boolean = false // private, not accessible -- not serialized
}
@Serializer(forClass = Project::class)
object ProjectSerializer
fun main() {
val data = Project("kotlinx.serialization").apply { stars = 9000 }
println(Json.encodeToString(ProjectSerializer, data))
}
輸出如下:
{"name":"kotlinx.serialization","stars":9000}
下一章將介紹多型性。
CH4 多型性
這是《Kotlin 序列化指南》的第四章。本章將介紹 Kotlin 序列化如何處理多型性類別層次結構。
目錄
- 閉合多型性
- 靜態類型
- 設計可序列化的層次結構
- 密封類別
- 自訂子類別序列名稱
- 基類中的具體屬性
- 物件
- 開放多型性
- 註冊子類別
- 序列化介面
- 介面類型的屬性
- 用於多型性的靜態父類型查找
- 明確標記多型性類別屬性
- 註冊多個超類別
- 多型性與泛型類別
- 合併庫序列化模組
- 用於反序列化的預設多型性類型處理程序
- 用於序列化的預設多型性類型處理程序
閉合多型性
讓我們從多型性的基本介紹開始。
靜態類型
Kotlin 序列化在預設情況下是完全靜態的。編碼物件的結構由物件的編譯時期類型決定。讓我們更詳細地探討這一點,並學習如何序列化多型性資料結構,其中資料的類型在運行時期確定。
為了展示 Kotlin 序列化的靜態性質,讓我們進行以下設置。一個開放類別 Project 只有 name 屬性,而其派生類別 OwnedProject 則增加了一個 owner 屬性。在下面的例子中,我們將序列化一個靜態類型為 Project 的變數 data,該變數在運行時期被初始化為 OwnedProject 的實例。
@Serializable
open class Project(val name: String)
class OwnedProject(name: String, val owner: String) : Project(name)
fun main() {
val data: Project = OwnedProject("kotlinx.coroutines", "kotlin")
println(Json.encodeToString(data))
}
儘管運行時期的類型是 OwnedProject,但只有 Project 類別的屬性被序列化。
{"name":"kotlinx.coroutines"}
讓我們將 data 的編譯時期類型更改為 OwnedProject。
@Serializable
open class Project(val name: String)
class OwnedProject(name: String, val owner: String) : Project(name)
fun main() {
val data = OwnedProject("kotlinx.coroutines", "kotlin")
println(Json.encodeToString(data))
}
我們會得到一個錯誤,因為 OwnedProject 類別不可序列化。
Exception in thread "main" kotlinx.serialization.SerializationException: Serializer for class 'OwnedProject' is not found.
Please ensure that class is marked as '@Serializable' and that the serialization compiler plugin is applied.
設計可序列化的層次結構
我們不能簡單地將前面例子中的 OwnedProject 標記為 @Serializable。這樣會導致編譯失敗,因為不符合構造函數屬性的要求。要使類別的層次結構可序列化,父類別中的屬性必須標記為抽象,使 Project 類別也成為抽象類別。
@Serializable
abstract class Project {
abstract val name: String
}
class OwnedProject(override val name: String, val owner: String) : Project()
fun main() {
val data: Project = OwnedProject("kotlinx.coroutines", "kotlin")
println(Json.encodeToString(data))
}
這接近於設計可序列化類別層次結構的最佳方案,但運行時會產生以下錯誤:
Exception in thread "main" kotlinx.serialization.SerializationException: Serializer for subclass 'OwnedProject' is not found in the polymorphic scope of 'Project'.
Check if class with serial name 'OwnedProject' exists and serializer is registered in a corresponding SerializersModule.
To be registered automatically, class 'OwnedProject' has to be '@Serializable', and the base class 'Project' has to be sealed and '@Serializable'.
密封類別
使用多型性層次結構進行序列化的最簡單方法是將基類標記為密封類別。密封類別的所有子類別必須顯式標記為 @Serializable。
@Serializable
sealed class Project {
abstract val name: String
}
@Serializable
class OwnedProject(override val name: String, val owner: String) : Project()
fun main() {
val data: Project = OwnedProject("kotlinx.coroutines", "kotlin")
println(Json.encodeToString(data)) // Serializing data of compile-time type Project
}
現在,我們可以看到在 JSON 中表示多型性的預設方式。類型鍵作為識別符被添加到生成的 JSON 物件中。
{"type":"example.examplePoly04.OwnedProject","name":"kotlinx.coroutines","owner":"kotlin"}
注意上例中與靜態類型相關的一個小但非常重要的細節:val data 屬性的編譯時期類型是 Project,儘管其運行時期類型是 OwnedProject。在序列化多型性類別層次結構時,你必須確保序列化物件的編譯時期類型是多型性的,而不是具體的。
讓我們看看如果將範例稍微更改,使被序列化物件的編譯時期類型為 OwnedProject(與其運行時期類型相同)會發生什麼。
@Serializable
sealed class Project {
abstract val name: String
}
@Serializable
class OwnedProject(override val name: String, val owner: String) : Project()
fun main() {
val data = OwnedProject("kotlinx.coroutines", "kotlin") // data: OwnedProject here
println(Json.encodeToString(data)) // Serializing data of compile-time type OwnedProject
}
OwnedProject 的類型是具體的而不是多型性的,因此類型識別符屬性不會被寫入生成的 JSON。
{"name":"kotlinx.coroutines","owner":"kotlin"}
一般來說,Kotlin 序列化設計為僅在序列化期間使用的編譯時期類型與反序列化期間使用的編譯時期類型相同時,才能正常工作。你可以在調用序列化函數時始終顯式指定類型。可以通過調用 Json.encodeToString<Project>(data) 修正前面的範例以使用 Project 類型進行序列化。
自訂子類別序列名稱
類型鍵的值默認是完整的類別名稱。我們可以將 SerialName 註解放在對應的類別上來更改它。
@Serializable
sealed class Project {
abstract val name: String
}
@Serializable
@SerialName("owned")
class OwnedProject(override val name: String, val owner: String) : Project()
fun main() {
val data: Project = OwnedProject("kotlinx.coroutines", "kotlin")
println(Json.encodeToString(data))
}
這樣,我們就可以擁有一個穩定的序列名稱,不會受源代碼中類別名稱的影響。
{"type":"owned","name":"kotlinx.coroutines","owner":"kotlin"}
此外,JSON 可以配置為使用不同的鍵名稱作為類別識別符。在 "用於多型性的類別識別符" 章節中可以找到一個範例。
基類中的具體屬性
密封層次結構中的基類可以具有具有備援字段的屬性。
@Serializable
sealed class Project {
abstract val name: String
var status = "open"
}
@Serializable
@SerialName("owned")
class OwnedProject(override val name: String, val owner: String) : Project()
fun main() {
val json = Json { encodeDefaults = true } // "status" will be skipped otherwise
val data: Project = OwnedProject("kotlinx.coroutines", "kotlin")
println(json.encodeToString(data))
}
超類別的屬性在子類別的屬性之前被序列化。
{"type":"owned","status":"open","name":"kotlinx.coroutines","owner":"kotlin"}
####
物件
密封層次結構可以將物件作為其子類別,它們也需要標記為 @Serializable。讓我們來看一個不同的例子,其中有一個 Response 類別的層次結構。
@Serializable
sealed class Response
@Serializable
object EmptyResponse : Response()
@Serializable
class TextResponse(val text: String) : Response()
讓我們序列化一個包含不同響應的列表。
fun main() {
val list = listOf(EmptyResponse, TextResponse("OK"))
println(Json.encodeToString(list))
}
物件被序列化為一個空類別,預設也使用其完整類別名稱作為類型。
[{"type":"example.examplePoly08.EmptyResponse"},{"type":"example.examplePoly08.TextResponse","text":"OK"}]
即使物件有屬性,它們也不會被序列化。
開放多型性
序列化可以處理任意開放的類別或抽象類別。然而,由於這種多型性是開放的,因此子類別可能在源代碼中的任何地方定義,甚至在其他模組中,序列化的子類別列表無法在編譯時期確定,必須在運行時期顯式註冊。
註冊子類別
讓我們從 "設計可序列化的層次結構" 章節的代碼開始。要使其在不將其標記為密封類別的情況下正常工作,我們必須使用 SerializersModule {} 構建函數定義一個 SerializersModule。在模組中,基類在 polymorphic 構建器中指定,並使用 subclass 函數註冊每個子類別。現在,可以使用這個模組實例化一個自定義的 JSON 配置並用於序列化。
val module = SerializersModule {
polymorphic(Project::class) {
subclass(OwnedProject::class)
}
}
val format = Json { serializersModule = module }
@Serializable
abstract class Project {
abstract val name: String
}
@Serializable
@SerialName("owned")
class OwnedProject(override val name: String, val owner: String) : Project()
fun main() {
val data: Project = OwnedProject("kotlinx.coroutines", "kotlin")
println(format.encodeToString(data))
}
這個附加的配置使我們的代碼像在 "密封類別" 章節中那樣工作,但這裡的子類別可以隨意地分佈在代碼中。
{"type":"owned","name":"kotlinx.coroutines","owner":"kotlin"}
請注意,這個例子僅在 JVM 上有效,因為序列化函數有一些限制。對於 JS 和 Native,應使用顯式序列化器:format.encodeToString(PolymorphicSerializer(Project::class), data)。你可以在此處跟蹤這個問題。
序列化介面
我們可以更新前面的範例,將 Project 超類別更改為介面。然而,我們不能將介面本身標記為 @Serializable。沒關係,介面不能自己擁有實例。介面只能由其派生類別的實例表示。介面在 Kotlin 語言中用於實現多型性,因此所有介面在默認情況下被視為隱式可序列化的,並且使用 PolymorphicSerializer 策略。我們只需要標記其實現類別為 @Serializable 並註冊它們。
interface Project {
val name: String
}
@Serializable
@SerialName("owned")
class OwnedProject(override val name: String, val owner: String) : Project
現在,如果我們將 data 聲明為 Project 類型,就可以像以前一樣簡單地調用 format.encodeToString。
fun main() {
val data: Project = OwnedProject("kotlinx.coroutines", "kotlin")
println(format.encodeToString(data))
}
{"type":"owned","name":"kotlinx.coroutines","owner":"kotlin"}
注意:在 Kotlin/Native 上,由於反射能力有限,應使用 format.encodeToString(PolymorphicSerializer(Project::class), data))。
介面類型的屬性
繼續前面的範例,讓我們看看如果在某個其他可序列化類別中使用 Project 介面作為屬性會發生什麼。介面是隱式多型的,因此我們可以只聲明一個介面類型的屬性。
@Serializable
class Data(val project: Project) // Project is an interface
fun main() {
val data = Data(OwnedProject("kotlinx.coroutines", "kotlin"))
println(format.encodeToString(data))
}
只要我們在格式的 SerializersModule 中註冊了實際序列化的介面子類型,它就能在運行時正常工作。
{"project":{"type":"owned","name":"kotlinx.coroutines","owner":"kotlin"}}
用於多型性的靜態父類型查找
在序列化多型性類別時,多型性層次結構的根類型(在我們的例子中是 Project)是靜態確定的。讓我們舉一個具有可序列化的抽象類別 Project 的例子,但將 main 函數中的 data 聲明為 Any 類型:
fun main() {
val data: Any = OwnedProject("kotlinx.coroutines", "kotlin")
println(format.encodeToString(data))
}
我們會得到異常:
Exception in thread "main" kotlinx.serialization.SerializationException: Serializer for class 'Any' is not found.
Please ensure that class is marked as '@Serializable' and that the serialization compiler plugin is applied.
我們必須根據我們在源代碼中使用的對應靜態類型來註冊類別以進行多型性序列化。首先,我們更改模組以註冊 Any 的子類別:
val module = SerializersModule {
polymorphic(Any::class) {
subclass(OwnedProject::class)
}
}
然後我們可以嘗試序列化 Any 類型的變數:
fun main() {
val data: Any = OwnedProject("kotlinx.coroutines", "kotlin")
println(format.encodeToString(data))
}
然而,Any 是一個類別,它是不可序列化的:
Exception in thread "main" kotlinx.serialization.SerializationException: Serializer for class 'Any' is not found.
Please ensure that class is marked as '@Serializable' and that the serialization compiler plugin is applied.
我們必須顯式傳遞 PolymorphicSerializer 的實例(基類為 Any)作為 encodeToString 函數的第一個參數。
fun main() {
val data: Any = OwnedProject("kotlinx.coroutines", "kotlin")
println(format.encodeToString(PolymorphicSerializer(Any::class), data))
}
使用顯式序列化器,它像以前一樣工作。
{"type":"owned","name":"kotlinx.coroutines","owner":"kotlin"}
明確標記多型性類別屬性
介面類型的屬性被隱式認為是多型性的,因為介面是關於運行時期多型性的。然而,Kotlin 序列化不會編譯具有不可序列化類別類型屬性的可序列化類別。如果我們有一個 Any 類別或其他不可序列化類別的屬性,那麼我們必須顯式提供其序列化策略,如我們在 "為屬性指定序列化器" 章節中所見。要指定屬性的多型性序列化策略,使用特殊的 @Polymorphic 註解。
@Serializable
class Data(
@Polymorphic // the code does not compile without it
val project: Any
)
fun main() {
val data = Data(OwnedProject("kotlinx.coroutines", "kotlin"))
println(format.encodeToString(data))
}
註冊多個超類別
當同一類別作為不同超類別列表中的屬性的值被序列化時,我們必須在 SerializersModule 中分別為每個超類別註冊它。可以方便地將所有子類別的註冊提
取到一個單獨的函數中,並將其用於每個超類別。你可以使用以下模板來編寫它。
val module = SerializersModule {
fun PolymorphicModuleBuilder<Project>.registerProjectSubclasses() {
subclass(OwnedProject::class)
}
polymorphic(Any::class) { registerProjectSubclasses() }
polymorphic(Project::class) { registerProjectSubclasses() }
}
多型性與泛型類別
對於可序列化類別的泛型子類型需要特殊處理。考慮以下層次結構:
@Serializable
abstract class Response<out T>
@Serializable
@SerialName("OkResponse")
data class OkResponse<out T>(val data: T) : Response<T>()
Kotlin 序列化沒有內建的策略來表示序列化多型性類型 OkResponse<T> 的屬性時實際提供的參數類型 T。我們必須在定義 Response 的序列化器模組時顯式提供此策略。在下面的範例中,我們使用 OkResponse.serializer(...) 來檢索 OkResponse 類別的插件生成的泛型序列化器,並使用 PolymorphicSerializer 的實例(基類為 Any)進行實例化。通過這種方式,我們可以序列化 OkResponse 的實例,該實例具有任何已作為 Any 的子類型多型性註冊的 data 屬性。
val responseModule = SerializersModule {
polymorphic(Response::class) {
subclass(OkResponse.serializer(PolymorphicSerializer(Any::class)))
}
}
合併庫序列化模組
當應用程式規模增長並拆分為源代碼模組時,將所有類別層次結構存儲在一個序列化器模組中可能會變得不方便。讓我們將 "Project" 層次結構的庫添加到前一節的代碼中。
val projectModule = SerializersModule {
fun PolymorphicModuleBuilder<Project>.registerProjectSubclasses() {
subclass(OwnedProject::class)
}
polymorphic(Any::class) { registerProjectSubclasses() }
polymorphic(Project::class) { registerProjectSubclasses() }
}
我們可以使用 plus 運算符將這兩個模組組合在一起,將它們合併,以便在同一個 Json 格式實例中使用它們。
你也可以在 SerializersModule {} DSL 中使用 include 函數。
val format = Json { serializersModule = projectModule + responseModule }
現在,這兩個層次結構中的類別可以一起序列化和反序列化。
fun main() {
// both Response and Project are abstract and their concrete subtypes are being serialized
val data: Response<Project> = OkResponse(OwnedProject("kotlinx.serialization", "kotlin"))
val string = format.encodeToString(data)
println(string)
println(format.decodeFromString<Response<Project>>(string))
}
生成的 JSON 是深度多型性的。
{"type":"OkResponse","data":{"type":"OwnedProject","name":"kotlinx.serialization","owner":"kotlin"}}
OkResponse(data=OwnedProject(name=kotlinx.serialization, owner=kotlin))
如果你正在編寫一個帶有抽象類別及其一些實現的庫或共享模組,可以為客戶端公開你自己的序列化器模組,這樣客戶端就可以將你的模組與他們的模組結合起來使用。
用於反序列化的預設多型性類型處理程序
當我們反序列化未註冊的子類別時會發生什麼?
fun main() {
println(format.decodeFromString<Project>("""
{"type":"unknown","name":"example"}
"""))
}
我們會得到以下異常:
Exception in thread "main" kotlinx.serialization.json.internal.JsonDecodingException: Unexpected JSON token at offset 0: Serializer for subclass 'unknown' is not found in the polymorphic scope of 'Project' at path: $
Check if class with serial name 'unknown' exists and serializer is registered in a corresponding SerializersModule.
當讀取靈活的輸入時,我們可能希望在這種情況下提供一些預設行為。例如,我們可以有一個 BasicProject 子類型來表示所有未知的 Project 子類型。
@Serializable
abstract class Project {
abstract val name: String
}
@Serializable
data class BasicProject(override val name: String, val type: String): Project()
@Serializable
@SerialName("OwnedProject")
data class OwnedProject(override val name: String, val owner: String) : Project()
我們使用 polymorphic { ... } DSL 中的 defaultDeserializer 函數註冊一個預設的反序列化器處理程序,該函數定義了一個策略,該策略將輸入中的類型字串映射到反序列化策略。在下面的範例中,我們沒有使用類型,而是始終返回 BasicProject 類別的插件生成的序列化器。
val module = SerializersModule {
polymorphic(Project::class) {
subclass(OwnedProject::class)
defaultDeserializer { BasicProject.serializer() }
}
}
使用這個模組,我們現在可以反序列化已註冊的 OwnedProject 實例和任何未註冊的實例。
val format = Json { serializersModule = module }
fun main() {
println(format.decodeFromString<List<Project>>("""
[
{"type":"unknown","name":"example"},
{"type":"OwnedProject","name":"kotlinx.serialization","owner":"kotlin"}
]
"""))
}
注意,BasicProject 還捕獲了其 type 屬性中的指定類型鍵。
[BasicProject(name=example, type=unknown), OwnedProject(name=kotlinx.serialization, owner=kotlin)]
我們使用了一個插件生成的序列化器作為預設序列化器,這意味著 "unknown" 資料的結構是事先知道的。在現實世界的 API 中,這種情況很少見。為此需要一個自定義的、結構化較少的序列化器。你將在未來的 "維護自定義 JSON 屬性" 章節中看到此類序列化器的範例。
用於序列化的預設多型性類型處理程序
有時你需要根據實例動態選擇用於多型性類型的序列化器,例如,如果你無法訪問完整的類型層次結構,或者它經常發生變化。對於這種情況,你可以註冊一個預設序列化器。
interface Animal {
}
interface Cat : Animal {
val catType: String
}
interface Dog : Animal {
val dogType: String
}
private class CatImpl : Cat {
override val catType: String = "Tabby"
}
private class DogImpl : Dog {
override val dogType: String = "Husky"
}
object AnimalProvider {
fun createCat(): Cat = CatImpl()
fun createDog(): Dog = DogImpl()
}
我們使用 SerializersModule { ... } DSL 中的 polymorphicDefaultSerializer 函數註冊一個預設序列化器處理程序,該函數定義了一個策略,該策略接受基類的實例並提供一個序列化策略。在下面的範例中,我們使用 when 區塊來檢查實例的類型,而無需引用私有實現類別。
val module = SerializersModule {
polymorphicDefaultSerializer(Animal::class) { instance ->
@Suppress("UNCHECKED_CAST")
when (instance) {
is Cat -> CatSerializer as SerializationStrategy<Animal>
is Dog -> DogSerializer as SerializationStrategy<Animal>
else -> null
}
}
}
object CatSerializer : SerializationStrategy<Cat> {
override val descriptor = buildClassSerialDescriptor("Cat") {
element<String>("catType")
}
override fun serialize(encoder: Encoder, value: Cat) {
encoder.encodeStructure(descriptor) {
encodeStringElement(descriptor, 0, value.catType)
}
}
}
object DogSerializer : SerializationStrategy<Dog> {
override val descriptor = buildClassSerialDescriptor("Dog") {
element<String>("dogType")
}
override fun serialize(encoder: Encoder, value: Dog) {
encoder.encodeStructure(descriptor) {
encodeStringElement(descriptor, 0
, value.dogType)
}
}
}
使用這個模組,我們現在可以序列化 Cat 和 Dog 的實例。
val format = Json { serializersModule = module }
fun main() {
println(format.encodeToString<Animal>(AnimalProvider.createCat()))
}
輸出:
{"type":"Cat","catType":"Tabby"}
下一章將介紹 JSON 特性。
【Kotlin】Serialization CH5. JSON Features
JSON 特性
這是 Kotlin 序列化指南的第五章。本章將介紹 Json 類別中可用的 JSON 序列化功能。
目錄
- JSON 配置
- 美化打印(Pretty Printing)
- 寬鬆解析(Lenient Parsing)
- 忽略未知鍵(Ignoring Unknown Keys)
- 替代的 JSON 名稱(Alternative Json Names)
- 編碼預設值(Encoding Defaults)
- 明確的
null(Explicit Nulls) - 強制輸入值(Coercing Input Values)
- 允許結構化的映射鍵(Allowing Structured Map Keys)
- 允許特殊的浮點值(Allowing Special Floating-Point Values)
- 用於多型性的類別區分符(Class Discriminator for Polymorphism)
- 類別區分符輸出模式(Class Discriminator Output Mode)
- 以不區分大小寫的方式解碼枚舉(Decoding Enums in a Case-Insensitive Manner)
- 全域命名策略(Global Naming Strategy)
- Base64
- JSON 元素
- 解析為 JSON 元素
- JSON 元素的類型
- JSON 元素建構器
- 解碼 JSON 元素
- 編碼字面值 JSON 內容(實驗性功能)
- 序列化大型十進制數字
- 使用
JsonUnquotedLiteral創建字面值不帶引號的null是被禁止的 - JSON 轉換
- 陣列包裝
- 陣列拆包
- 操作預設值
- 基於內容的多型性反序列化
- 底層實作(實驗性功能)
- 維護自定義的 JSON 屬性
JSON 配置
默認的 Json 實作對無效的輸入非常嚴格。它強制執行 Kotlin 的類型安全性,並限制可以序列化的 Kotlin 值,以確保生成的 JSON 表示是標準的。通過創建自定義的 JSON 格式實例,可以支持許多非標準的 JSON 功能。
要使用自定義 JSON 格式配置,可以從現有的 Json 實例(例如默認的 Json 對象)中使用 Json() 建構函數來創建自己的 Json 類別實例。在括號中通過 JsonBuilder DSL 指定參數值。生成的 Json 格式實例是不可變且線程安全的;可以簡單地將其存儲在頂層屬性中。
出於性能原因,建議你存儲和重複使用自定義的格式實例,因為格式實作可能會快取有關其序列化的類別的特定於格式的附加資訊。
本章介紹了 Json 支持的配置功能。
美化打印
默認情況下,Json 輸出是一行。你可以通過設置 prettyPrint 屬性為 true 來配置它以美化打印輸出(即添加縮排和換行以提高可讀性):
val format = Json { prettyPrint = true }
@Serializable
data class Project(val name: String, val language: String)
fun main() {
val data = Project("kotlinx.serialization", "Kotlin")
println(format.encodeToString(data))
}
這會給出如下優美的結果:
{
"name": "kotlinx.serialization",
"language": "Kotlin"
}
寬鬆解析
默認情況下,Json 解析器強制執行各種 JSON 限制,以盡可能符合規範(參見 RFC-4627)。特別是,鍵和字串文字必須加引號。這些限制可以通過設置 isLenient 屬性為 true 來放寬。當 isLenient = true 時,你可以解析格式相當自由的資料:
val format = Json { isLenient = true }
enum class Status { SUPPORTED }
@Serializable
data class Project(val name: String, val status: Status, val votes: Int)
fun main() {
val data = format.decodeFromString<Project>("""
{
name : kotlinx.serialization,
status : SUPPORTED,
votes : "9000"
}
""")
println(data)
}
即使源 JSON 的所有鍵、字串和枚舉值未加引號,而整數被加引號,仍然可以獲取對象:
Project(name=kotlinx.serialization, status=SUPPORTED, votes=9000)
忽略未知鍵
JSON 格式通常用於讀取第三方服務的輸出或其他動態環境中,在這些環境中,在 API 演進過程中可能會添加新屬性。默認情況下,反序列化期間遇到的未知鍵會產生錯誤。你可以通過設置 ignoreUnknownKeys 屬性為 true 來避免這種情況並僅忽略這些鍵:
val format = Json { ignoreUnknownKeys = true }
@Serializable
data class Project(val name: String)
fun main() {
val data = format.decodeFromString<Project>("""
{"name":"kotlinx.serialization","language":"Kotlin"}
""")
println(data)
}
即使 Project 類別沒有 language 屬性,它也會解碼對象:
Project(name=kotlinx.serialization)
替代的 JSON 名稱
當 JSON 字段因為模式版本更改而重新命名時,這並不罕見。你可以使用 @SerialName 註解來更改 JSON 字段的名稱,但這種重命名會阻止使用舊名稱解碼資料。為了支持一個 Kotlin 屬性具有多個 JSON 名稱,可以使用 @JsonNames 註解:
@Serializable
data class Project(@JsonNames("title") val name: String)
fun main() {
val project = Json.decodeFromString<Project>("""{"name":"kotlinx.serialization"}""")
println(project)
val oldProject = Json.decodeFromString<Project>("""{"title":"kotlinx.coroutines"}""")
println(oldProject)
}
如你所見,name 和 title JSON 字段都對應於 name 屬性:
Project(name=kotlinx.serialization)
Project(name=kotlinx.coroutines)
@JsonNames 註解的支持由 JsonBuilder.useAlternativeNames 標誌控制。與大多數配置標誌不同,這個是默認啟用的,不需要特別關注,除非你想進行一些微調。
編碼預設值
屬性的預設值默認不會被編碼,因為它們在解碼過程中缺失字段時會被賦值。詳情和範例參見 Defaults are not encoded 一節。這對於具有 null 預設值的可空屬性尤其有用,避免了編寫對應的 null 值。可以通過將 encodeDefaults 屬性設置為 true 來更改預設行為:
val format = Json { encodeDefaults = true }
@Serializable
class Project(
val name: String,
val language: String = "Kotlin",
val website: String? = null
)
fun main() {
val data = Project("kotlinx.serialization")
println(format.encodeToString(data))
}
這會生成以下輸出,編碼了所有屬性值,包括預設值:
{"name":"kotlinx.serialization","language":"Kotlin","website":null}
明確的 null
默認情況下,所有 null 值都被編碼為 JSON 字串,但在某些情況下,你可能希望省略它們。null 值的編碼可以通過 explicitNulls 屬性進行控制。
如果你將屬性設置為 false,即使屬性沒有預設 null 值,null 值的字段也不會編碼到 JSON 中。當解碼此類 JSON 時,對於沒有預設值的可空屬性,缺少屬性值會被視為 null。
val format = Json { explicitNulls = false }
@Serializable
data class Project(
val name: String,
val language: String,
val version: String? = "1.2.2",
val website: String?,
val description: String? = null
)
fun main() {
val data = Project("kotlinx.serialization", "Kotlin", null, null, null)
val json = format.encodeToString(data)
println(json)
println(format.decodeFromString<Project>(json))
}
如你所見,version、website 和 description 字段在第一行的輸出 JSON 中並不存在。解碼後,沒有預設值的可空屬性 website 獲得了 null 值,而可空屬性 version 和 description 則使用了其預設值:
{"name":"kotlinx.serialization","language":"Kotlin"}
Project(name=kotlinx.serialization, language=Kotlin, version=1.2.2, website=null, description=null)
注意,version 在編碼前是 null,而在解碼後變為 1.2.2。如果 explicitNulls 設置為 false,則這種屬性(可空但有非 null 預設值)的編碼/解碼變得不對稱。
如果想讓解碼器將某些無效的輸入資料視為缺少字段來增強此標誌的功能,請參閱 coerceInputValues 下面的詳細信息。
explicitNulls 默認為 true,因為這是不同版本庫中的默認行為。
強制輸入值
來自第三方的 JSON 格式可以演變,有時會改變字段類型。這可能會在解碼過程中導致異常,因為實際值與預期值不匹配。默認的 Json 實作對輸入類型非常嚴格,如在 Type safety is enforced 部分中所展示的。你可以通過 coerceInputValues 屬性來放寬此限制。
此屬性僅影響解碼。它將一小部分無效的輸入值視為相應屬性缺失。當前支持的無效值清單包括:
- 對於不可空類型的
null輸入 - 枚舉的未知值
如果缺少值,則會用預設屬性值(如果存在)替換,或者如果 explicitNulls 標誌設置為 false 且屬性為可空,則替換為 null(對於枚舉)。
此清單可能在未來擴展,因此配置此屬性的 Json 實例將對輸入中的無效值更加寬容,並用預設值或 null 進行替換。
參見 Type safety is enforced 部分的範例:
val format = Json { coerceInputValues = true }
@Serializable
data class Project(val name: String, val language: String = "Kotlin")
fun main() {
val data = format.decodeFromString<Project>("""
{"name":"kotlinx.serialization","language":null}
""")
println(data)
}
language 屬性的無效 null 值被強制轉換為預設值:
Project(name=kotlinx.serialization, language=Kotlin)
以下範例展示了如何與 explicitNulls 旗標一起使用以強制無效的枚舉值:
enum class Color { BLACK, WHITE }
@Serializable
data class Brush(val foreground: Color = Color.BLACK, val background: Color?)
val json = Json {
coerceInputValues = true
explicitNulls = false
}
fun main() {
val brush = json.decodeFromString<Brush>("""{"foreground":"pink", "background":"purple"}""")
println(brush)
}
即使我們沒有 Color.pink 和 Color.purple 顏色,decodeFromString 函數仍成功返回:
Brush(foreground=BLACK, background=null)
foreground 屬性獲得了其預設值,而 background 屬性由於 explicitNulls = false 設置而獲得了 null。
允許結構化的映射鍵
JSON 格式本質上不支持具有結構化鍵的映射(Map)的概念。JSON 對象中的鍵是字串,並且默認只能用於表示基本類型或枚舉。你可以通過設置 allowStructuredMapKeys 屬性來啟用對結構化鍵的非標準支持。
以下是如何序列化具有使用者定義類別鍵的映射:
val format = Json { allowStructuredMapKeys = true }
@Serializable
data class Project(val name: String)
fun main() {
val map = mapOf(
Project("kotlinx.serialization") to "Serialization",
Project("kotlinx.coroutines") to "Coroutines"
)
println(format.encodeToString(map))
}
使用結構化鍵的映射被表示為 JSON 陣列,並包含以下項目:[key1, value1, key2, value2,...]。
[{"name":"kotlinx.serialization"},"Serialization",{"name":"kotlinx.coroutines"},"Coroutines"]
允許特殊的浮點值
默認情況下,由於 JSON 規範禁止,特殊的浮點值如 Double.NaN 和無限大在 JSON 中不受支持。你可以通過 allowSpecialFloatingPointValues 屬性來啟用它們的編碼:
val format = Json { allowSpecialFloatingPointValues = true }
@Serializable
class Data(
val value: Double
)
fun main() {
val data = Data(Double.NaN)
println(format.encodeToString(data))
}
此範例生成以下非標準 JSON 輸出,但這在 JVM 世界中是一種廣泛使用的編碼方式:
{"value":NaN}
用於多型性的類別區分符
當你有多型性資料時,可以在 classDiscriminator 屬性中指定一個鍵名稱來指定類型:
val format = Json { classDiscriminator = "#class" }
@Serializable
sealed class Project {
abstract val name: String
}
@Serializable
@SerialName("owned")
class OwnedProject(override val name: String, val owner: String) : Project()
fun main() {
val data: Project = OwnedProject("kotlinx.coroutines", "kotlin")
println(format.encodeToString(data))
}
結合明確指定的類別 SerialName,你可以完全控制生成的 JSON 對象:
{"#class":"owned","name":"kotlinx.coroutines","owner":"kotlin"}
還可以為不同的繼承層次結構指定不同的類別區分符。可以在基礎可序列化類別上直接使用 @JsonClassDiscriminator 註解,而不是 Json 實例屬性:
@Serializable
@JsonClassDiscriminator("message_type")
sealed class Base
此註解是可繼承的,因此 Base 的所有子類別都將具有相同的區分符:
@Serializable // Class discriminator is inherited from Base
sealed class ErrorClass: Base()
要了解有關可繼承序列化註解的更多資訊,請參見 InheritableSerialInfo 的文檔。
請注意,無法在 Base 子類中明確指定不同的類別區分符。只有交集為空的繼承層次結構才能具有不同的區分符。
註解中指定的區分符優先於 Json 配置中的區分符:
val format = Json { classDiscriminator = "#class" }
fun main() {
val data = Message(BaseMessage("not found"), GenericError(404))
println(format.encodeToString(data))
}
如你所見,使用了 Base 類別的區分符:
{"message":{"message_type":"my.app.BaseMessage","message":"not found"},"error":{"message_type":"my.app.GenericError","error_code":404}}
類別區分符輸出模式
類別區分符為序列化和反序列化多型性類別層次結構提供了資訊。如上所示,它默認僅添加於多型性類別。當你希望為各種第三方 API 編碼更多或更少的輸出類型資訊時,可以通過 JsonBuilder.classDiscriminatorMode 屬性來控制類別區分符的添加。
例如,ClassDiscriminatorMode.NONE 不會添加類別區分符,這適用於接收方不關心 Kotlin 類型的情況:
val format = Json { classDiscriminatorMode = ClassDiscriminatorMode.NONE }
@Serializable
sealed class Project {
abstract val name: String
}
@Serializable
class OwnedProject(override val name: String, val owner: String) : Project()
fun main() {
val data: Project = OwnedProject("kotlinx.coroutines", "kotlin")
println(format.encodeToString(data))
}
請注意,無法使用 kotlinx.serialization
將此輸出反序列化回去。
{"name":"kotlinx.coroutines","owner":"kotlin"}
另外兩個可用的值是 ClassDiscriminatorMode.POLYMORPHIC(默認行為)和 ClassDiscriminatorMode.ALL_JSON_OBJECTS(盡可能地添加區分符)。有關詳細信息,請參閱其文檔。
以不區分大小寫的方式解碼枚舉
Kotlin 的命名策略建議使用大寫下劃線分隔名稱或駝峰式名稱來命名枚舉值。Json 默認使用確切的 Kotlin 枚舉值名稱進行解碼。但是,有時候第三方 JSON 中的這些值是小寫的或混合大小寫的。在這種情況下,可以使用 JsonBuilder.decodeEnumsCaseInsensitive 屬性以不區分大小寫的方式解碼枚舉值:
val format = Json { decodeEnumsCaseInsensitive = true }
enum class Cases { VALUE_A, @JsonNames("Alternative") VALUE_B }
@Serializable
data class CasesList(val cases: List<Cases>)
fun main() {
println(format.decodeFromString<CasesList>("""{"cases":["value_A", "alternative"]}"""))
}
這會影響序列名稱以及使用 JsonNames 註解指定的替代名稱,因此這兩個值都會成功解碼:
CasesList(cases=[VALUE_A, VALUE_B])
此屬性不會以任何方式影響編碼。
全域命名策略
如果 JSON 輸入中的屬性名稱與 Kotlin 不同,建議使用 @SerialName 註解顯式指定每個屬性的名稱。但是,有些情況下需要將轉換應用於每個序列名稱,例如從其他框架遷移或遺留代碼庫。在這些情況下,可以為 Json 實例指定 namingStrategy。kotlinx.serialization 提供了一種現成的策略實作,即 JsonNamingStrategy.SnakeCase:
@Serializable
data class Project(val projectName: String, val projectOwner: String)
val format = Json { namingStrategy = JsonNamingStrategy.SnakeCase }
fun main() {
val project = format.decodeFromString<Project>("""{"project_name":"kotlinx.coroutines", "project_owner":"Kotlin"}""")
println(format.encodeToString(project.copy(projectName = "kotlinx.serialization")))
}
如你所見,序列化和反序列化都如同所有序列名稱都從駝峰式轉換為蛇形:
{"project_name":"kotlinx.serialization","project_owner":"Kotlin"}
在處理 JsonNamingStrategy 時需要注意一些限制:
由於 kotlinx.serialization 框架的性質,命名策略轉換應用於所有屬性,不論其序列名稱是取自屬性名稱還是通過 @SerialName 註解提供。實際上,這意味著無法通過顯式指定序列名稱來避免轉換。要能夠反序列化未轉換的名稱,可以使用 JsonNames 註解。
轉換後的名稱與其他(轉換後的)屬性序列名稱或使用 JsonNames 指定的任何替代名稱發生衝突將導致反序列化異常。
全域命名策略非常隱晦:僅從類別定義無法確定其在序列化形式中的名稱。因此,命名策略對於 IDE 中的 Find Usages/Rename 操作、grep 全文搜索等操作來說不友好。對於它們而言,原始名稱和轉換後的名稱是兩個不同的東西;更改一個而不更改另一個可能會以多種意想不到的方式引入錯誤,並導致更大的代碼維護成本。
因此,在考慮向應用程序中添加全域命名策略之前,應仔細權衡利弊。
Base64
要編碼和解碼 Base64 格式,我們需要手動編寫一個序列化器。在這裡,我們將使用 Kotlin 的默認 Base64 編碼器實作。請注意,某些序列化器默認使用不同的 RFC 進行 Base64 編碼。例如,Jackson 默認使用 Base64 Mime 的變體。在 kotlinx.serialization 中可以使用 Base64.Mime 編碼器來實現相同的結果。Kotlin 的 Base64 文檔列出了其他可用的編碼器。
import kotlinx.serialization.encoding.Encoder
import kotlinx.serialization.encoding.Decoder
import kotlinx.serialization.descriptors.*
import kotlin.io.encoding.*
@OptIn(ExperimentalEncodingApi::class)
object ByteArrayAsBase64Serializer : KSerializer<ByteArray> {
private val base64 = Base64.Default
override val descriptor: SerialDescriptor
get() = PrimitiveSerialDescriptor(
"ByteArrayAsBase64Serializer",
PrimitiveKind.STRING
)
override fun serialize(encoder: Encoder, value: ByteArray) {
val base64Encoded = base64.encode(value)
encoder.encodeString(base64Encoded)
}
override fun deserialize(decoder: Decoder): ByteArray {
val base64Decoded = decoder.decodeString()
return base64.decode(base64Decoded)
}
}
有關如何創建自己的自定義序列化器的詳細信息,請參見 custom serializers。
然後我們可以像這樣使用它:
@Serializable
data class Value(
@Serializable(with = ByteArrayAsBase64Serializer::class)
val base64Input: ByteArray
) {
override fun equals(other: Any?): Boolean {
if (this === other) return true
if (javaClass != other?.javaClass) return false
other as Value
return base64Input.contentEquals(other.base64Input)
}
override fun hashCode(): Int {
return base64Input.contentHashCode()
}
}
fun main() {
val string = "foo string"
val value = Value(string.toByteArray())
val encoded = Json.encodeToString(value)
println(encoded)
val decoded = Json.decodeFromString<Value>(encoded)
println(decoded.base64Input.decodeToString())
}
{"base64Input":"Zm9vIHN0cmluZw=="}
foo string
注意,我們編寫的序列化器並不依賴於 Json 格式,因此它可以在任何格式中使用。
對於在許多地方使用此序列化器的專案,可以通過使用 typealias 全域性地指定序列化器,以避免每次都指定序列化器。例如:
typealias Base64ByteArray = @Serializable(ByteArrayAsBase64Serializer::class) ByteArray
JSON 元素
除了字串與 JSON 對象之間的直接轉換外,Kotlin 序列化還提供了允許其他方式處理 JSON 的 API。例如,你可能需要在解析之前調整資料,或處理不容易適合 Kotlin 序列化的類型安全世界的非結構化資料。
此部分庫中的主要概念是 JsonElement。繼續閱讀以了解你可以用它做什麼。
解析為 JSON 元素
可以使用 Json.parseToJsonElement 函數將字串解析為 JsonElement 實例。這不叫解碼也不叫反序列化,因為在此過程中不會發生這些操作。它只是解析 JSON 並形成表示它的對象:
fun main() {
val element = Json.parseToJsonElement("""
{"name":"kotlinx.serialization","language":"Kotlin"}
""")
println(element)
}
{"name":"kotlinx.serialization","language":"Kotlin"}
JSON 元素的類型
JsonElement 類別有三個直接子類型,與 JSON 語法密切相關:
-
JsonPrimitive代表基本 JSON 元素,例如字串、數字、布林值和null。每個基本元素都有一個簡單的字串內容。還有一個JsonPrimitive()構造函數,重載以接受各種基本 Kotlin 類型並將它們轉換為JsonPrimitive。 -
JsonArray代表 JSON [...] 陣列。它是 Kotlin 列表,包含JsonElement項目。 -
JsonObject代表 JSON {...} 對象。它是從字串鍵到JsonElement值的 Kotlin 映射。
JsonElement 類別有擴展函數,將其轉換為相應的子類型:jsonPrimitive、jsonArray、jsonObject。JsonPrimitive 類別依次提供轉換為 Kotlin 基本類型的轉換器:int、intOrNull、long、longOrNull,以及其他類型的類似轉換
器。你可以使用它們來處理已知結構的 JSON:
fun main() {
val element = Json.parseToJsonElement("""
{
"name": "kotlinx.serialization",
"forks": [{"votes": 42}, {"votes": 9000}, {}]
}
""")
val sum = element
.jsonObject["forks"]!!
.jsonArray.sumOf { it.jsonObject["votes"]?.jsonPrimitive?.int ?: 0 }
println(sum)
}
上面的範例會對 forks 陣列中所有對象的 votes 進行求和,忽略沒有 votes 的對象:
9042
請注意,如果資料的結構與預期不同,執行將會失敗。
JSON 元素建構器
你可以使用相應的建構器函數 buildJsonArray 和 buildJsonObject 構建 JsonElement 子類型的實例。它們提供了一種 DSL 來定義生成的 JSON 結構。這類似於 Kotlin 標準庫集合建構器,但具有 JSON 特定的便利功能,例如更多類型特定的重載和內部建構器函數。以下範例顯示了所有關鍵功能:
fun main() {
val element = buildJsonObject {
put("name", "kotlinx.serialization")
putJsonObject("owner") {
put("name", "kotlin")
}
putJsonArray("forks") {
addJsonObject {
put("votes", 42)
}
addJsonObject {
put("votes", 9000)
}
}
}
println(element)
}
{"name":"kotlinx.serialization","owner":{"name":"kotlin"},"forks":[{"votes":42},{"votes":9000}]}
解碼 JSON 元素
JsonElement 類別的實例可以使用 Json.decodeFromJsonElement 函數解碼為可序列化對象:
@Serializable
data class Project(val name: String, val language: String)
fun main() {
val element = buildJsonObject {
put("name", "kotlinx.serialization")
put("language", "Kotlin")
}
val data = Json.decodeFromJsonElement<Project>(element)
println(data)
}
結果完全符合預期:
Project(name=kotlinx.serialization, language=Kotlin)
編碼字面值 JSON 內容(實驗性功能)
此功能是實驗性的,需要選擇加入 Kotlinx Serialization API。
在某些情況下,可能需要編碼任意未加引號的值。這可以通過 JsonUnquotedLiteral 實現。
序列化大型十進制數字
JSON 規範對數字的大小或精度沒有限制,但是無法使用 JsonPrimitive() 序列化任意大小或精度的數字。
如果使用 Double,則數字的精度受到限制,這意味著大數字會被截斷。在使用 Kotlin/JVM 時,可以改用 BigDecimal,但 JsonPrimitive() 將值編碼為字串,而不是數字。
import java.math.BigDecimal
val format = Json { prettyPrint = true }
fun main() {
val pi = BigDecimal("3.141592653589793238462643383279")
val piJsonDouble = JsonPrimitive(pi.toDouble())
val piJsonString = JsonPrimitive(pi.toString())
val piObject = buildJsonObject {
put("pi_double", piJsonDouble)
put("pi_string", piJsonString)
}
println(format.encodeToString(piObject))
}
儘管 pi 被定義為具有 30 位小數的數字,但生成的 JSON 並未反映這一點。Double 值被截斷為 15 位小數,而 String 被包裹在引號中,這不是 JSON 數字。
{
"pi_double": 3.141592653589793,
"pi_string": "3.141592653589793238462643383279"
}
為了避免精度損失,可以使用 JsonUnquotedLiteral 編碼 pi 的字串值。
import java.math.BigDecimal
val format = Json { prettyPrint = true }
fun main() {
val pi = BigDecimal("3.141592653589793238462643383279")
// 使用 JsonUnquotedLiteral 編碼原始 JSON 內容
val piJsonLiteral = JsonUnquotedLiteral(pi.toString())
val piJsonDouble = JsonPrimitive(pi.toDouble())
val piJsonString = JsonPrimitive(pi.toString())
val piObject = buildJsonObject {
put("pi_literal", piJsonLiteral)
put("pi_double", piJsonDouble)
put("pi_string", piJsonString)
}
println(format.encodeToString(piObject))
}
pi_literal 現在準確地匹配定義的值。
{
"pi_literal": 3.141592653589793238462643383279,
"pi_double": 3.141592653589793,
"pi_string": "3.141592653589793238462643383279"
}
要將 pi 解碼回 BigDecimal,可以使用 JsonPrimitive 的字串內容。
(此演示使用 JsonPrimitive 為了簡便。要獲得更可重用的處理序列化的方法,請參見 Json Transformations 下面的部分。)
import java.math.BigDecimal
fun main() {
val piObjectJson = """
{
"pi_literal": 3.141592653589793238462643383279
}
""".trimIndent()
val piObject: JsonObject = Json.decodeFromString(piObjectJson)
val piJsonLiteral = piObject["pi_literal"]!!.jsonPrimitive.content
val pi = BigDecimal(piJsonLiteral)
println(pi)
}
3.141592653589793238462643383279
使用 JsonUnquotedLiteral 創建字面值不帶引號的 null 是被禁止的
為了避免創建不一致的狀態,編碼等於 "null" 的字串是被禁止的。請改用 JsonNull 或 JsonPrimitive。
fun main() {
// 注意:使用 JsonUnquotedLiteral 創建 null 將導致異常!
JsonUnquotedLiteral("null")
}
Exception in thread "main" kotlinx.serialization.json.internal.JsonEncodingException: Creating a literal unquoted value of 'null' is forbidden. If you want to create JSON null literal, use JsonNull object, otherwise, use JsonPrimitive
JSON 轉換
要影響序列化後的 JSON 輸出的形狀和內容,或適應反序列化的輸入,可以編寫自定義序列化器。但是,特別是對於相對較小且簡單的任務來說,仔細遵循 Encoder 和 Decoder 調用約定可能很不方便。為此,Kotlin 序列化提供了 API,可以將實作自定義序列化器的負擔減輕為操作 JSON 元素樹的問題。
我們建議你熟悉 Serializers 章節:其中解釋了如何將自定義序列化器綁定到類別。
轉換功能由 JsonTransformingSerializer 抽象類別提供,它實作了 KSerializer。此類別不直接與 Encoder 或 Decoder 交互,而是要求你通過 transformSerialize 和 transformDeserialize 方法為表示為 JsonElement 類別的 JSON 樹提供轉換。我們來看看範例。
陣列包裝
第一個範例是為列表實作 JSON 陣列包裝。
考慮一個 REST API,它返回一個 User 對象的 JSON 陣列,如果結果中只有一個元素,則返回單個對象(未包裝到陣列中)。
在資料模型中,使用 @Serializable 註解指定 users: List<User> 屬性使用自定義序列化器。
@Serializable
data class Project(
val name: String,
@Serializable(with = UserListSerializer::class)
val users: List<User>
)
@Serializable
data class User(val name: String)
由於此範例僅涵蓋反序列化情況,因此你可以實作 UserListSerializer 並僅重寫 transformDeserialize 函數。JsonTransformingSerializer 構造函數將原始序列化器作為參數(此方法在 Constructing collection serializers 部分中顯示):
object UserListSerializer : JsonTransforming
Serializer<List<User>>(ListSerializer(User.serializer())) {
// 如果響應不是一個陣列,那麼它是一個應該被包裝到陣列中的單個對象
override fun transformDeserialize(element: JsonElement): JsonElement =
if (element !is JsonArray) JsonArray(listOf(element)) else element
}
現在你可以用 JSON 陣列或單個 JSON 對象作為輸入來測試代碼。
fun main() {
println(Json.decodeFromString<Project>("""
{"name":"kotlinx.serialization","users":{"name":"kotlin"}}
"""))
println(Json.decodeFromString<Project>("""
{"name":"kotlinx.serialization","users":[{"name":"kotlin"},{"name":"jetbrains"}]}
"""))
}
輸出顯示了兩種情況都正確地反序列化為 Kotlin 列表。
Project(name=kotlinx.serialization, users=[User(name=kotlin)])
Project(name=kotlinx.serialization, users=[User(name=kotlin), User(name=jetbrains)])
陣列拆包
你還可以實作 transformSerialize 函數,在序列化期間將單個元素列表拆包為單個 JSON 對象:
override fun transformSerialize(element: JsonElement): JsonElement {
require(element is JsonArray) // 此序列化器僅用於列表
return element.singleOrNull() ?: element
}
現在,如果你從 Kotlin 序列化單個元素列表對象:
fun main() {
val data = Project("kotlinx.serialization", listOf(User("kotlin")))
println(Json.encodeToString(data))
}
你最終會得到一個單個 JSON 對象,而不是一個包含一個元素的陣列:
{"name":"kotlinx.serialization","users":{"name":"kotlin"}}
操作預設值
另一種有用的轉換是從輸出 JSON 中省略特定值,例如,如果它被用作缺少時的預設值或出於其他原因。
假設你由於某些原因無法為 Project 資料模型中的 language 屬性指定預設值,但你需要在它等於 Kotlin 時將其從 JSON 中省略(我們都同意 Kotlin 應該是預設值)。你可以通過基於 Project 類別的 Plugin 生成的序列化器來編寫特別的 ProjectSerializer。
@Serializable
class Project(val name: String, val language: String)
object ProjectSerializer : JsonTransformingSerializer<Project>(Project.serializer()) {
override fun transformSerialize(element: JsonElement): JsonElement =
// 過濾掉鍵為 "language" 且值為 "Kotlin" 的頂層鍵值對
JsonObject(element.jsonObject.filterNot {
(k, v) -> k == "language" && v.jsonPrimitive.content == "Kotlin"
})
}
在下面的範例中,我們在頂層序列化 Project 類別,因此我們如 Passing a serializer manually 部分中所示,顯式將上述 ProjectSerializer 傳遞給 Json.encodeToString 函數:
fun main() {
val data = Project("kotlinx.serialization", "Kotlin")
println(Json.encodeToString(data)) // 使用插件生成的序列化器
println(Json.encodeToString(ProjectSerializer, data)) // 使用自定義序列化器
}
查看自定義序列化器的效果:
{"name":"kotlinx.serialization","language":"Kotlin"}
{"name":"kotlinx.serialization"}
基於內容的多型性反序列化
通常,多型性序列化需要在輸入的 JSON 對象中有一個專用的 "type" 鍵(也稱為類別區分符)來確定應該使用的實際序列化器來反序列化 Kotlin 類別。
但是,有時候輸入中可能沒有類型屬性。在這種情況下,你需要通過 JSON 的形狀來猜測實際類型,例如通過某個特定鍵的存在。
JsonContentPolymorphicSerializer 提供了此類策略的骨架實作。要使用它,請重寫其 selectDeserializer 方法。我們先從以下類別繼承層次結構開始。
請注意,這不必像在 Sealed classes 部分中推薦的那樣是密封的,因為我們不打算利用自動選擇相應子類別的插件生成代碼,而是打算手動實作此代碼。
@Serializable
abstract class Project {
abstract val name: String
}
@Serializable
data class BasicProject(override val name: String): Project()
@Serializable
data class OwnedProject(override val name: String, val owner: String) : Project()
你可以通過 JSON 對象中是否存在 owner 鍵來區分 BasicProject 和 OwnedProject 子類。
object ProjectSerializer : JsonContentPolymorphicSerializer<Project>(Project::class) {
override fun selectDeserializer(element: JsonElement) = when {
"owner" in element.jsonObject -> OwnedProject.serializer()
else -> BasicProject.serializer()
}
}
當你使用此序列化器來序列化資料時,會在運行時為實際類型選擇已註冊的或預設的序列化器:
fun main() {
val data = listOf(
OwnedProject("kotlinx.serialization", "kotlin"),
BasicProject("example")
)
val string = Json.encodeToString(ListSerializer(ProjectSerializer), data)
println(string)
println(Json.decodeFromString(ListSerializer(ProjectSerializer), string))
}
在 JSON 輸出中不會添加類別區分符:
[{"name":"kotlinx.serialization","owner":"kotlin"},{"name":"example"}]
[OwnedProject(name=kotlinx.serialization, owner=kotlin), BasicProject(name=example)]
底層實作(實驗性功能)
儘管上述抽象序列化器可以涵蓋大多數情況,但可以僅使用 KSerializer 類別手動實作類似的機制。如果修改 transformSerialize/transformDeserialize/selectDeserializer 抽象方法還不夠,那麼可以更改 serialize/deserialize 方法。
以下是一些有關使用 Json 的自定義序列化器的有用信息:
- 如果當前格式是
Json,則可以將Encoder和Decoder分別轉換為JsonEncoder和JsonDecoder。 JsonDecoder有decodeJsonElement方法,而JsonEncoder有encodeJsonElement方法,這些方法基本上將元素從流中的當前位置檢索或插入元素。JsonDecoder和JsonEncoder都有json屬性,它返回當前使用的Json實例及其所有設置。Json有encodeToJsonElement和decodeFromJsonElement方法。
有了這些,就可以實作兩階段轉換 Decoder -> JsonElement -> value 或 value -> JsonElement -> Encoder。例如,你可以為以下 Response 類別實作完全自定義的序列化器,這樣它的 Ok 子類可以直接表示,而 Error 子類則通過帶有錯誤訊息的對象表示:
@Serializable(with = ResponseSerializer::class)
sealed class Response<out T> {
data class Ok<out T>(val data: T) : Response<T>()
data class Error(val message: String) : Response<Nothing>()
}
class ResponseSerializer<T>(private val dataSerializer: KSerializer<T>) : KSerializer<Response<T>> {
override val descriptor: SerialDescriptor = buildSerialDescriptor("Response", PolymorphicKind.SEALED) {
element("Ok", dataSerializer.descriptor)
element("Error", buildClassSerialDescriptor("Error") {
element<String>("message")
})
}
override fun deserialize(decoder: Decoder): Response<T> {
// Decoder -> JsonDecoder
require(decoder is JsonDecoder) // 此類別只能由 JSON 解碼
// JsonDecoder -> JsonElement
val element = decoder.decodeJsonElement()
// JsonElement -> value
if (element is JsonObject && "error" in element)
return Response.Error(element["error"]!!.jsonPrimitive.content)
return Response.Ok(decoder.json.decodeFromJsonElement(dataSerializer, element))
}
override fun serialize(encoder: Encoder, value: Response<T>) {
// Encoder -> JsonEncoder
require(encoder is JsonEncoder) // 此類別只能由 JSON 編碼
// value -> JsonElement
val element = when (value) {
is Response.Ok -> encoder.json.encodeToJsonElement(dataSerializer, value.data)
is
Response.Error -> buildJsonObject { put("error", value.message) }
}
// JsonElement -> JsonEncoder
encoder.encodeJsonElement(element)
}
}
有了這個可序列化的 Response 實作,你可以為其資料使用任何可序列化的有效載荷,並序列化或反序列化相應的響應:
@Serializable
data class Project(val name: String)
fun main() {
val responses = listOf(
Response.Ok(Project("kotlinx.serialization")),
Response.Error("Not found")
)
val string = Json.encodeToString(responses)
println(string)
println(Json.decodeFromString<List<Response<Project>>>(string))
}
這樣可以精細地控制 Response 類別在 JSON 輸出中的表示形式:
[{"name":"kotlinx.serialization"},{"error":"Not found"}]
[Ok(data=Project(name=kotlinx.serialization)), Error(message=Not found)]
維護自定義的 JSON 屬性
一個很好的自定義 JSON 特定序列化器範例是一個解包所有未知 JSON 屬性到 JsonObject 類別的專用字段中的反序列化器。
讓我們添加 UnknownProject – 一個具有 name 屬性和任意細節的類別,將它們展平到相同的對象中:
data class UnknownProject(val name: String, val details: JsonObject)
但是,默認的插件生成的序列化器要求 details 是一個單獨的 JSON 對象,而這不是我們想要的。
為了緩解這個問題,編寫一個自己的序列化器,它使用事實來處理 JSON 格式:
object UnknownProjectSerializer : KSerializer<UnknownProject> {
override val descriptor: SerialDescriptor = buildClassSerialDescriptor("UnknownProject") {
element<String>("name")
element<JsonElement>("details")
}
override fun deserialize(decoder: Decoder): UnknownProject {
// 轉換為特定於 JSON 的介面
val jsonInput = decoder as? JsonDecoder ?: error("Can be deserialized only by JSON")
// 將整個內容讀取為 JSON
val json = jsonInput.decodeJsonElement().jsonObject
// 提取並移除名稱屬性
val name = json.getValue("name").jsonPrimitive.content
val details = json.toMutableMap()
details.remove("name")
return UnknownProject(name, JsonObject(details))
}
override fun serialize(encoder: Encoder, value: UnknownProject) {
error("Serialization is not supported")
}
}
現在可以用來讀取展平的 JSON 詳細資料作為 UnknownProject:
fun main() {
println(Json.decodeFromString(UnknownProjectSerializer, """{"type":"unknown","name":"example","maintainer":"Unknown","license":"Apache 2.0"}"""))
}
UnknownProject(name=example, details={"type":"unknown","maintainer":"Unknown","license":"Apache 2.0"})
下一章將涵蓋替代和自定義格式(實驗性功能)。
【Kotlin】Gson 使用指南
Gson 使用指南
出處:https://github.com/google/gson/blob/main/UserGuide.md
參考連結: https://www.cnblogs.com/three-fighter/p/13019694.html#2fieldnamingpolicy
- 概覽
- Gson 的目標
- Gson 的效能和擴展性
- Gson 使用者
- 使用 Gson
- 在 Gradle/Android 中使用 Gson
- 在 Maven 中使用 Gson
- 基本類型範例
- 物件範例
- 物件的細節
- 巢狀類別(包括內部類別)
- 陣列範例
- 集合範例
- 集合的限制
- Map 範例
- 序列化和反序列化泛型類型
- 序列化和反序列化包含任意類型物件的集合
- 內建的序列化器和反序列化器
- 自定義序列化和反序列化
- 撰寫序列化器
- 撰寫反序列化器
- 撰寫實例創建器
- Parameterized 類型的 InstanceCreator
- JSON 輸出格式的壓縮與漂亮印出
- Null 物件支援
- 版本支援
- 從序列化和反序列化中排除欄位
- Java 修飾符排除
- Gson 的
@Expose - 使用者定義的排除策略
- JSON 欄位命名支援
- 在自定義序列化器和反序列化器之間共享狀態
- 串流
- 設計 Gson 時遇到的問題
- Gson 的未來增強
概覽
Gson 是一個 Java 函式庫,可以用來將 Java 物件轉換成其 JSON 表示形式,也可以用來將 JSON 字串轉換成等效的 Java 物件。
Gson 可以處理任意的 Java 物件,包括您無法取得原始碼的既有物件。
Gson 的目標
- 提供簡單易用的機制,例如
toString()和構造器(工廠方法),以在 Java 和 JSON 之間進行轉換。 - 允許既有的不可修改的物件轉換為 JSON,或從 JSON 轉換回來。
- 允許物件的自定義表示形式。
- 支援任意複雜的物件。
- 產生簡潔且可讀的 JSON 輸出。
Gson 的效能和擴展性
以下是我們在一台桌面電腦(雙 Opteron 處理器,8GB RAM,64 位元 Ubuntu 系統)上進行多項測試時取得的一些效能指標。您可以使用類別 PerformanceTest 來重新執行這些測試。
- 字串:反序列化超過 25MB 的字串沒有任何問題(參見
PerformanceTest中的disabled_testStringDeserializationPerformance方法) - 大型集合:
- 序列化了一個包含 140 萬個物件的集合(參見
PerformanceTest中的disabled_testLargeCollectionSerialization方法) - 反序列化了一個包含 87,000 個物件的集合(參見
PerformanceTest中的disabled_testLargeCollectionDeserialization方法)
- 序列化了一個包含 140 萬個物件的集合(參見
- Gson 1.4 將位元組陣列和集合的反序列化限制從 80KB 提升到超過 11MB。
注意:要執行這些測試,請刪除 disabled_ 前綴。我們使用這個前綴來防止每次運行 JUnit 測試時都執行這些測試。
Gson 使用者
Gson 最初是為了在 Google 內部使用而創建的,現在它在 Google 的許多專案中都有使用。它現在也被許多公共專案和公司使用。
使用 Gson
主要使用的類別是 Gson,您只需通過呼叫 new Gson() 來創建它。此外,還有一個類別 GsonBuilder,可用於創建具有各種設定(例如版本控制等)的 Gson 實例。
在調用 JSON 操作時,Gson 實例不會維護任何狀態。因此,您可以自由地重複使用相同的物件進行多次 JSON 序列化和反序列化操作。
在 Gradle/Android 中使用 Gson
dependencies {
implementation 'com.google.code.gson:gson:2.11.0'
}
在 Maven 中使用 Gson
要在 Maven2/3 中使用 Gson,您可以通過添加以下依賴項來使用 Maven 中央庫中提供的 Gson 版本:
<dependencies>
<!-- Gson: Java to JSON conversion -->
<dependency>
<groupId>com.google.code.gson</groupId>
<artifactId>gson</artifactId>
<version>2.11.0</version>
<scope>compile</scope>
</dependency>
</dependencies>
這樣您的 Maven 專案就可以使用 Gson 了。
基本類型範例
// 序列化
val gson = Gson()
gson.toJson(1) // ==> 1
gson.toJson("abcd") // ==> "abcd"
gson.toJson(10L) // ==> 10
val values = intArrayOf(1)
gson.toJson(values) // ==> [1]
// 反序列化
val i = gson.fromJson("1", Int::class.java)
val intObj = gson.fromJson("1", Int::class.javaObjectType)
val longObj = gson.fromJson("1", Long::class.javaObjectType)
val boolObj = gson.fromJson("false", Boolean::class.javaObjectType)
val str = gson.fromJson("\"abc\"", String::class.java)
val strArray = gson.fromJson("[\"abc\"]", Array<String>::class.java)
物件範例
class BagOfPrimitives {
private val value1 = 1
private val value2 = "abc"
private val value3 = 3 // 被標記為 transient 但不需要標記
// 無參數構造器,Kotlin 默認會有
}
// 序列化
val obj = BagOfPrimitives()
val gson = Gson()
val json = gson.toJson(obj)
// ==> {"value1":1,"value2":"abc"}
注意,您無法序列化具有循環引用的物件,因為這會導致無限遞歸。
// 反序列化
val obj2 = gson.fromJson(json, BagOfPrimitives::class.java)
// ==> obj2 和 obj 一樣
物件的細節
- 使用 private 欄位是完全可以的(並且建議這樣做)。
- 不需要使用任何註解來指示欄位是否應
該包含在序列化和反序列化中。當前類別中的所有欄位(以及所有超類別中的欄位)默認都會被包含。
- 如果欄位被標記為 transient,(默認情況下)它將被忽略,不包含在 JSON 序列化或反序列化中。
- 這個實現正確地處理 null 值。
- 在序列化時,null 欄位會從輸出中省略。
- 在反序列化時,JSON 中缺少的條目會導致將對應的物件欄位設置為其默認值:對於物件類型為 null,對於數值類型為零,對於布林值為 false。
- 如果欄位是 synthetic 的,它將被忽略,不包含在 JSON 序列化或反序列化中。
- 內部類別中對應於外部類別的欄位將被忽略,不包含在序列化或反序列化中。
- 匿名和本地類別將被排除。它們將作為 JSON
null被序列化,而在反序列化時,它們的 JSON 值將被忽略,返回null。要啟用序列化和反序列化,請將這些類別轉換為static的嵌套類別。
巢狀類別(包括內部類別)
Gson 可以輕鬆地序列化靜態巢狀類別。
Gson 也可以反序列化靜態巢狀類別。然而,Gson 無法自動反序列化 純內部類別,因為它們的無參數構造器還需要一個參照包含物件的引用,而在反序列化時這個引用並不存在。您可以通過將內部類別設為靜態類別,或為其提供一個自定義的 InstanceCreator 來解決這個問題。以下是範例:
class A {
var a: String? = null
inner class B {
var b: String? = null
constructor() {
// 無參數構造器
}
}
}
注意:上述類別 B 無法(默認情況下)用 Gson 進行序列化。
Gson 無法將 {"b":"abc"} 反序列化為 B 的實例,因為 B 類別是內部類別。如果它被定義為靜態類別 B,那麼 Gson 就能夠反序列化該字串。另一個解決方案是為 B 撰寫自定義的實例創建器。
class InstanceCreatorForB(private val a: A) : InstanceCreator<A.B> {
override fun createInstance(type: Type): A.B {
return a.B()
}
}
上述方法是可行的,但並不推薦使用。
陣列範例
val gson = Gson()
val ints = intArrayOf(1, 2, 3, 4, 5)
val strings = arrayOf("abc", "def", "ghi")
// 序列化
gson.toJson(ints) // ==> [1,2,3,4,5]
gson.toJson(strings) // ==> ["abc", "def", "ghi"]
// 反序列化
val ints2 = gson.fromJson("[1,2,3,4,5]", IntArray::class.java)
// ==> ints2 將和 ints 相同
我們還支援多維陣列,具有任意複雜的元素類型。
集合範例
val gson = Gson()
val ints: Collection<Int> = listOf(1, 2, 3, 4, 5)
// 序列化
val json = gson.toJson(ints) // ==> [1,2,3,4,5]
// 反序列化
val collectionType = object : TypeToken<Collection<Int>>() {}.type
val ints2: Collection<Int> = gson.fromJson(json, collectionType)
// ==> ints2 和 ints 相同
這種方法比較麻煩:請注意我們如何定義集合的類型。 遺憾的是,在 Java 中無法避免這個問題。
集合的限制
Gson 可以序列化任意物件的集合,但無法從中反序列化,因為無法讓使用者指示結果物件的類型。相反,在反序列化時,集合必須是特定的泛型類型。 這是合理的,在遵循良好的 Java 編碼實踐時,這很少會是個問題。
Map 範例
Gson 預設將任何 java.util.Map 實作序列化為 JSON 物件。由於 JSON 物件僅支援字串作為成員名稱,Gson 通過呼叫 toString() 將 Map 的鍵轉換為字串,並對於 null 鍵使用 "null":
val gson = Gson()
val stringMap = linkedMapOf("key" to "value", null to "null-entry")
// 序列化
val json = gson.toJson(stringMap) // ==> {"key":"value","null":"null-entry"}
val intMap = linkedMapOf(2 to 4, 3 to 6)
// 序列化
val json2 = gson.toJson(intMap) // ==> {"2":4,"3":6}
在反序列化時,Gson 使用為 Map 鍵類型註冊的 TypeAdapter 的 read 方法。與上面顯示的集合範例類似,反序列化時必須使用 TypeToken 來告訴 Gson Map 鍵和值的類型:
val gson = Gson()
val mapType = object : TypeToken<Map<String, String>>() {}.type
val json = "{\"key\": \"value\"}"
// 反序列化
val stringMap: Map<String, String> = gson.fromJson(json, mapType)
// ==> stringMap 是 {key=value}
Gson 還支援使用複雜類型作為 Map 鍵。這個功能可以通過 GsonBuilder.enableComplexMapKeySerialization()) 啟用。如果啟用,Gson 使用為 Map 鍵類型註冊的 TypeAdapter 的 write 方法來序列化鍵,而不是使用 toString()。當任何鍵被適配器序列化為 JSON 陣列或 JSON 物件時,Gson 將整個 Map 序列化為 JSON 陣列,由鍵值對(編碼為 JSON 陣列)組成。否則,如果沒有鍵被序列化為 JSON 陣列或 JSON 物件,Gson 將使用 JSON 物件來編碼 Map:
data class PersonName(val firstName: String, val lastName: String)
val gson = GsonBuilder().enableComplexMapKeySerialization().create()
val complexMap = linkedMapOf(PersonName("John", "Doe") to 30, PersonName("Jane", "Doe") to 35)
// 序列化;複雜的 Map 被序列化為一個 JSON 陣列,包含鍵值對(作為 JSON 陣列)
val json = gson.toJson(complexMap)
// ==> [[{"firstName":"John","lastName":"Doe"},30],[{"firstName":"Jane","lastName":"Doe"},35]]
val stringMap = linkedMapOf("key" to "value")
// 序列化;非複雜 Map 被序列化為一個常規 JSON 物件
val json2 = gson.toJson(stringMap) // ==> {"key":"value"}
重要提示: 因為 Gson 默認使用 toString() 來序列化 Map 鍵,這可能會導致鍵的編碼不正確或在序列化和反序列化之間產生不匹配,例如當 toString() 沒有正確實作時。可以使用 enableComplexMapKeySerialization() 作為解決方法,確保 TypeAdapter 註冊在 Map 鍵類型中被用於反序列化和序列化。如上例所示,當沒有鍵被適配器序列化為 JSON 陣列或 JSON 物件時,Map 將被序列化為常規 JSON 物件,這是期望的結果。
注意,當反序列化枚舉類型作為 Map 鍵時,如果 Gson 無法找到與相應 name() 值(或 @SerializedName 註解)匹配的枚舉常數,它會退回到通過 toString() 值查找枚
舉常數。這是為了解決上述問題,但僅適用於枚舉常數。
序列化和反序列化泛型類型
當您呼叫 toJson(obj) 時,Gson 呼叫 obj.getClass() 來獲取要序列化的欄位資訊。同樣,您通常可以在 fromJson(json, MyClass.class) 方法中傳入 MyClass.class 物件。這對於非泛型類型的物件來說效果很好。然而,如果物件是泛型類型,那麼由於 Java 類型擦除,泛型類型資訊就會丟失。以下是說明這一點的範例:
class Foo<T>(var value: T)
val gson = Gson()
val foo = Foo(Bar())
gson.toJson(foo) // 可能無法正確序列化 foo.value
gson.fromJson<Foo<Bar>>(json, foo::class.java) // 無法將 foo.value 反序列化為 Bar
上述代碼無法將 value 解釋為 Bar 類型,因為 Gson 調用 foo::class.java 來獲取其類別資訊,但此方法返回原始類別,Foo::class.java。這意味著 Gson 無法知道這是一個 Foo<Bar> 類型的物件,而不僅僅是普通的 Foo。
您可以通過為您的泛型類型指定正確的參數化類型來解決這個問題。您可以使用 TypeToken 類別來實現這一點。
val fooType = object : TypeToken<Foo<Bar>>() {}.type
gson.toJson(foo, fooType)
gson.fromJson<Foo<Bar>>(json, fooType)
用於獲取 fooType 的慣用方法實際上定義了一個匿名的本地內部類別,包含一個 getType() 方法,該方法返回完整的參數化類型。
序列化和反序列化包含任意類型物件的集合
有時候您會處理包含混合類型的 JSON 陣列。例如: ['hello',5,{name:'GREETINGS',source:'guest'}]
等效的 Collection 包含以下內容:
val collection = mutableListOf<Any>("hello", 5, Event("GREETINGS", "guest"))
其中 Event 類別定義如下:
data class Event(val name: String, val source: String)
您可以使用 Gson 序列化這個集合而不需要做任何特殊處理:toJson(collection) 會輸出所需的結果。
然而,使用 fromJson(json, Collection::class.java) 進行反序列化是不會成功的,因為 Gson 無法知道如何將輸入映射到類型。Gson 要求您在 fromJson() 中提供集合類型的泛型版本。因此,您有三個選擇:
-
使用 Gson 的解析 API(低階串流解析器或 DOM 解析器 JsonParser)來解析陣列元素,然後對每個陣列元素使用
Gson.fromJson()。這是首選方法。這裡有一個範例 展示了如何做到這一點。 -
為
Collection::class.java註冊一個型別適配器,該適配器檢查每個陣列成員並將它們映射到適當的物件。這種方法的缺點是它會搞亂 Gson 中其他集合類型的反序列化。 -
為
MyCollectionMemberType註冊一個型別適配器,並使用fromJson()與Collection<MyCollectionMemberType>。
此方法僅在陣列作為頂層元素出現時適用,或者您可以更改保存集合的欄位類型為 Collection<MyCollectionMemberType>。
內建的序列化器和反序列化器
Gson 內建了常用類別的序列化器和反序列化器,這些類別的默認表示方式可能不合適,例如:
java.net.URL以匹配"https://github.com/google/gson/"這樣的字串java.net.URI以匹配"/google/gson/"這樣的字串
更多資訊,請參見內部類別 TypeAdapters。
您也可以在此頁面找到一些常用類別(如 JodaTime)的原始碼。
自定義序列化和反序列化
有時候默認的表示方式不是您想要的。這種情況通常發生在處理庫類別(例如 DateTime 等)時。 Gson 允許您註冊自己的自定義序列化器和反序列化器。這是通過定義兩個部分來完成的:
- JSON 序列化器:需要為物件定義自定義序列化
-
JSON 反序列化器:需要為類型定義自定義反序列化
-
實例創建器:如果有無參數構造器可用或註冊了一個反序列化器,則不需要
val gsonBuilder = GsonBuilder()
gsonBuilder.registerTypeAdapter(MyType2::class.java, MyTypeAdapter())
gsonBuilder.registerTypeAdapter(MyType::class.java, MySerializer())
gsonBuilder.registerTypeAdapter(MyType::class.java, MyDeserializer())
gsonBuilder.registerTypeAdapter(MyType::class.java, MyInstanceCreator())
registerTypeAdapter 呼叫檢查:
- 如果型別適配器實作了這些介面中的多個,則會為所有這些介面註冊該適配器。
- 如果型別適配器適用於 Object 類別或 JsonElement 或其任何子類別,則會拋出 IllegalArgumentException,因為不支援覆蓋這些類型的內建適配器。
撰寫序列化器
以下是一個撰寫 JodaTime DateTime 類別自定義序列化器的範例。
private class DateTimeSerializer : JsonSerializer<DateTime> {
override fun serialize(src: DateTime?, typeOfSrc: Type, context: JsonSerializationContext): JsonElement {
return JsonPrimitive(src.toString())
}
}
Gson 在序列化期間遇到 DateTime 物件時會呼叫 serialize()。
撰寫反序列化器
以下是一個撰寫 JodaTime DateTime 類別自定義反序列化器的範例。
private class DateTimeDeserializer : JsonDeserializer<DateTime> {
override fun deserialize(json: JsonElement, typeOfT: Type, context: JsonDeserializationContext): DateTime {
return DateTime(json.asJsonPrimitive.asString)
}
}
Gson 在需要將 JSON 字串片段反序列化為 DateTime 物件時會呼叫 deserialize。
關於序列化器和反序列化器的細節
通常您希望為所有對應於原始類型的泛型類型註冊一個處理程序
- 例如,假設您有一個
Id類別,用於 ID 的表示/轉換(即內部 vs. 外部表示)。 Id<T>類型對所有泛型類型具有相同的序列化- 實質上是寫出 ID 值
- 反序列化非常相似,但不完全相同
- 需要呼叫
new Id(Class<T>, String),它返回一個Id<T>的實例
- 需要呼叫
Gson 支援為此註冊一個處理程序。您還可以為特定泛型類型(例如需要特殊處理的 Id<RequiresSpecialHandling>)註冊一個特定的處理程序。 toJson() 和 fromJson() 的 Type 參數包含泛型類型資訊,幫助您為所有對應的泛型類型撰寫單個處理程序。
撰寫實例創建器
在反序列化物件時,Gson 需要創建類別的預設實例。 行為良好的類別(用於序列化和反序列化的)應該有一個無參數構造器。
- 無論是 public 還是 private 都無所謂
通常,當您處理的庫類別沒有定義無參數構造器時,需要實例創建器。
實例創建器範例
private class MoneyInstanceCreator : InstanceCreator<Money> {
override fun createInstance(type: Type): Money {
return Money("1000000", CurrencyCode.USD)
}
}
Type 可能是相應泛型類型的。
- 非常有用,可以呼叫需要特定泛型類型資訊的構造器
- 例如,如果
Id類別存儲了創建 ID 的類別
Parameterized 類型的 InstanceCreator
有時候您要實例化的類型是參數化類型。一般來說,這不是問題,因為實際的實例是原始類型。以下是一個範例:
class MyList<T> : ArrayList<T>()
class MyListInstanceCreator : InstanceCreator<MyList<*>> {
override fun createInstance(type: Type): MyList<*> {
// 不需要使用參數化列表,因為實際實例無論如何都將具有原始類型。
return MyList<Any?>()
}
}
然而,有時候您確實需要根據實際的參數化類型創建實例。在這種情況下,您可以使用傳遞給 createInstance 方法的類型參數。以下是一個範例:
class Id<T>(private val classOfId: Class<T>, private val value: Long)
class IdInstanceCreator : InstanceCreator<Id<*>> {
override fun createInstance(type: Type): Id<*> {
val typeParameters = (type as ParameterizedType).actualTypeArguments
val idType = typeParameters[0] as Class<*> // Id 只有一個參數化類型 T
return Id(idType, 0L)
}
}
在上述範例中,如果不傳入參數化類型的實際類型,就無法創建 Id 類別的實例。我們通過使用傳遞的參數 type 解決了這個問題。在這個例子中,type 物件是 Id<Foo> 的 Java 參數化類型表示,其中實際的實例應綁定為 Id<Foo>。由於 Id 類別只有一個參數化類型參數 T,我們使用 getActualTypeArgument() 返回的類型數組的第零個元素,它在這種情況下將持有 Foo.class。
JSON 輸出格式的壓縮與漂亮印出
Gson 提供的預設 JSON 輸出格式是一種緊湊的 JSON 格式。這意味著在輸出 JSON 結構中不會有任何空白。因此,在 JSON 輸出中,欄位名稱與其值、物件欄位以及陣列中的物件之間不會有空白。另外,"null" 欄位將在輸出中被忽略(注意:在物件集合/陣列中,null 值仍然會被包括)。請參見 Null 物件支援 部分,了解如何配置 Gson 以輸出所有 null 值。
如果您想使用漂亮印出功能,必須使用 GsonBuilder 來配置您的 Gson 實例。JsonFormatter 並未通過我們的公開 API 曝露,因此用戶端無法配置 JSON 輸出的默認打印設定/邊距。目前,我們僅提供一個默認的 JsonPrintFormatter,該格式器具有 80 字元的默認行長、2 字元的縮排和 4 字元的右邊距。
以下範例顯示了如何配置 Gson 實例以使用默認的 JsonPrintFormatter 而非 JsonCompactFormatter:
val gson = GsonBuilder().setPrettyPrinting().create()
val jsonOutput = gson.toJson(someObject)
Null 物件支援
Gson 實作的預設行為是忽略 null 物件欄位。這允許更緊湊的輸出格式;然而,當 JSON 格式轉換回其 Java 形式時,用戶端必須為這些欄位定義一個默認值。
以下是如何配置 Gson 實例以輸出 null 的範例:
val gson = GsonBuilder().serializeNulls().create()
注意:使用 Gson 序列化 null 時,它會向 JsonElement 結構添加一個 JsonNull 元素。因此,這個物件可以在自定義序列化/反序列化中使用。
以下是一個範例:
data class Foo(val s: String? = null, val i: Int = 5)
val gson = GsonBuilder().serializeNulls().create()
val foo = Foo()
var json = gson.toJson(foo)
println(json)
json = gson.toJson(null)
println(json)
輸出是:
{"s":null,"i":5}
null
版本支援
可以使用 @Since 註解來維護同一物件的多個版本。此註解可以用於類別、欄位,未來版本中也可用於方法。為了利用此功能,您必須配置您的 Gson 實例以忽略任何高於某個版本號的欄位/物件。如果在 Gson 實例上未設定版本,則它將序列化和反序列化所有欄位和類別,而不考慮版本。
data class VersionedClass(
@Since(1.1) val newerField: String = "newer",
@Since(1.0) val newField: String = "new",
val field: String = "old"
)
val versionedObject = VersionedClass()
var gson = GsonBuilder().setVersion(1.0).create()
var jsonOutput = gson.toJson(versionedObject)
println(jsonOutput)
println()
gson = Gson()
jsonOutput = gson.toJson(versionedObject)
println(jsonOutput)
輸出是:
{"newField":"new","field":"old"}
{"newerField":"newer","newField":"new","field":"old"}
從序列化和反序列化中排除欄位
Gson 支援多種機制來排除頂層類別、欄位和欄位類型。下面是可插入的機制,允許排除欄位和類別。如果下列機制無法滿足您的需求,您還可以使用自定義序列化器和反序列化器。
Java 修飾符排除
默認情況下,如果您將欄位標記為 transient,則該欄位將被排除。同樣,如果欄位標記為 static,則默認情況下也會被排除。如果您想包括某些 transient 欄位,可以按以下方式進行操作:
import java.lang.reflect.Modifier
val gson = GsonBuilder()
.excludeFieldsWithModifiers(Modifier.STATIC)
.create()
注意:您可以向 excludeFieldsWithModifiers 方法提供任意數量的 Modifier 常數。例如:
val gson = GsonBuilder()
.excludeFieldsWithModifiers(Modifier.STATIC, Modifier.TRANSIENT, Modifier.VOLATILE)
.create()
Gson 的 @Expose
此功能提供了一種方法,您可以標記物件的某些欄位,以排除它們不被考慮進行序列化和反序列化為 JSON。要使用此註解,您必須通過使用 new GsonBuilder().excludeFieldsWithoutExposeAnnotation().create() 創建 Gson。創建的 Gson 實例將排除類別中未標記 @Expose 註解的所有欄位。
使用者定義的排除策略
如果上述排除欄位和類別類型的機制對您不起作用,則可以撰寫自己的排除策略並將其插入到 Gson 中。詳細資訊請參見 ExclusionStrategy JavaDoc。
以下範例展示了如何排除具有特定 @Foo 註解的欄位,並排除類別 String 的頂層類型(或聲明的欄位類型)。
@Retention(AnnotationRetention.RUNTIME)
@Target(AnnotationTarget.FIELD)
annotation class Foo
data class SampleObjectForTest(
@Foo val annotatedField:
Int = 5,
val stringField: String = "someDefaultValue",
val longField: Long = 1234L
)
class MyExclusionStrategy(private val typeToSkip: Class<*>) : ExclusionStrategy {
override fun shouldSkipClass(clazz: Class<*>): Boolean {
return clazz == typeToSkip
}
override fun shouldSkipField(f: FieldAttributes): Boolean {
return f.getAnnotation(Foo::class.java) != null
}
}
fun main() {
val gson = GsonBuilder()
.setExclusionStrategies(MyExclusionStrategy(String::class.java))
.serializeNulls()
.create()
val src = SampleObjectForTest()
val json = gson.toJson(src)
println(json)
}
輸出是:
{"longField":1234}
JSON 欄位命名支援
Gson 支援一些預定義的欄位命名策略,用於將標準 Java 欄位名稱(即,以小寫字母開頭的駝峰式命名,例如 sampleFieldNameInJava)轉換為 JSON 欄位名稱(例如,sample_field_name_in_java 或 SampleFieldNameInJava)。有關預定義命名策略的資訊,請參見 FieldNamingPolicy 類別。
它還有基於註解的策略,允許客戶端根據每個欄位定義自定義名稱。請注意,基於註解的策略具有欄位名稱驗證功能,如果提供的欄位名稱無效,將引發「執行時」異常。
以下是如何使用 Gson 命名策略功能的範例:
data class SomeObject(
@SerializedName("custom_naming") val someField: String,
val someOtherField: String
)
val someObject = SomeObject("first", "second")
val gson = GsonBuilder().setFieldNamingPolicy(FieldNamingPolicy.UPPER_CAMEL_CASE).create()
val jsonRepresentation = gson.toJson(someObject)
println(jsonRepresentation)
輸出是:
{"custom_naming":"first","SomeOtherField":"second"}
如果您需要自定義命名策略(請參見此討論),您可以使用 @SerializedName 註解。
在自定義序列化器和反序列化器之間共享狀態
有時候您需要在自定義序列化器/反序列化器之間共享狀態(請參見此討論)。您可以使用以下三種策略來實現:
- 將共享狀態存儲在靜態欄位中
- 將序列化器/反序列化器聲明為父類型的內部類別,並使用父類型的實例欄位來存儲共享狀態
- 使用 Java
ThreadLocal
1 和 2 都不是線程安全的選項,但 3 是。
串流
除了 Gson 的物件模型和數據綁定外,您還可以使用 Gson 來讀取和寫入串流。您還可以結合串流和物件模型訪問,以獲得兩種方法的最佳效果。
設計 Gson 時遇到的問題
請參見 Gson 設計文檔,了解我們在設計 Gson 時面臨的問題討論。它還包括 Gson 與其他可用於 JSON 轉換的 Java 函式庫的比較。
Gson 的未來增強
欲了解最新的增強提議列表,或如果您想建議新功能,請參見項目網站下的 Issues 部分。
/*
* Copyright (C) 2008 Google Inc.
*
* Licensed under the Apache License, Version 2.0 (the "License");
* you may not use this file except in compliance with the License.
* You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
package com.google.gson.metrics;
import static com.google.common.truth.Truth.assertThat;
import com.google.gson.Gson;
import com.google.gson.JsonParseException;
import com.google.gson.annotations.Expose;
import com.google.gson.reflect.TypeToken;
import java.io.StringWriter;
import java.lang.reflect.Type;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import org.junit.Before;
import org.junit.Ignore;
import org.junit.Test;
/**
* Tests to measure performance for Gson. All tests in this file will be disabled in code. To run
* them remove the {@code @Ignore} annotation from the tests.
*
* @author Inderjeet Singh
* @author Joel Leitch
*/
@SuppressWarnings("SystemOut") // allow System.out because test is for manual execution anyway
public class PerformanceTest {
private static final int COLLECTION_SIZE = 5000;
private static final int NUM_ITERATIONS = 100;
private Gson gson;
@Before
public void setUp() throws Exception {
gson = new Gson();
}
@Test
public void testDummy() {
// This is here to prevent Junit for complaining when we disable all tests.
}
@Test
@Ignore
public void testStringDeserialization() {
StringBuilder sb = new StringBuilder(8096);
sb.append("Error Yippie");
while (true) {
try {
String stackTrace = sb.toString();
sb.append(stackTrace);
String json = "{\"message\":\"Error message.\"," + "\"stackTrace\":\"" + stackTrace + "\"}";
parseLongJson(json);
System.out.println("Gson could handle a string of size: " + stackTrace.length());
} catch (JsonParseException expected) {
break;
}
}
}
private void parseLongJson(String json) throws JsonParseException {
ExceptionHolder target = gson.fromJson(json, ExceptionHolder.class);
assertThat(target.message).contains("Error");
assertThat(target.stackTrace).contains("Yippie");
}
private static class ExceptionHolder {
public final String message;
public final String stackTrace;
// For use by Gson
@SuppressWarnings("unused")
private ExceptionHolder() {
this("", "");
}
public ExceptionHolder(String message, String stackTrace) {
this.message = message;
this.stackTrace = stackTrace;
}
}
@SuppressWarnings("unused")
private static class CollectionEntry {
final String name;
final String value;
// For use by Gson
private CollectionEntry() {
this(null, null);
}
CollectionEntry(String name, String value) {
this.name = name;
this.value = value;
}
}
/** Created in response to http://code.google.com/p/google-gson/issues/detail?id=96 */
@Test
@Ignore
public void testLargeCollectionSerialization() {
int count = 1400000;
List<CollectionEntry> list = new ArrayList<>(count);
for (int i = 0; i < count; ++i) {
list.add(new CollectionEntry("name" + i, "value" + i));
}
String unused = gson.toJson(list);
}
/** Created in response to http://code.google.com/p/google-gson/issues/detail?id=96 */
@Test
@Ignore
public void testLargeCollectionDeserialization() {
StringBuilder sb = new StringBuilder();
int count = 87000;
boolean first = true;
sb.append('[');
for (int i = 0; i < count; ++i) {
if (first) {
first = false;
} else {
sb.append(',');
}
sb.append("{name:'name").append(i).append("',value:'value").append(i).append("'}");
}
sb.append(']');
String json = sb.toString();
Type collectionType = new TypeToken<ArrayList<CollectionEntry>>() {}.getType();
List<CollectionEntry> list = gson.fromJson(json, collectionType);
assertThat(list).hasSize(count);
}
/** Created in response to http://code.google.com/p/google-gson/issues/detail?id=96 */
// Last I tested, Gson was able to serialize upto 14MB byte array
@Test
@Ignore
public void testByteArraySerialization() {
for (int size = 4145152; true; size += 1036288) {
byte[] ba = new byte[size];
for (int i = 0; i < size; ++i) {
ba[i] = 0x05;
}
String unused = gson.toJson(ba);
System.out.printf("Gson could serialize a byte array of size: %d\n", size);
}
}
/** Created in response to http://code.google.com/p/google-gson/issues/detail?id=96 */
// Last I tested, Gson was able to deserialize a byte array of 11MB
@Test
@Ignore
public void testByteArrayDeserialization() {
for (int numElements = 10639296; true; numElements += 16384) {
StringBuilder sb = new StringBuilder(numElements * 2);
sb.append("[");
boolean first = true;
for (int i = 0; i < numElements; ++i) {
if (first) {
first = false;
} else {
sb.append(",");
}
sb.append("5");
}
sb.append("]");
String json = sb.toString();
byte[] ba = gson.fromJson(json, byte[].class);
System.out.printf("Gson could deserialize a byte array of size: %d\n", ba.length);
}
}
// The tests to measure serialization and deserialization performance of Gson
// Based on the discussion at
// http://groups.google.com/group/google-gson/browse_thread/thread/7a50b17a390dfaeb
// Test results: 10/19/2009
// Serialize classes avg time: 60 ms
// Deserialized classes avg time: 70 ms
// Serialize exposed classes avg time: 159 ms
// Deserialized exposed classes avg time: 173 ms
@Test
@Ignore
public void testSerializeClasses() {
ClassWithList c = new ClassWithList("str");
for (int i = 0; i < COLLECTION_SIZE; ++i) {
c.list.add(new ClassWithField("element-" + i));
}
StringWriter w = new StringWriter();
long t1 = System.currentTimeMillis();
for (int i = 0; i < NUM_ITERATIONS; ++i) {
gson.toJson(c, w);
}
long t2 = System.currentTimeMillis();
long avg = (t2 - t1) / NUM_ITERATIONS;
System.out.printf("Serialize classes avg time: %d ms\n", avg);
}
@Test
@Ignore
public void testDeserializeClasses() {
String json = buildJsonForClassWithList();
ClassWithList[] target = new ClassWithList[NUM_ITERATIONS];
long t1 = System.currentTimeMillis();
for (int i = 0; i < NUM_ITERATIONS; ++i) {
target[i] = gson.fromJson(json, ClassWithList.class);
}
long t2 = System.currentTimeMillis();
long avg = (t2 - t1) / NUM_ITERATIONS;
System.out.printf("Deserialize classes avg time: %d ms\n", avg);
}
@Test
@Ignore
public void testLargeObjectSerializationAndDeserialization() {
Map<String, Long> largeObject = new HashMap<>();
for (long l = 0; l < 100000; l++) {
largeObject.put("field" + l, l);
}
long t1 = System.currentTimeMillis();
String json = gson.toJson(largeObject);
long t2 = System.currentTimeMillis();
System.out.printf("Large object serialized in: %d ms\n", (t2 - t1));
t1 = System.currentTimeMillis();
Map<String, Long> unused = gson.fromJson(json, new TypeToken<Map<String, Long>>() {}.getType());
t2 = System.currentTimeMillis();
System.out.printf("Large object deserialized in: %d ms\n", (t2 - t1));
}
@Test
@Ignore
public void testSerializeExposedClasses() {
ClassWithListOfObjects c1 = new ClassWithListOfObjects("str");
for (int i1 = 0; i1 < COLLECTION_SIZE; ++i1) {
c1.list.add(new ClassWithExposedField("element-" + i1));
}
ClassWithListOfObjects c = c1;
StringWriter w = new StringWriter();
long t1 = System.currentTimeMillis();
for (int i = 0; i < NUM_ITERATIONS; ++i) {
gson.toJson(c, w);
}
long t2 = System.currentTimeMillis();
long avg = (t2 - t1) / NUM_ITERATIONS;
System.out.printf("Serialize exposed classes avg time: %d ms\n", avg);
}
@Test
@Ignore
public void testDeserializeExposedClasses() {
String json = buildJsonForClassWithList();
ClassWithListOfObjects[] target = new ClassWithListOfObjects[NUM_ITERATIONS];
long t1 = System.currentTimeMillis();
for (int i = 0; i < NUM_ITERATIONS; ++i) {
target[i] = gson.fromJson(json, ClassWithListOfObjects.class);
}
long t2 = System.currentTimeMillis();
long avg = (t2 - t1) / NUM_ITERATIONS;
System.out.printf("Deserialize exposed classes avg time: %d ms\n", avg);
}
@Test
@Ignore
public void testLargeGsonMapRoundTrip() throws Exception {
Map<Long, Long> original = new HashMap<>();
for (long i = 0; i < 1000000; i++) {
original.put(i, i + 1);
}
Gson gson = new Gson();
String json = gson.toJson(original);
Type longToLong = new TypeToken<Map<Long, Long>>() {}.getType();
Map<Long, Long> unused = gson.fromJson(json, longToLong);
}
private static String buildJsonForClassWithList() {
StringBuilder sb = new StringBuilder("{");
sb.append("field:").append("'str',");
sb.append("list:[");
boolean first = true;
for (int i = 0; i < COLLECTION_SIZE; ++i) {
if (first) {
first = false;
} else {
sb.append(',');
}
sb.append("{field:'element-" + i + "'}");
}
sb.append(']');
sb.append('}');
String json = sb.toString();
return json;
}
@SuppressWarnings("unused")
private static final class ClassWithList {
final String field;
final List<ClassWithField> list = new ArrayList<>(COLLECTION_SIZE);
ClassWithList() {
this(null);
}
ClassWithList(String field) {
this.field = field;
}
}
@SuppressWarnings("unused")
private static final class ClassWithField {
final String field;
ClassWithField() {
this("");
}
public ClassWithField(String field) {
this.field = field;
}
}
@SuppressWarnings("unused")
private static final class ClassWithListOfObjects {
@Expose final String field;
@Expose final List<ClassWithExposedField> list = new ArrayList<>(COLLECTION_SIZE);
ClassWithListOfObjects() {
this(null);
}
ClassWithListOfObjects(String field) {
this.field = field;
}
}
@SuppressWarnings("unused")
private static final class ClassWithExposedField {
@Expose final String field;
ClassWithExposedField() {
this("");
}
ClassWithExposedField(String field) {
this.field = field;
}
}
}【Kotlin】kotlinx.serialization Vs Gson
1. 簡介
- kotlinx.serialization:介紹它是 Kotlin 官方提供的序列化庫,支持 JSON 和其他格式。
- Gson:介紹它是 Google 開發的 Java 序列化庫,用於將 Java 對象轉換為 JSON,反之亦然。
-
範例程式碼:
// kotlinx.serialization example @Serializable data class User(val name: String, val age: Int) -
// Gson example data class User(val name: String, val age: Int) - 說明:
kotlinx.serialization使用@Serializable註解來標記可序列化的類,而 Gson 則不需要特定註解(除非需要特殊處理)。
2. 設計理念
- kotlinx.serialization:設計為 Kotlin 專用,強調與 Kotlin 語言特性的緊密集成(例如
data classes、sealed classes)。 - Gson:設計為通用的 Java 庫,支持多種 Java 對象類型。
-
範例程式碼:
// kotlinx.serialization val jsonStr = Json.encodeToString(User("Alice", 25)) println(jsonStr) // {"name":"Alice","age":25} // Gson val gson = Gson() val gsonStr = gson.toJson(User("Alice", 25)) println(gsonStr) // {"name":"Alice","age":25} - 說明:
kotlinx.serialization與 Kotlin 整合更緊密,直接使用 Kotlin 的標準庫方法,而 Gson 則是 Java 標準的物件-JSON 序列化工具。
3. 使用方式
- 介紹如何在兩者中實現基本的 JSON 序列化和反序列化。
- 範例程式碼:比較使用
@Serializable註解和 Gson 的@SerializedName註解。 - 依賴管理:
-
object Kotlin { const val serializationJson = "org.jetbrains.kotlinx:kotlinx-serialization-json:1.7.1" } dependencies { implementation(Kotlin.serializationJson) } plugins { kotlin("plugin.serialization") version "2.0.0" // 添加序列化插件 } -
object Libraries { const val gson = "com.google.code.gson:gson:2.10.1" } dependencies { implementation(Libraries.gson) } -
範例程式碼:
// kotlinx.serialization @Serializable data class Product(val id: Int, val name: String) val jsonString = Json.encodeToString(Product(1, "Laptop")) val product = Json.decodeFromString<Product>(jsonString) -
// Gson data class Product(val id: Int, val name: String) val gson = Gson() val jsonString = gson.toJson(Product(1, "Laptop")) val product = gson.fromJson(jsonString, Product::class.java) - 簡短說明:
kotlinx.serialization和 Gson 都可以輕鬆地進行物件與 JSON 之間的轉換,但kotlinx.serialization更加型別安全,避免了 Java 的類型擦除問題。
1. 類型擦除(Type Erasure)問題
- 當您呼叫
toJson(obj)時,Gson 呼叫obj.getClass()來獲取要序列化的欄位資訊。同樣,您通常可以在fromJson(json, MyClass.class)方法中傳入MyClass.class物件。這對於非泛型類型的物件來說效果很好。然而,如果物件是泛型類型,那麼由於 Java 類型擦除,泛型類型資訊就會丟失。以下是說明這一點的範例: -
@Serializable data class People<T>(var value: T) @Serializable data class Man(val name: String) val gson = Gson() val people = People(Man("John")) gson.toJson(people) gson.fromJson<People<Man>>(people, People::class.java) // 無法將 people.value 反序列化為 People -
上述代碼無法將 value 解釋為 Man 類型,因為 Gson 調用
People::class.java來獲取其類別資訊,但此方法返回原始類別,People::class.java。這意味著 Gson 無法知道這是一個People<Man>類型的物件,而不僅僅是普通的People。您可以通過為您的泛型類型指定正確的參數化類型來解決這個問題。您可以使用
TypeToken類別來實現這一點。 -
val gson = Gson() val people = People(Man("John")) val peopleType = object : TypeToken<People<Man>>() {}.type val gsonString = gson.toJson(people, peopleType) println(gsonString) //{"value":{"name":"John"}} val people2 = gson.fromJson<People<Man>>(gsonString, peopleType) println(people2) // People(value=Man(name=John)) -
val gson = Gson() val users = listOf(User("Alice",18),User("Sam",20)) val gsonString = gson.toJson(users) // 序列化 println(gsonString) // [{"name":"Alice","age":18},{"name":"Sam","age":20}] // 反序列化 val userType = object : TypeToken<List<User>>() {}.type // val users2 = gson.fromJson<List<User>>(gsonString, List<User>::class.java) // 無法反序列化 val users2 = gson.fromJson<List<User>>(gsonString, userType) println(users2) // [User(name=Alice, age=18), User(name=Sam, age=20)] -
import com.google.gson.Gson import com.google.gson.GsonBuilder import com.google.gson.reflect.TypeToken val gson: Gson = GsonBuilder() .serializeNulls() .setLenient() .create() private val prettyGson: Gson = GsonBuilder() .setPrettyPrinting() .serializeNulls() .setLenient() .create() fun <T> fromJson(json: String, clazz: Class<T>): T { return gson.fromJson(json, clazz) } inline fun <reified T> fromJson(json: String): T { return gson.fromJson(json, object : TypeToken<T>() {}.type) } fun toJson(src: Any): String { return gson.toJson(src) } fun toPrettyJson(src: Any): String { return prettyGson.toJson(src) } ////////////////////////////////////////////////////////////// val map = listOf(User("Alice", 25) ,User("John", 18)) val userList = GsonUtil.fromJson<List<User>>(GsonUtil.toJson(map)) println(userList) // [User(name=Alice, age=25), User(name=John, age=18)]
2. kotlinx.serialization 的型別安全
kotlinx.serialization 是 Kotlin 原生的序列化庫,它能夠利用 Kotlin 的反射和內聯函數特性在編譯時和運行時保留類型信息,避免了類型擦除問題。這意味著你可以直接在編譯期獲取類型信息,從而在運行時保留完整的類型安全性。
範例:
@Serializable
data class People<T>(var value: T)
@Serializable
data class Man(val name: String)
val people = People(Man("John"))
val jsonString = Json.encodeToString(people)
println(jsonString) // {"value":{"name":"John"}}
val people2 = Json.decodeFromString<People<Man>>(jsonString)
println(people2) // People(value=Man(name=John))在這個例子中,kotlinx.serialization 使用 decodeFromString<User>(jsonString) 方法時,直接保留了 User 類型的信息,而無需額外提供類型提示。這是因為 Kotlin 的 inline 函數和 reified 泛型可以在運行時保留類型信息。
3. 優勢和好處
- 更簡潔的代碼:由於不需要像 Java 中那樣使用
TypeToken,代碼更為簡潔。 - 避免運行時錯誤:
kotlinx.serialization在編譯期就可以捕獲到類型錯誤,減少了在運行時發生類型錯誤的風險。 - 原生支持 Kotlin 特性:
kotlinx.serialization支持 Kotlin 的數據類(data class)、密封類(sealed class)、型別別名(type alias)等,這些在序列化時都能得到更好的支持。
4. 特性比較
在 kotlinx.serialization 中,有多種設定可以控制 JSON 序列化和反序列化的行為,這些設定可以通過 Json 配置進行調整。以下是對這些設定的詳細補充說明,以及如何混合使用它們:
1. prettyPrint
- 說明:如果設置為
true,生成的 JSON 會以更具可讀性的格式進行縮排和換行。這對於需要易於閱讀和調試的 JSON 輸出非常有用。 - 預設值(false)
- 範例:
val json = Json { prettyPrint = true } val data = json.encodeToString(User("Alice", 25)) println(data) // 生成的 JSON 會換行和縮排 /* { "name": "Alice", "age": 25 } */ -
val gson = GsonBuilder().setPrettyPrinting().create() val jsonString = gson.toJson(User("Alice", 25)) println(jsonString) /* { "name": "Alice", "age": 25 } */
2. isLenient
- 說明:如果設置為
true,反序列化時會允許 JSON 不符合嚴格的 JSON 標準。例如,允許非雙引號字符串、不轉義的控制字符等。 - 範例:
val json = Json { isLenient = true } val user = json.decodeFromString<User>("""{"name":'Alice', "age":25}""") println(user) // User(name=Alice, age=25) -
val gson = GsonBuilder() .setLenient() .create() val reader = StringReader("{'name': 'Alice', 'age': 25}") val user: User = gson.fromJson(reader, User::class.java) println(user) // User(name=Alice, age=25) - 用途:用於處理不符合標準的 JSON。
3. ignoreUnknownKeys
- 說明:如果設置為
true,反序列化時會忽略 JSON 中多餘的、不在 Kotlin 資料類中定義的鍵。 - 預設值(false),多餘的、不在 Kotlin 資料類中定義的鍵,會拋出錯誤
- 範例:
val json = Json { ignoreUnknownKeys = true } val data = json.decodeFromString<User>("""{"name":"Alice", "age":25, "gender":"female"}""") // User(name=Alice, age=25) -
// Gson 只會輸出class有的屬性,不會出現錯誤 val gson = Gson() val user: User = gson.fromJson("{\"name\": \"Alice\", \"age\": 25, \"gender\": \"female\"}", User::class.java) println(user) // User(name=Alice, age=25) - 用途:用於處理結構可能有變化或不完整的 JSON 資料。
4. @JsonNames
- 說明:用於指定多個 JSON 欄位名可以對應於 Kotlin 類中的同一屬性。這對於處理不同命名風格或版本兼容性非常有用。
- 範例:
@Serializable data class User( @JsonNames("username", "user_name","uname") val name: String, val age: Int ) val json = Json{} val User = Json.encodeToString(User("mary", 20)) println(User) // {"name":"mary","age":20} val jsonNamesData = json.decodeFromString<User>("""{"uname":"Alice", "age":25, "gender":"female"}""") println(jsonNamesData) // User(name=Alice, age=25) -
import com.google.gson.annotations.SerializedName data class User( @SerializedName(value = "user_name", alternate = ["username", "userName"]) val name: String, val age: Int ) // 序列化 val jsonString = """{"user_name": "Alice", "age": 25}""" val gson = Gson() val user: User = gson.fromJson(jsonString, User::class.java) println(user.name) // Output: Alice // 反序列化 val user = User(name = "Alice", age = 25) val gson = Gson() val jsonString = gson.toJson(user) println(jsonString) // Output: {"user_name":"Alice","age":25} - 用途:用於不同 JSON 格式之間的兼容性。
5. encodeDefaults
- 說明:如果設置為
true,則在序列化時會包含所有屬性,即使它們具有預設值;如果為false,則省略具有預設值的屬性。
預設輸出預設值(false) - 範例:
data class User( @JsonNames("username", "user_name", "uname") val name: String, val age: Int = 30 ) val json = Json { encodeDefaults = true } val data = json.encodeToString(User("Alice")) // encodeDefaults = true // { // "name": "Alice", // "age": 30 // } // encodeDefaults = false (default) // { // "name": "Alice" // } -
// 說明:Gson 不會使用 Kotlin 的預設參數值, // 想要預設值需要自定義序列化器 val userSerializer = JsonSerializer<User> { src, _, _ -> val DEFAULT_AGE = 30 val jsonObject = JsonObject() jsonObject.addProperty("name", src.name) if (src.age != DEFAULT_AGE) { // 檢查 age 是否為預設值 jsonObject.addProperty("age", src.age) } jsonObject } // 創建 Gson 並註冊自定義序列化器 val gson = GsonBuilder() .registerTypeAdapter(User::class.java, userSerializer) .create() val alice = User("Alice") val jsonString = gson.toJson(alice) println(jsonString) // Output: {"name":"Alice"} val tom = User("Tom",18) val jsonString2 = gson.toJson(tom) println(jsonString2) // Output: {"name":"Tom","age":18} -
直接隱藏屬性
-
import com.google.gson.Gson import com.google.gson.GsonBuilder import java.lang.reflect.Modifier import kotlinx.serialization.Transient // Gson 或是使用 @Transient 註解 + excludeFieldsWithModifiers 排除屬性 // kotlinx.serialization 也可以用此註解,效果一樣 data class User( val name: String, @Transient val age: Int = 30 // 被 transient 修飾符修飾 ) { companion object { const val COMPANY = "ExampleCompany" // 靜態屬性,將被排除 } } fun main() { val gson: Gson = GsonBuilder() .excludeFieldsWithModifiers(Modifier.TRANSIENT, Modifier.STATIC) // 排除 transient 和 static 修飾符的屬性 .create() val user = User(name = "Alice") val jsonString = gson.toJson(user) println(jsonString) // {"name":"Alice"} // kotlinx.serialization 也可以用此註解,效果一樣 println(Json.encodeToString(user)) // Output: {"name":"Alice"} } - 用途:控制 JSON 中輸出的詳細程度。
6. explicitNulls
- 說明:如果設置為
false,序列化時將省略值為null的屬性;如果設置為true,則會顯示null值。
預設(false)不輸出null - 範例:
val json = Json { explicitNulls = true } val data = json.encodeToString(User("Alice", null)) // { // "name": "Alice", // "age": 25, // "nickName": null // } -
data class User2( // @JsonNames("username", "user_name", "uname") val name: String, val age: Int? = null, val nickName: String? = null ) val gsonIncludeNulls = GsonBuilder().serializeNulls().create() // 包含 null val gsonExcludeNulls = GsonBuilder().create() // 排除 null println(gsonIncludeNulls.toJson(User("Alice", 12, null))) // {"name":"Alice","age":12,"nickName":null} println(gsonExcludeNulls.toJson(User("Alice", 13, null))) // {"name":"Alice","age":13} - 用途:控制如何處理
null值,特別是在需要減少 JSON 大小時。
7. allowStructuredMapKeys
- 說明:如果設置為
true,允許使用複雜類型(例如,資料類)作為 Map 的鍵;否則僅允許基本類型作為鍵。 - 範例:
val json = Json { allowStructuredMapKeys = true } val data = json.encodeToString(mapOf(User("Alice", 25) to "Developer")) /* [ { "name": "Alice", "age": 25 }, "Developer" ] */ -
// Gson 不直接支持複雜類型作為 Map 的鍵。通常需要將 Map 鍵轉換為字串形式: data class User(val name: String, val age: Int) val gson = GsonBuilder().create() val map = mutableMapOf(gson.toJson(User("Alice", 25)) to "Developer") val jsonString = gson.toJson(map) // {"{\"name\":\"Alice\",\"age\":25}":"Developer"} -
// 使用 enableComplexMapKeySerialization 會有以意料之外結果 val gson = GsonBuilder() .enableComplexMapKeySerialization() .create() val map = mutableMapOf(User("Alice", 25) to "Developer") println(map) // {User(name=Alice, age=25)=Developer} println(gson.toJson(map)) // [[{"name":"Alice","age":25},"Developer"]] /* 當你使用 enableComplexMapKeySerialization() 時, Gson 允許序列化包含複雜對象(例如,自定義的 User 類型)作為鍵的 Map。默認情況下,Gson 只能處理字符串等基本類型作為鍵。 Gson 序列化 Map 時,會將鍵和值分別序列化。當使用複雜對象作為鍵時,Gson 會將這些鍵作為 JSON 的單獨條目來處理。 由於 User("Alice", 25) 是一個非基本類型對象,Gson 將其序列化為 {"name":"Alice","age":25}, 而 Map 的結果被序列化為包含鍵值對的數組。 當你打印 gson.toJson(map) 時,結果是 [[{"name":"Alice","age":25},"Developer"]], 這意味著 JSON 的輸出是一個數組,數組中包含了鍵和值的另一個數組。 這是因為 Gson 使用 List(一種數組結構)來表示 Map 的鍵值對,特別是在鍵是非基本類型的情況下。 */ val map = mutableMapOf(User("Alice", 25) to "Developer",User("John", 18) to "Student") println(map) // {User(name=Alice, age=25)=Developer, User(name=John, age=18)=Student} println(gson.toJson(map)) // [[{"name":"Alice","age":25},"Developer"],[{"name":"John","age":18},"Student"]] - 用途:用於需要使用複雜鍵的 JSON 結構。
8. allowSpecialFloatingPointValues
- 說明:如果設置為
true,允許特殊的浮點數值(例如,NaN、Infinity)在 JSON 中表示;如果為false,則會拋出錯誤。 - 範例:
val json = Json { allowSpecialFloatingPointValues = true } val data = json.encodeToString(Double.POSITIVE_INFINITY) // Infinity -
val gson = GsonBuilder() .registerTypeAdapter(Double::class.java, JsonSerializer<Double> { src, _, _ -> when { src.isNaN() || src.isInfinite() -> JsonPrimitive(src.toString()) else -> JsonPrimitive(src) } }) .registerTypeAdapter(Double::class.java, JsonDeserializer { json, _, _ -> when (val value = json.asString) { "NaN" -> Double.NaN "Infinity" -> Double.POSITIVE_INFINITY "-Infinity" -> Double.NEGATIVE_INFINITY else -> value.toDouble() } }) .create() - 用途:用於需要表示特殊浮點值的 JSON 序列化和反序列化。
如何混合使用這些配置
你可以將這些配置項混合使用來滿足特定的序列化和反序列化需求。
例如,假設你有一個情況需要反序列化非標準的 JSON 資料,並且需要忽略未知的鍵且保留結構化的 Map 鍵:
val json = Json {
prettyPrint = true
isLenient = true
ignoreUnknownKeys = true
encodeDefaults = false
explicitNulls = false
coerceInputValues = true
allowStructuredMapKeys = true
allowSpecialFloatingPointValues = true
}
val data = json.decodeFromString<User>("""{"name":"Alice", "unknownField":"value"}""")
println(data)
// User(name=Alice, age=30)
val gson = GsonBuilder()
.setPrettyPrinting()
.setLenient()
.serializeNulls() // Include nulls
.registerTypeAdapter(User::class.java, JsonDeserializer { json, _, _ ->
val jsonObject = json.asJsonObject
val name = if (jsonObject.has("name")) jsonObject["name"].asString else "DefaultName"
val age = if (jsonObject.has("age")) jsonObject["age"].asInt else 30 // Default value
User(name, age)
})
.create()
val jsonString = """{"name":"Alice","unknownField":"value"}"""
val user: User = gson.fromJson(jsonString, User::class.java)
println(user) //User(name=Alice, age=30)
println(gson.toJson(User("Alice")))
/*
{
"name": "Alice",
"age": 30
}
*/在這個例子中,我們結合了多種配置來實現靈活且容錯的 JSON 解析和輸出,確保代碼能夠應對多種 JSON 格式和數據問題。這樣的設置可以讓你的應用更加健壯和靈活。
json default value:
/**
* Configuration of the current [Json] instance available through [Json.configuration]
* and configured with [JsonBuilder] constructor.
*
* Can be used for debug purposes and for custom Json-specific serializers
* via [JsonEncoder] and [JsonDecoder].
*
* Standalone configuration object is meaningless and can nor be used outside the
* [Json], neither new [Json] instance can be created from it.
*
* Detailed description of each property is available in [JsonBuilder] class.
*/
public class JsonConfiguration @OptIn(ExperimentalSerializationApi::class) internal constructor(
public val encodeDefaults: Boolean = false,
public val ignoreUnknownKeys: Boolean = false,
public val isLenient: Boolean = false,
public val allowStructuredMapKeys: Boolean = false,
public val prettyPrint: Boolean = false,
public val explicitNulls: Boolean = true,
@ExperimentalSerializationApi
public val prettyPrintIndent: String = " ",
public val coerceInputValues: Boolean = false,
public val useArrayPolymorphism: Boolean = false,
public val classDiscriminator: String = "type",
public val allowSpecialFloatingPointValues: Boolean = false,
public val useAlternativeNames: Boolean = true,
@ExperimentalSerializationApi
public val namingStrategy: JsonNamingStrategy? = null,
@ExperimentalSerializationApi
public val decodeEnumsCaseInsensitive: Boolean = false,
@ExperimentalSerializationApi
public val allowTrailingComma: Boolean = false,
@ExperimentalSerializationApi
public val allowComments: Boolean = false,
@ExperimentalSerializationApi
@set:Deprecated(
"JsonConfiguration is not meant to be mutable, and will be made read-only in a future release. " +
"The `Json(from = ...) {}` copy builder should be used instead.",
level = DeprecationLevel.ERROR
)
public var classDiscriminatorMode: ClassDiscriminatorMode = ClassDiscriminatorMode.POLYMORPHIC,
) {
/** @suppress Dokka **/
@OptIn(ExperimentalSerializationApi::class)
override fun toString(): String {
return "JsonConfiguration(encodeDefaults=$encodeDefaults, ignoreUnknownKeys=$ignoreUnknownKeys, isLenient=$isLenient, " +
"allowStructuredMapKeys=$allowStructuredMapKeys, prettyPrint=$prettyPrint, explicitNulls=$explicitNulls, " +
"prettyPrintIndent='$prettyPrintIndent', coerceInputValues=$coerceInputValues, useArrayPolymorphism=$useArrayPolymorphism, " +
"classDiscriminator='$classDiscriminator', allowSpecialFloatingPointValues=$allowSpecialFloatingPointValues, " +
"useAlternativeNames=$useAlternativeNames, namingStrategy=$namingStrategy, decodeEnumsCaseInsensitive=$decodeEnumsCaseInsensitive, " +
"allowTrailingComma=$allowTrailingComma, allowComments=$allowComments, classDiscriminatorMode=$classDiscriminatorMode)"
}
}
5. 擴展性和客製化
在 JSON 序列化和反序列化過程中,kotlinx.serialization 和 Gson 都提供了強大的擴展性和客製化能力。這些能力允許開發者根據需要定義自定義的序列化和反序列化邏輯,以處理特殊格式的數據或滿足特定需求。
kotlinx.serialization 的擴展性和客製化
kotlinx.serialization 提供了一個簡潔的方式來自定義序列化和反序列化邏輯,通過實作 KSerializer 介面,你可以完全控制對象的序列化和反序列化過程。
如何實作自定義序列化器
-
定義資料類:
@Serializable data class Event(val name: String, @Serializable(with = DateSerializer::class) val date: Date)在這個例子中,
Event類的date屬性使用了自定義序列化器DateSerializer來處理Date類型。 -
實作
KSerializer介面:object DateSerializer : KSerializer<Date> { override val descriptor: SerialDescriptor = PrimitiveSerialDescriptor("Date", PrimitiveKind.STRING) override fun serialize(encoder: Encoder, value: Date) { // 自定義的序列化邏輯,將 Date 轉換為 String val dateFormat = SimpleDateFormat("yyyy-MM-dd") val dateString = dateFormat.format(value) encoder.encodeString(dateString) } override fun deserialize(decoder: Decoder): Date { // 自定義的反序列化邏輯,將 String 轉換為 Date val dateFormat = SimpleDateFormat("yyyy-MM-dd") val dateString = decoder.decodeString() return dateFormat.parse(dateString) } }在這個例子中:
serialize方法將Date對象序列化為String格式。deserialize方法將String反序列化為Date對象。
-
使用自定義序列化器:
val json = Json { } val event = Event("Conference", Date()) val jsonString = json.encodeToString(event) println(jsonString) // {"name":"Conference","date":"2024-08-29"} val deserializedEvent = json.decodeFromString<Event>(jsonString) println(deserializedEvent) // Event(name=Conference, date=Thu Aug 29 00:00:00 CST 2024)自定義序列化器
DateSerializer會自動在encodeToString和decodeFromString操作中被使用,處理Event類中的date屬性。
Gson 的擴展性和客製化
在 Gson 中,客製化序列化和反序列化是通過實作 JsonSerializer 和 JsonDeserializer 介面來實現的。這提供了類似的靈活性,可以完全控制對象的序列化和反序列化過程。
如何實作自定義序列化器和反序列化器
-
定義資料類:
data class Event(val name: String, val date: Date)與
kotlinx.serialization不同,Gson 並不需要在資料類上添加任何特別的註解。 -
實作
JsonSerializer和JsonDeserializer介面:val dateSerializer = JsonSerializer<Date> { src, _, _ -> // 自定義的序列化邏輯,將 Date 轉換為 String val dateFormat = SimpleDateFormat("yyyy-MM-dd") JsonPrimitive(dateFormat.format(src)) } val dateDeserializer = JsonDeserializer<Date> { json, _, _ -> // 自定義的反序列化邏輯,將 String 轉換為 Date val dateFormat = SimpleDateFormat("yyyy-MM-dd") dateFormat.parse(json.asString) }在這個例子中:
dateSerializer是一個JsonSerializer<Date>,負責將Date序列化為 JSON 字符串。dateDeserializer是一個JsonDeserializer<Date>,負責將 JSON 字符串反序列化為Date對象。
-
使用自定義序列化器和反序列化器:
val gson = GsonBuilder() .registerTypeAdapter(Date::class.java, dateSerializer) .registerTypeAdapter(Date::class.java, dateDeserializer) .create() val event = Event("Conference", Date()) val jsonString = gson.toJson(event) println(jsonString) // {"name":"Conference","date":"2024-08-29"} val deserializedEvent = gson.fromJson(jsonString, Event::class.java) println(deserializedEvent) // Event(name=Conference, date=Thu Aug 29 00:00:00 CST 2024)在這個例子中,
registerTypeAdapter方法用來註冊自定義的序列化器和反序列化器。Gson 會在序列化和反序列化Date類型時使用這些自定義的邏輯。
總結
-
kotlinx.serialization的擴展性和客製化:使用KSerializer介面來定義自定義的序列化和反序列化邏輯。這種方法能夠充分利用 Kotlin 的語言特性,如型別安全和編譯期檢查,確保序列化和反序列化過程中不會發生類型錯誤。 -
Gson 的擴展性和客製化:使用
JsonSerializer和JsonDeserializer介面來實現自定義的序列化和反序列化邏輯。Gson 的這種設計讓開發者可以非常靈活地處理各種數據格式和需求,特別是在 Java 環境中使用時。
這兩者都提供了足夠的靈活性來滿足大多數序列化和反序列化需求,不過 kotlinx.serialization 更加貼合 Kotlin 語言的特性和風格,而 Gson 則更加通用且適用於 Java 開發環境。
6. 依賴管理與體積
-
範例程式碼:
// kotlinx.serialization implementation "org.jetbrains.kotlinx:kotlinx-serialization-json:1.5.0" // Gson implementation 'com.google.code.gson:gson:2.9.0' -
kotlinx.serialization
-
依賴體積:
kotlinx.serialization是 Kotlin 官方提供的庫,專為 Kotlin 設計。這意味著它在體積上相對輕量,因為它不需要額外的依賴來運行 Kotlin 特性。它也不需要引入 Java 標準庫以外的額外依賴。 -
依賴管理:
kotlinx.serialization的版本更新和依賴管理與 Kotlin 生態系統的版本緊密相關。它由 JetBrains 官方維護,更新相對頻繁,且通常會與 Kotlin 編譯器的更新一起釋出,這意味著使用者需要隨時注意 Kotlin 版本的變化。 -
優勢:
- 與 Kotlin 無縫集成:
kotlinx.serialization是一個 Kotlin 原生庫,它與 Kotlin 語言特性(如 data class、sealed class)無縫集成。 - 輕量且效能優化:由於其緊密結合的 Kotlin 庫體積較小,並且效能優化專門針對 Kotlin 特性,這使得它在 Kotlin 開發中非常高效。
- 易於在多平台項目中使用:
kotlinx.serialization支持 Kotlin Multiplatform,因此它可以在同一套代碼中使用於 Android、iOS 和其他平台。
- 與 Kotlin 無縫集成:
-
劣勢:
- 僅適用於 Kotlin 項目:由於其與 Kotlin 的深度集成,如果你的項目是基於 Java 的,將不適合使用
kotlinx.serialization。
- 僅適用於 Kotlin 項目:由於其與 Kotlin 的深度集成,如果你的項目是基於 Java 的,將不適合使用
Gson
-
依賴體積:Gson 是一個通用的 Java 庫,設計用來支持各種 Java 對象的序列化和反序列化。由於它的廣泛兼容性和全面功能,Gson 的依賴體積相對較大,包含許多標準庫來處理各種情境。
-
依賴管理:Gson 是由 Google 開發和維護的開源項目,但它的更新頻率比
kotlinx.serialization要低。Gson 的版本變更通常是為了修復錯誤或增強功能,而不是頻繁的版本更新。 -
優勢:
- 廣泛的兼容性:作為一個 Java 庫,Gson 可以在任何 Java 環境中使用,包括 Kotlin 開發中。它可以處理 Java 的各種類型和情況,如泛型、嵌套類型等。
- 功能全面且穩定:Gson 在處理複雜 JSON 結構時非常靈活,並且提供了豐富的自定義擴展選項(如自定義序列化和反序列化)。
- 廣泛的社群支持:由於它的廣泛使用和成熟度,Gson 擁有大量的使用者和豐富的社群資源,許多常見問題和挑戰都有現成的解決方案。
-
劣勢:
- 較大的依賴體積:相比
kotlinx.serialization,Gson 的依賴更大,這可能會對應用的 APK 體積有影響,特別是在 Android 開發中。 - 較少的 Kotlin 特性支持:雖然 Gson 可以用於 Kotlin 項目,但它並沒有
kotlinx.serialization對 Kotlin 特性的原生支持,如sealed class和data class。
- 較大的依賴體積:相比
-
7. 社群與支援
- 簡短說明:
kotlinx.serialization有官方支持且定期更新,更適合與 Kotlin 生態系統一起使用;Gson 有更長的歷史和廣泛的使用者社群,但更新頻率較低。
8. 總結與建議
- 簡短說明: 根據項目的需要選擇適合的工具。對於需要與 Kotlin 深度集成的應用,建議使用
kotlinx.serialization;如果需要支持更廣泛的 Java 類型或已有 Gson 的基礎設施,可以選擇 Gson。
【Kotlin】【Test】建立臨時單一執行class
建立新的 Kotlin class: 在你的專案中,新增一個 Kotlin class,例如 TestApplication.kt。這個 class 會擔當你的測試入口點。
import org.springframework.boot.autoconfigure.SpringBootApplication
import org.springframework.boot.runApplication
@SpringBootApplication
class TestApplication
fun main(args: Array<String>) {
runApplication<TestApplication>(*args) // 如果不需起整個專案服務,可註解
// todo
println("start test")
}-
在這個例子中,
TestApplication是一個空的 Spring Boot 應用程式,使用@SpringBootApplication標註來指示它是 Spring Boot 的主應用程式。main函式是這個 class 的入口點,通過runApplication方法來啟動 Spring Boot 應用程式。 -
配置新的啟動 class: 如果你需要使用不同的配置或環境,可以在
application.properties或application.yml中設置相應的配置,或在需要時將其傳遞給runApplication的args參數中。 -
執行測試應用程式: 當你想執行這個測試應用程式時,可以直接運行
main函式所在的 Kotlin class,它將啟動並運行你的 Spring Boot 應用程式。
這種方式可以讓你在不影響原先 Spring Boot 應用程式啟動的情況下,新增一個單獨的測試入口點。
【IDE】【IntelliJ】
【intelliJ】intelliJ 下載
下載
社群版
https://www.jetbrains.com/idea/download/download-thanks.html?platform=mac&code=IIC
試用版
https://www.jetbrains.com/idea/download/download-thanks.html?gclid=CjwKCAiA_vKeBhAdEiwAFb_nrVM5GQ3UPJtj3kSXeg6jILdUAoOrhQTmSOvZFz_HxvLO-7UfYWqslBoCdZoQAvD_BwE
【IntelJ】auto import
【IntelIJ】用json建立data class
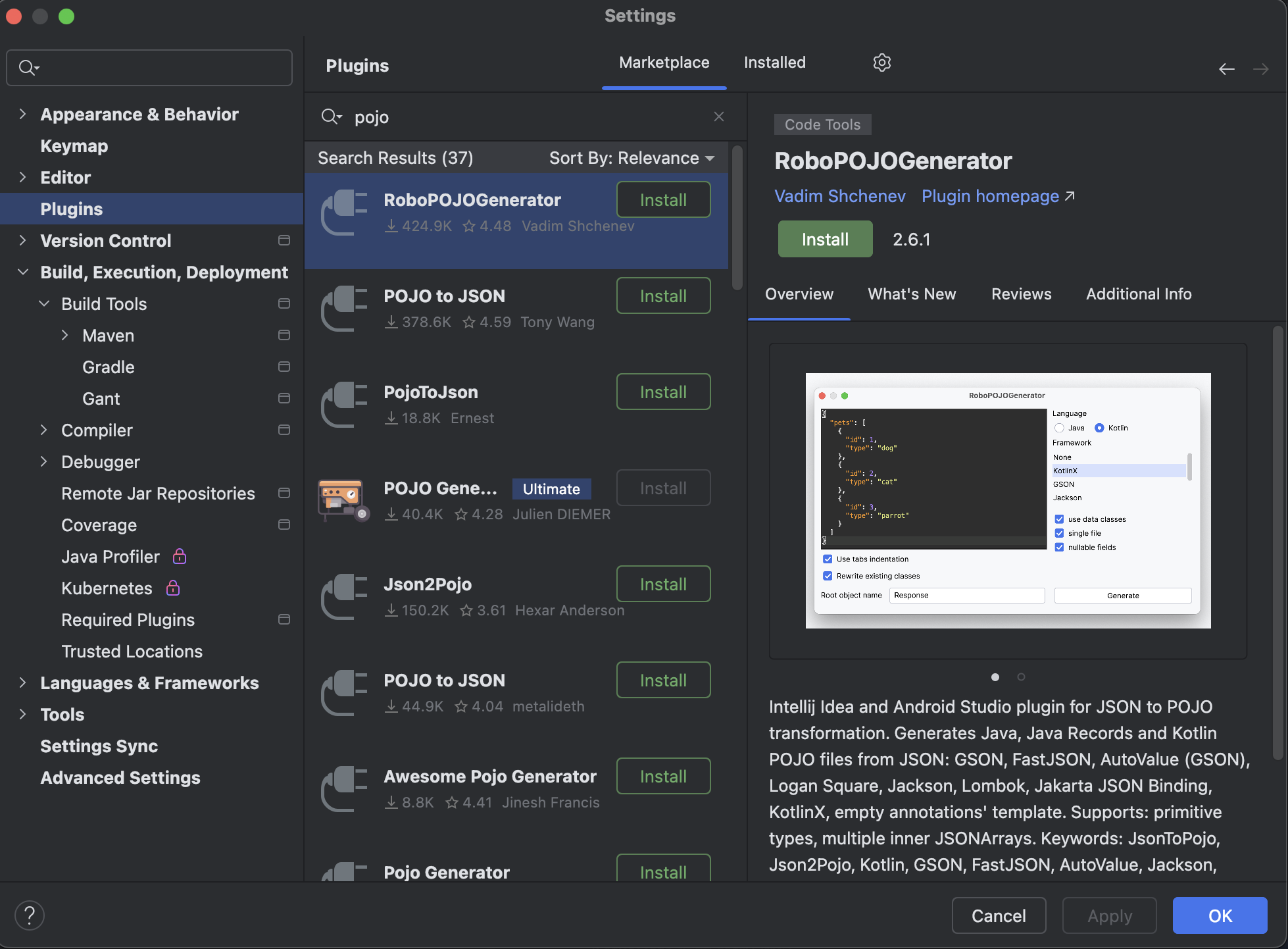
監控與效能調校
【性能分析工具】visualvm
官方說明
https://visualvm.github.io/documentation.html
使用 VisualVM 和 JProfiler 进行性能分析及调优
https://blog.csdn.net/wytocsdn/article/details/79258247
Util
TestController.kt
TestController.kt
@RestController
@RequestMapping("/api/test")
@CrossOrigin(origins = ["*"])
class TestController {
private val logger = LoggerFactory.getLogger(this::class.java)
@GetMapping("/test")
fun test(): String {
logger.info("TestController")
throw Exception("demo exception")
return "Hello World"
}
@PostMapping("/test")
fun testPost(@RequestBody test:Any?): ResponseEntity<Any>{
logger.info("test"+ test.toString())
return ResponseEntity.ok(test)
}
}JVM
【JVM】JPS教學
jps 是 Java 提供的一個工具,用於列出正在執行的 Java 進程。這個工具隨 Java 開發工具包(JDK)一起提供,通常用於監控和診斷 Java 應用程序。以下是 jps 的使用方式和一些常見選項。
基本用法
直接執行 jps 命令可以顯示當前用戶下正在執行的 Java 進程的簡單列表:
jps
這會輸出一個進程 ID 和 Java 類名,例如:
12345 MyApplication
67890 AnotherApp
常見選項
-
-l:顯示完整的類名或 JAR 路徑。jps -l輸出示例:
12345 com.example.MyApplication 67890 /path/to/AnotherApp.jar -
-v:顯示啟動 Java 進程時的 JVM 參數。jps -v輸出示例:
12345 MyApplication -Xms256m -Xmx512m 67890 AnotherApp -Dproperty=value -
-m:顯示傳遞給主類的參數。jps -m輸出示例:
12345 MyApplication arg1 arg2
查看特定主機的進程
如果需要查看其他主機上的 Java 進程,可以使用 jps 的 hostid 參數指定主機 ID,例如:
jps <hostid>
注意:此方法通常需要配置遠程連接。
常見用途
- 檢查是否有指定的 Java 應用在執行。
- 確認進程 ID(PID)以便進行進一步的診斷(例如
jstack或jmap等工具)。 - 快速查看進程的 JVM 參數或主程序參數。
小結
jps 是一個簡單但實用的工具,用於 Java 進程的快速概覽。配合其他 JVM 工具(如 jstack, jmap 等)使用,可以更有效地監控和診斷 Java 應用程序。
【JVM】jstat 教學
jstat 是 Java 提供的另一個工具,用於監控 Java 虛擬機(JVM)內存和垃圾回收狀況。這個工具對於監測和診斷 JVM 性能表現十分有用,特別是在優化內存使用和了解垃圾回收行為方面。以下是 jstat 的使用方式和一些常見的選項。
基本用法
jstat 的基本語法如下:
jstat [option] <pid> [interval] [count]
option:選擇要查看的統計信息類型。pid:要監控的 Java 進程的進程 ID(可以用jps查找)。interval(可選):更新統計信息的間隔時間(以毫秒為單位)。count(可選):輸出更新的次數。
常見選項
-
jstat -gc <pid>:顯示 JVM 垃圾回收相關的統計信息。jstat -gc <pid> 1000 5這會每隔 1000 毫秒(1 秒)更新一次垃圾回收的數據,共更新 5 次。輸出內容包含各個垃圾回收區的大小、使用情況,以及 YGC(年輕代垃圾回收)和 FGC(老年代垃圾回收)的次數等。
輸出示例:
S0C S1C S0U S1U EC EU OC OU MC MU CCSC CCSU YGC YGCT FGC FGCT GCT 512.0 512.0 0.0 0.0 4352.0 1234.0 10240.0 5678.0 2560.0 1900.5 224.0 150.0 5 0.345 1 0.654 1.0各列解釋:
S0C,S1C:第 0、1 Survivor 空間的容量(KB)。S0U,S1U:第 0、1 Survivor 空間的使用量(KB)。EC,EU:Eden 空間的容量和使用量。OC,OU:Old 空間的容量和使用量。MC,MU:元數據空間(Metaspace)的容量和使用量。CCSC,CCSU:壓縮類空間的容量和使用量。YGC,YGCT:年輕代 GC 的次數及時間。FGC,FGCT:老年代 GC 的次數及時間。GCT:總 GC 時間。
-
jstat -gcutil <pid>:顯示垃圾回收區的使用百分比。jstat -gcutil <pid> 1000 5這會顯示各個區域使用率的百分比,方便快速查看內存使用情況。
-
jstat -class <pid>:顯示加載類的統計數據。jstat -class <pid> 1000 5這會顯示 JVM 中類的加載數量、總字節數、卸載數量等。
-
jstat -compiler <pid>:顯示 JIT 編譯器的統計信息。jstat -compiler <pid> 1000 5這會顯示 JIT 編譯的次數和時間,有助於了解編譯行為的情況。
實用範例
-
查看特定進程的垃圾回收行為:
jstat -gc 12345 2000每隔 2 秒(2000 毫秒)更新一次數據,直到手動中斷。
-
查看特定進程的內存區域使用率百分比:
jstat -gcutil 12345 500 10每隔 0.5 秒更新一次,共更新 10 次。
小結
jstat 是一個高效且簡單的工具,可以讓開發者和運維人員更深入地了解 JVM 的內存使用和垃圾回收情況。在診斷性能瓶頸和內存相關問題時,jstat 是不可或缺的工具。